")
東南亞最大叫車服務平臺Grab每年超過10億的搭乘次數,叫車App每天需要處理數億筆的地理位置查詢請求,近日Grab資深工程師吳煒彬在臺揭露,如何讓搜尋平臺又快又準又穩定的背後技術關鍵。 (攝影/何維涓)
東南亞最大的叫車服務平臺Grab,和Uber、滴滴打車類似,主要的業務都是處理叫車服務,服務的範圍涵蓋全東南亞地區的國家,包含緬甸、泰國、越南、馬來西亞、新加坡和菲律賓等國的132個城市,共有180萬個司機。Grab在2012年才創立,在短短的幾年內,目前一年已經超過10億次的搭乘次數,不過,業務突然增長也為Grab帶來挑戰。
Grab資深工程師吳煒彬表示,由於叫車平臺需要用戶輸入起始點和終點的地理位置資訊,平臺每天大約需處理數億多個地理位置查詢請求,要如何提供毫秒級的查詢服務,還要兼顧搜尋結果的準確性,是Grab服務爆紅後最大的難題。
Grab在2013年時決定導入這個知名的開源搜尋工具Elasticsearch,來因應多種資料查詢和Log追蹤的需求。在Grab團隊中,一手包辦所有Elasticsearch叢集管理工作的吳煒彬,他解釋,當時為了方便保存和搜尋MySQL的稽核Log日誌檔。原本所有MySQL資料庫中的變動都儲存在文字格式的Log檔中,管理不易,更難以追蹤。於是,Grab改將Log記錄寫入Elasticsearch中儲存,透過Elasticsearch,可以搜尋MySQL的每一次存取,每個欄位的任一項數值異動。
Elasticsearch是荷蘭一位開發者Shay Banon在2010年推出的的開源分散式搜尋分析系統,使用Apache Lucene來儲存JSON文件,也可提供全文搜尋的功能。因為Elasticsearch具有高可擴充性(Scalability)與可用性(Availability)的特質,再加上資料處理效能高,許多企業都採用了Elasticsearch,就連維基百科、GitHub、英國衛報、Stackoverflow等網站,都用Elasticsearch來處理內容搜尋與資料處理分析的工作。
吳煒彬表示,保存Log記錄是Elasticsearch常見的應用方式,透過Elasticsearch來儲存Log檔,有助於用可視化的形式來呈現Log搜尋的結果,不過,Grab不僅用Elasticsearch來儲存Log檔,後來,更進一步透過Elasticsearch來搜尋叫車服務的熱門地點(POI,Point of interest)。這是叫車服務中,影響車輛調度效率,最關鍵的參考資訊。
在叫車服務中,設定路線是影響用戶體驗的第一個關鍵,用戶打開Grab叫車App後,需輸入用戶姓名、地址和附近建築物的類型等,再透過搜尋欄位來輸入上下車的位置。
Grab提供了3種搜尋方式,第一種是就近搜尋,也就是當用戶打開App後,會自動偵測用戶所在位置,透過詢問的方式與用戶確認上車位置,第二種則是以用戶地理位置為基礎的文字搜尋,透過用戶輸入的地址來搜尋出發地和目的地。
第三種搜尋方式比較特別,若用戶不知道自己所在的位置,可以透過逆向搜尋的方式來搜尋上車地址,舉例來說,用戶可以輸入附近的商店、鄰近的街道名稱,並透過地圖將自己的位置定位出來,就能找到用戶目前所在的位置。
來自132國的Grab用戶,每天透過App查詢地點來叫車的地理資料查詢次數,累計多達數億次,這是叫車App中最常用的第一項功能。為了簡化用戶輸入過程,不論用哪一種搜尋方式,叫車App都會提供相關地點選單,推薦10~30個地址或地點的清單,讓用戶點選,來簡化輸入過程,也能減少對後端系統的負擔。
根據不同業務場景,訂製出合適的搜尋策略
由於Grab叫車服務遍及東南亞各國,吳煒彬指出,用戶所用語言和地址資訊也有很大的差異,因此,Grab得根據不同國家的用語特色和慣用地址描述方式,來客製每個國家的搜尋機制。
尤其,「語言的分詞機制會影響了龐大地理位置搜尋任務的效率,」吳煒彬表示,東南亞的語言,每個單詞都是連在一起的,不像英文每個單詞中間會有空格,因此,系統必須分析整個句子,才能根據語法,正確解析每一句的意思,Grab為了解決語言的問題,創造多個不同的語言分析器,將索引的方式分成不同的版本。
