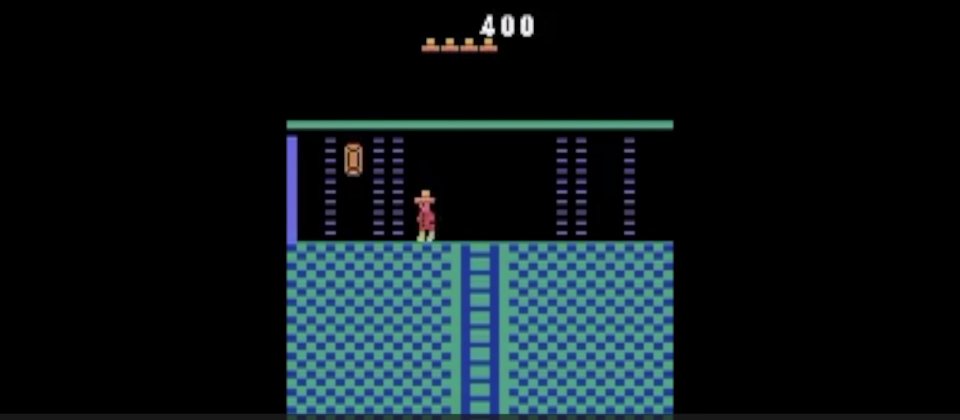
OpenAI發表了RND(Random Network Distillation),以基於預測的方法,透過好奇心帶領增強學習代理人探索環境。OpenAI提到,這是首次人工智慧遊玩「蒙特祖馬的復仇」(Montezuma’s Revenge)這款遊戲,能夠超過人類的平均表現,而且不需要人類示範,就能完成第一關。
OpenAI提到,要讓人工智慧代理人實現預設的目標,必須要使其探索環境中可能存在的內容以及完成目標的元素。不少遊戲的獎勵訊號都提供了一個課程(Curriculum),只要簡單的探索策略就可以實現遊戲目標,而之所以「蒙特祖馬的復仇」對於人工智慧是一個重要的指標,是因為在應用DQN演算法中,「蒙特祖馬的復仇」是唯一一款遠低於人類平均得分的遊戲,只使用簡單的探索策略,是無法在遊戲中收集到任何獎勵的,或是僅能探索遊戲世界24個房間的一小部分。
在2016年,OpenAI透過將DQN結合基於計數的探索獎勵,而使整體結果大幅前進,讓人工智慧代理人可以探索15個房間,最高獲得6.6K的分數,平均達3.7K,但從那之後,增強學習代理所獲得明顯的分數改進,都來自於人類專家的展示或是存取模擬器的基礎狀態。
而RND的發展,再次大幅推進了成果,讓人工智慧遊玩「蒙特祖馬的復仇」的分數正式超過人類,而且還能完整探索24個房間。OpenAI以1,024個Workers進行了大規模的RND實驗,在9次的實驗中平均分數達10K,最佳平均值達14.5K,每次實驗都能發現20到22個房間。另外,OpenAI還進行了一個較小規模但時間較長的實驗,人工智慧最佳分數達17.5K,通過第一級關卡並且探索完24個房間,OpenAI提到,這像是個好奇心的機制,可驅使人工智慧代理人發現新房間,並找到提高遊戲分數的方法。
這個好奇心的機制,OpenAI使用之前與柏克萊大學一同研發,以好奇心驅動學習的方法,代理人從經驗中學習下一個狀態的預測模型,並使用預測誤差作為內在獎勵。Google在不久前,發表了基於情境記憶模型,以提供增強學習獲得類似好奇心的獎勵以探索環境,擴展增強學習可以解決問題的範圍,Google提到,基於預測的內在獎勵機制,有機會讓代理人產生自我放縱獲取即時滿足感的現象。
OpenAI特別解釋,雖然基於預測的好奇心模型,在Unity的模擬迷宮中,的確會在電視機關中發生問題,透過不停預測隨機的電視頻道以獲得高內在獎勵,但是該演算法應用在「蒙特祖馬的復仇」這類大型確定性的環境仍是沒有問題的,好奇心會驅使代理人發現新房間,並且與物體互動。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09
