臉書
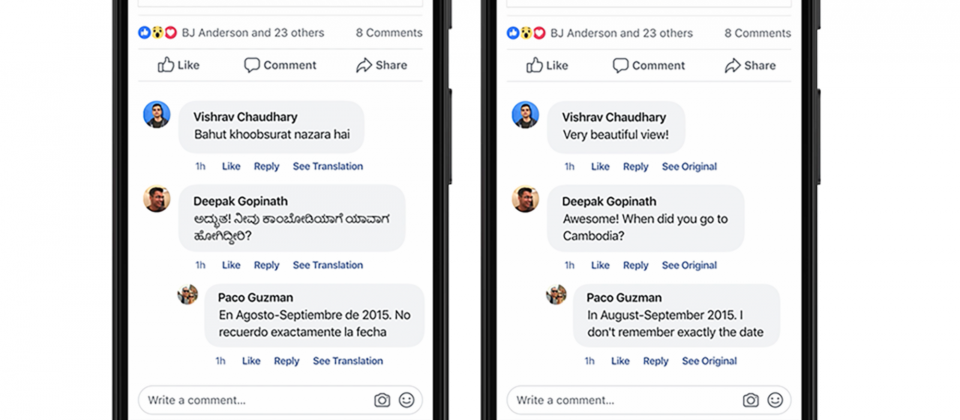
臉書現在以神經機器翻譯(Neural Machine Translation,NMT)技術,支援每天將近60億次翻譯服務,雖然臉書在使用神經網路後,比起傳統方法,翻譯模型的速度與品質有了大幅改進,但是技術終究遇到瓶頸,使他們無法再繼續增加翻譯的語言數量。
在2018年,臉書語言和翻譯技術(Language and Translation Technologies,LATTE)小組,決定進行改變,實現「沒有任何語言被遺棄」的目標,增加包括塞爾維亞、白俄羅斯及阿姆哈拉語等24種語言翻譯。而翻譯少數語言存在兩種挑戰,第一,這些語言缺乏訓練資源,可能沒有足夠現成人類翻譯的文本,第二個挑戰,他們需要找到能快速訓練系統,並產生可用翻譯的方法。
臉書主要採取了3個策略,來提高這些少數語言翻譯的BLEU分數(一種衡量機器翻譯準確性的方式)。第一個策略無可避免的還是需要增加訓練用標記資料,臉書的貼文和其他的文本非常不同,通常更短也更不正式,包含許多縮寫、俚語和拼寫錯誤。為了要讓演算法學會翻譯這些文字,需要先提供正確的學習範例,因此臉書抓取平臺上的公開貼文,請專業的翻譯人員進行手動標記。
臉書自動化抓取流程,自動選取並準備貼文,每周批次請不同的翻譯單位提供專業翻譯,總共為25種語言標記了數百萬個字。為了衡量有效性,臉書量測訓練前與訓練後的BLEU分數,發現15個語言平均上升了7.2 BLEU,每一萬個翻譯句子配對,能平均增加演算法翻譯品質1.5 BLEU。
除了增加域內標記資料外,第二個策略則是使用半監督的神經機器翻譯技術與資料增強方法,以生成額外的訓練資料。除了之前文章的提到的反向翻譯,為了訓練阿姆哈拉語到英語翻譯系統,臉書先訓練英語到阿姆哈拉語的基本翻譯系統,並用它將大量英語資料翻譯成阿姆哈拉語,把這些翻譯資料重新用作阿姆哈拉語到英語的訓練資料。這樣的方法在88%的情況下,平均提高了翻譯品質2.5 BLEU。
另外,臉書還用了另一個與反向翻譯概念類似的方法Copy-Target,意思是將目標翻譯語言的部分單詞換成來源語言,當要訓練英語翻譯至豪薩語系統,臉書會把部分對應的英語詞彙換成豪薩語,讓豪薩語翻譯至豪薩語,並把這些翻譯資料,做為英語翻譯至豪薩語系統,額外的訓練資料來源。在臉書的實驗中,88%的案例平均改善了2.7 BLEU。

但半監督式的方法有其缺點,其大量仰賴資料特徵,在資料不準確時便會為模型帶來干擾,臉書請了專業翻譯產生大量的翻譯資料,這讓翻譯模型翻譯臉書貼文的結果,變得不像社交媒體上會出現的句子,為此,臉書加入了社交媒體的訓練資料,並在訓練中複製了多個副本,增加對整體訓練資料的影響,以幫助產生更高品質的翻譯。臉書提到以反向翻譯加上Copy-Target方法為基礎,在100%的情況下社交媒體貼文修正,可使翻譯品質提高0.4 BLEU。
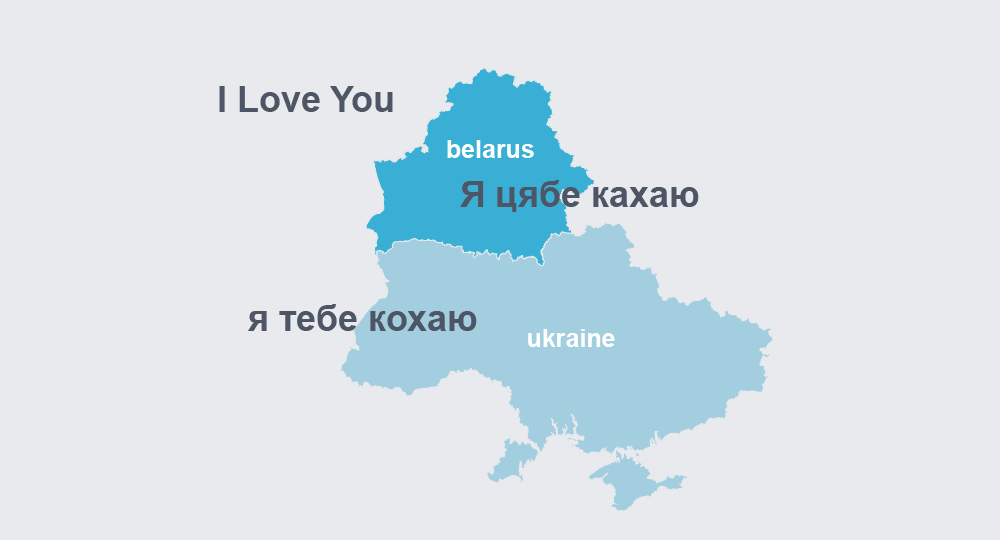
第三個策略,臉書發現多個方言之間有相關性,當把特定方言的翻譯方向,結合其他的翻譯方向,將比單純雙語互相翻譯的訓練方式成果還要好。臉書提到,他們為了改善從白俄羅斯語到英語的翻譯,利用了白俄羅斯語和烏克蘭語之間的關係,額外建立了一個多語言系統。經過實驗,多語言系統可以受惠同一語言家族的方言相似性,比起雙語翻譯基準,翻譯品質高了4.6 BLEU。
熱門新聞

2026-03-06

2026-03-02

2026-03-02

2026-03-04


2026-03-05

2026-03-06

2026-03-02