不過,「Elasticsearch跟一般資料庫不同的是,Elasticsearch使用逆向索引(Inverted index)的機制!」吳煒彬解釋,一般的正向索引每一行就是一筆資料,每一列就是該筆資料不同的屬性,Elasticsearch則是完全相反,每一行是屬性,而每一列是一個Host,Host中有單筆資料的編號(Document id)。
簡單來說,Elasticsearch在寫入3筆地址資料時,會先根據分詞萃取出文字(Term),在合併(Merge)之後,比對出每個文字重複出現在那些資料編號中,並將該資訊記錄下來。
舉例來說,編號1的資料只有Grab辦公室的名稱,編號2資料則是Grab辦公室的地址,編號3資料包含Grab辦公室名稱和經緯度,因此 3筆資料同時被寫入Elasticsearch時,Elasticsearch會先合併,將相同的關鍵字提出來,因此,用戶搜尋Grab時,Elasticsearch就能快速搜尋到與Grab關鍵字相關的資料編號,並將搜尋到的結果提供給用戶。
也因此,Elasticsearch逆向索引的特性,讓Grab每天面對數億筆查詢的服務量,可以提供用戶毫秒級的查詢服務,但是,只有速度還不夠,Grab還要解決另一個挑戰是查詢結果的準確性。
提高搜尋準確度的關鍵:評分系統搭配權重機制
為了因應不同的業務場景,Grab在用戶搜尋地理位置的過程中,加入權重的機制,將不同的搜尋關鍵字,依照業務場景來調整,透過該評分系統,提供更準確的搜尋結果。
在用戶輸入搜尋的文字後,系統會透過比對關鍵字與資料庫裡的每筆資料的相對應程度,像是10個字元中,有幾個字元相同,或是這個關鍵字出現的次數,綜合以上結果,算出一個分數再乘以不同的權重,最後,每個鍵值(Key-value)的資料欄位都會有一個分數,系統再選擇前10或是20得分高的結果,提供給用戶。
而不同國家的地址資訊也會有不同的特色,吳煒彬指出,郵遞區號在越南不太明確也較少人使用,但是,在新加坡每棟建築物都有不同的郵遞區號,因此,根據郵遞區號就能找到非常準確的地理位置。
由於不同國家地址資訊的差異,Grab調整搜尋的策略,加入了權重的機制,若用戶在越南用郵遞區號搜尋,系統則會忽略該欄位,將郵遞區號搜尋的權重調整到最低,但是在新加坡,系統就會將郵遞區號的搜尋權重調整到最高。
吳煒彬認為,加入權重的機制,還能夠讓大範圍的搜尋也不會出錯,他舉例,用戶搜尋臺北時,臺北101和一家位於九份名為臺北牛肉麵商店,相關度的分數會相同,但是加入權重機制,可以考慮其他資料欄位的得分,因為臺北101的地址欄位也會含有臺北的字元,因此綜合計算分數後,臺北101的得分會比九份的臺北牛肉麵高。
另外,Grab也採用邊緣語言模型Edge NGRAM分析器,來預測用戶輸入的行為,在用戶輸入的過程中,當用戶輸入兩個字元,系統就會提供用戶相關的字。
以「Cecil office」為例,Grab將最小邊緣和最大邊緣定義為2和8個位元,也就是說,從2個位元到8個位元先總共儲存了7個索引,因此,在用戶輸入「Ce」兩個字元時,系統就會開始出現相關的索引結果, 若使用者輸入的字元越多,得到的結果也會越正確。
建立資料庫的監控和警示系統,確保服務不中斷
除了查詢地理位置速度要快,搜尋結果又要準確之外,Grab億級搜尋平臺的第三個挑戰是,服務更不能中斷,吳煒彬表示,開源版本的Elasticsearch並沒有提供監控和警示的功能,於是,Grab用Go語言開發一套Elasticsearch Proxy系統,來擷取所有https的請求資訊,包括來源IP位址、回應時間、查詢內容等,將這些Log檔儲存下來後,可加入其他Log分析系統,像是Scalyr,或是用Elasticsearch 提供的Log收集分析平臺Elk(Elasticsearch、Logstash、Kibana的簡稱)。
