
OpenAI舉辦人工智慧轉移學習(Transfer Learning)比賽,採用整合了30款SEGA Mega Drive經典遊戲的Gym Retro平臺,參賽者將需要面對前所未見的關卡,以評估其強化學習演算法(Reinforcement Learning Algorithm)舉一反三的能力。
OpenAI表示,在典型的增強學習研究中,演算法經常一再的於相同環境中測試,而這樣不只讓演算法容易以記憶的方式取勝,開發者也可以調整出最適合的超級參數組。這次的經典遊戲大賽反其道而行,OpenAI會以音速小子系列遊戲的自訂義關卡,來測試參賽者的演算法。
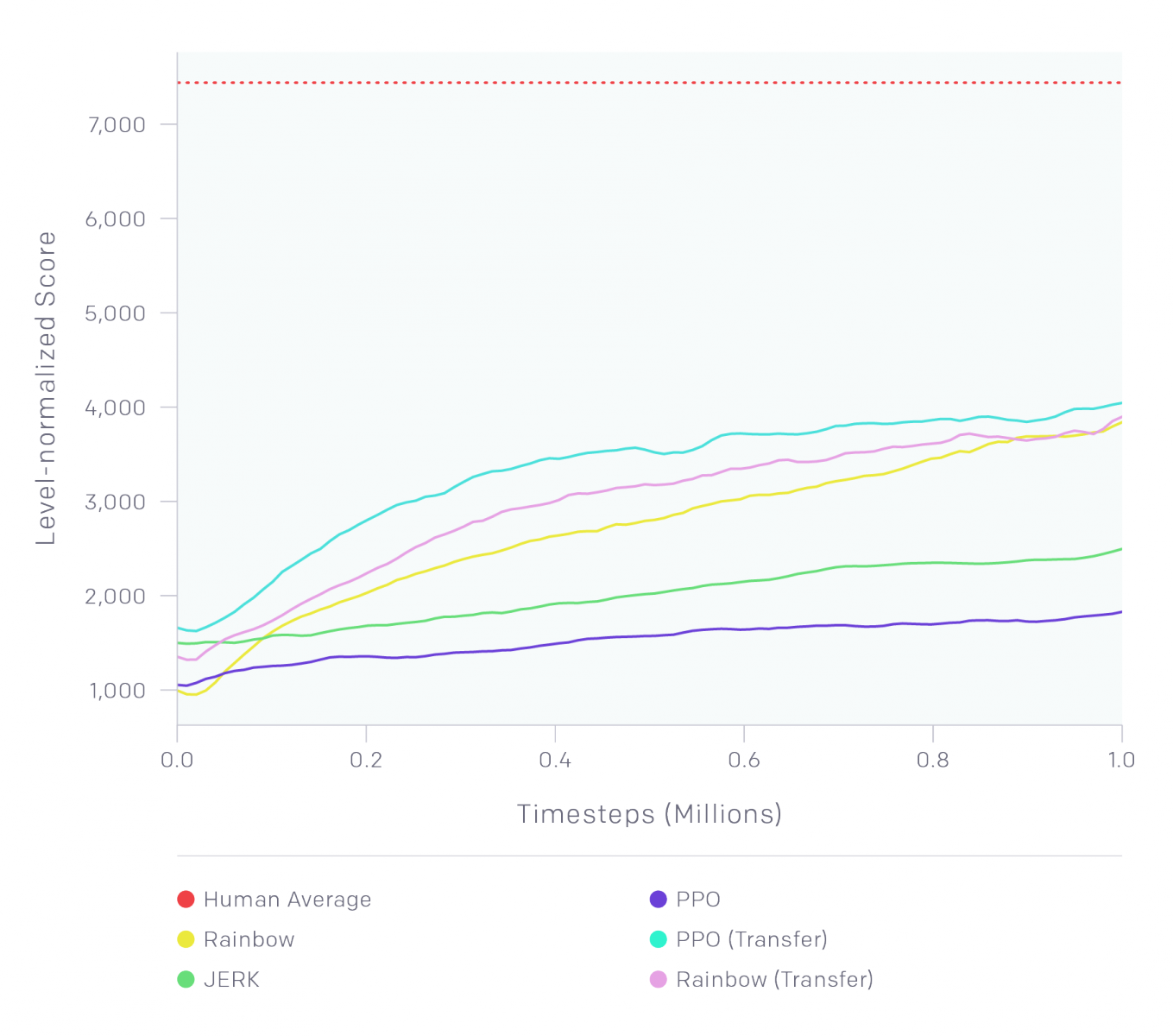
OpenAI釋出了經典基準(Retro-baselines),向參賽者展示增強學習演算法在遊戲關卡中的應用。而經典基準顯示,即使使用了轉移學習,增強學習演算法的學習能力還是遠低於人類,人類只玩1個小時的遊戲,其得分相當於演算法學習玩18個小時。
參賽者可以使用各種環境以及參數訓練演算法,但是實際比賽時,只能在官方準備好的全新關卡上遊玩18小時,約執行100萬步。OpenAI表示,18個小時看起來是一段很長的時間,但事實上得到的結果仍然差強人意。
(如下圖)這個經典基準測試中,提供了一些實驗結果給參賽者參考,內含Rainbow DQN、PPO以及簡單隨機猜測JERK等演算法的執行結果。他們發現,使用轉移學習的PPO演算法,可以大幅提升學習效能,甚至是其他演算法的兩倍。
而隨著比賽消息的釋出,他們也對外公布Gym Retro測試版,這是將經典遊戲包裝成增強學習環境的系統,其中包含來自SEGA Mega Drive的30款經典遊戲以及62款Atari 2600的遊戲。
在過去5年,Arcade一直是增強學習的主要測試環境,目的在於讓機器學習挑戰人類玩家的運動技能以及解決問題的能力。OpenAI表示,Gym Retro提供更為現代地控制臺介面,SEGA Mega Drive的遊戲也比Atari擁有更多層次,包括更多維度與玩法,藉此不只能擴大增強學習研究可用的遊戲數量,同時也能增加測試複雜性。在Gym Retro中,玩家可以直接透過JSON文件來控制關卡組成。
比賽將於4月5日至6月5日舉行,為期兩個月,而官方表示,獲獎者會得到非常酷的獎盃,期望開發者踴躍挑戰。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02