但是,擁有監控的機制還不夠,由於Elasticsearch去中心化叢集的特性,會造成當程式指定接收查詢的伺服器不能運作,服務就會有癱瘓的風險,在Elasticsearch運作機制中,每一個伺服器是一個節點,由多個伺服器組成叢集,每一臺伺服器同時有3個角色:Masternode、Datanode和用來解析Log的Ingestnode,每臺伺服器都可以接受查詢請求,接收到查詢請求的伺服器,會透過搜尋叢集的資訊,將需要查詢的資訊發送到相對應的伺服器上,每一臺伺服器都會將查詢執行一遍,得到結果後,再將結果回傳給接收請求的伺服器,最後,由接收請求的伺服器將所有查詢結果排序後,回送給用戶查詢結果。
為了避開指定伺服器運作影響服務的風險,Grab採用輪替式DNS(DNS round robin)的機制,透過DNS主機設定多組IP,來分散風險之外,還能達到負載平衡,讓每臺伺服器都能輪流接收查詢請求,因為整合查詢結果的工作,需要消耗CPU資源,輪替的方式可以確保資源消耗不會集中在單一一臺伺服器上。
不過,吳煒彬坦言,這個作法會衍生一個問題,若其中有一臺伺服器當機了,DNS主機不會得知,仍舊會將查詢請求送至這臺當機的伺服器,就無法回傳查詢結果,他推算,約80%的查詢可以成功,但有20%失效的風險。
為了解決這個問題,Grab用AWS 的Elasticsearch服務所提供的心跳查詢功能,檢測每一臺伺服器的健康程度,若與某一臺伺服器的心跳查詢失敗,DNS主機就不會將請求發送至該伺服器。
心跳查詢解決了2成失效的風險,但又產生了另一個問題,吳煒彬補充,由於Elasticsearch去中心化叢集的特性,一臺伺服器同時是Master和Slave,若某一臺伺服器的Datanode查詢,占了大部分的CPU和記憶體資源,就會影響到Masternode 的使用,Masternode無法執行心跳查詢,確保伺服器的健康狀況,可能導致服務中斷。
後來,Grab決定將Masternode獨立出來,作為Masternode的伺服器不 需要太多儲存空間,也不需要高效能的CPU和記憶體,只需要管理叢集的資訊,並即時反饋ELB心跳查詢的結果,而Datanode因為要處理查詢請求,需要比較高效能的CPU和記憶體,以及儲存資源。
Grab在Elasticsearch的部署上,一開始自行用開源的程式建立部署,後來因為監控和警示的功能,採用了AWS提供的Elasticsearch服務,監控的功能整合到Cloudwatch上,較方便監控。
不過,吳煒彬指出,AWS的Elasticsearch服務為了方便管理,禁用了Endpoint,且用戶權限管理系統也不完善,若企業要在叢集中加入新的用戶權限,假設整個叢集有10個節點,AWS的作法是先建立10個新節點,並將原來10個節點的數據,發送到新的節點上,但是,「數據遷移時,容易對原來的叢集產生性能上的影響。」他說。
Grab最終採用了Elasticsearch的企業版本,原因是Elasticsearch的企業版本涵蓋了AWS上所提供的功能,也提供商業化的插件(Plug-in),像是監控和警示的功能,另外,企業版提供用戶權限管理系統,增加新的用戶權限,不需要經過數據遷移。
「以前是透過查詢找數據,現在可以透過數據來找查詢!」吳煒彬表示,未來,Grab還預計透過真實數據來驗證每一條查詢規則的關係,進而分析更複雜的用戶行為,針對個人推出客製化的銷售策略,舉例來說,若某一個時段的一個路線有許多查詢,代表這些查詢之間是競爭的關係,因此,Grab就能在叫車的尖峰時段提供收費,或是也能透過用戶查詢搭車路線的規則,將用戶分類成通勤族、遊客等不同類別的用戶,推出適合用戶行為的優惠方案。
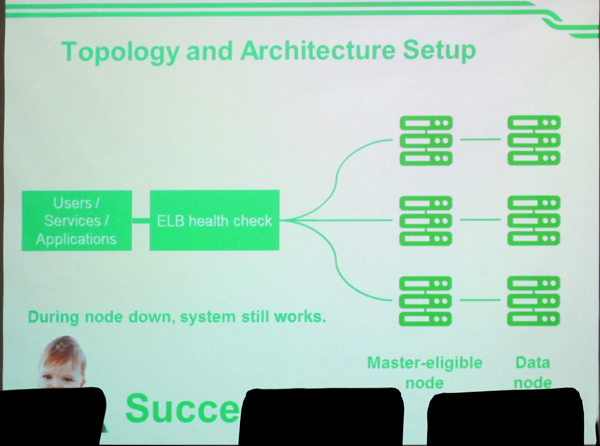
Grab為了解決同一臺伺服器可能因為查詢占用大部分的資源,而影響心跳查詢效能,決定將Masternode獨立出來,由Masternode負責管理叢集的資訊,並即時反饋ELB心跳查詢的結果。
攝影/何維涓
熱門新聞

2026-03-06


2026-03-11




2026-03-06
2026-03-10