
小米研發架構師歐陽辰認為,數據分析處理是個無底洞,「需求是源源不盡的。」企業對於即時性、靈活性的需求越來越多,「系統要設計成支援串流分析的架構,每天產生報表的時代已經過去。
iThome
首次來到臺北的小米研發架構師歐陽辰,看見城市中川流不息的摩托車車流,引起了他的注意:「它的特色很像大數據」,除了數量多、變化快,以及難以預測動向,摩托車也和大數據一般,都是解決人類生活在社會中的一項工具,「未來大數據會是重要的社會基礎架構,就像水、電力一樣。」
談起大數據,不免回歸最基本的問題:它跟傳統數據分析的區隔為何。
歐陽辰表示:「在目標上,我認為兩者沒有區隔」,歐陽辰表示,傳統統計分析解決的問題如人口統計議題,只需要經過隨機抽樣方法就能解決。但是碰上投放商業廣告,若仍靠傳統抽樣分析結果,作為播放廣告的判斷標準,容易產生不佳的使用者體驗,也因此,企業對於大數據的需求油然而生,通盤分析、統計手中握有的原始資料,「這才是大數據所要解決的問題。」
歐陽辰也揭露了小米大數據技術框架,其中開源解決方案占了相當比例。在最底層的資料收集系統,小米導入開源專案Scribe,可以用於整合即時的Log資料,並且根據系統使用量,進行水平擴充。
而資料儲存系統中,主要由Hadoop分散式檔案系統HDFS,以及開源的非關聯式資料庫HBase所組成,兩者分別有各自的優點。歐陽辰表示,HDFS比較適合用於批次儲存,而Hbase則較擅長隨機存取。在2015年時,小米也引入了由Cloudera釋出的開源專案Kudu,其特性則介於兩者之間。在資料分析層中,則是導入了MapReduce、Spark、Storm等開源專案。
靠大數據統計平臺支援其他業務
目前小米除了手機、電視等硬體產品,也跨足了廣告行銷、線上金融服務等領域,而且每日活躍人數破千萬的App就有超過20款,包含小米瀏覽器、小米音樂等應用程式。
歐陽辰表示,為了協助事業體內其他部門的營運,這些App的背後,都是透過小米自家開發的大數據即時分析平臺小米統計,來提供DAU、視覺化分析等圖表。藉由每款App的使用族群的分析結果,「區隔用戶的喜好,幫助使用者找到更適合的App。」
採雙資料流Lambda架構
而小米統計1.0版本的架構,則是採用雙資料流Lambda架構,混合使用Kafka、Storm、HDFS以及Spark等元件,分流進行即時資料分析,以及批次資料處理。歐陽辰表示,此平臺所應付的資料規模高達數十TB,每秒要處理20萬個請求,目前已經累積了數百億個系統事件。
在使用者透過終端裝置發送需求後,首先透過Linux虛擬伺服器(Linux Virtual Server,LVS)以及網站伺服器Nginx,作為負載平衡器。
其中,所有資訊都是經由已經加密的Htttps協定傳輸,歐陽辰表示,為了減緩CPU使用資源、減少運算叢集數目,小米也會一同搭配SSL加速器,增加檔案傳輸的效率。
在資料通過Nginx之後,接著,則交由小米統計的前端伺服器,分別將資料進行分流:即時分析及批次儲存。
在資料即時分析的路徑中,「得將所有系統事件進行串流處理。」通過前端伺服器後,資料流則引入Kafka中,接續透過Storm分析處理,產出每日活躍使用人數等資訊。歐陽辰表示,除了即時分析,此路徑也會產生部分資料,交給Spark及MapReduce,進行批次儲存程序處理。
而Lambda架構的第二條分支,則是負責批次處理程序,在此分支中,前端伺服器首先將系統Log紀錄傳送至Scribe,後續Scribe則將資料寫入至HDFS中。經過4小時,系統將驅動預先設置的MapReduce、Spark腳本,進一步進行批次處理,並且將統計結果寫入至HBase及NoSQL。
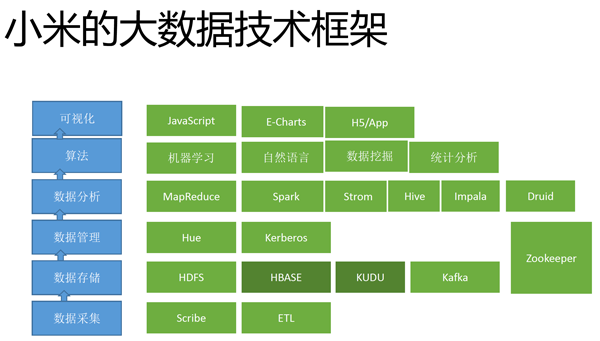
小米大數據技術框架中開源解決方案占了相當比例。在最底層的資料收集系統,小米導入開源專案Scribe,可以用於整合即時的Log資料。資料儲存系統中,主要由Hadoop分散式檔案系統HDFS,以及開源非關聯式資料庫HBase所組成。圖片來源/小米
小米統計1.0的資料處理能力仍不夠
在使用小米統計1.0平臺後,歐陽辰也發現了許多不足之處。首先在Lambda架構資料分流的設計下,由於資料量大,「很多即時分析系統產出的結果,應該要傳給批次處理系統使用,減少計算量」,只要能提升百分之一或二的效能,都值得投資。
靠Spark及MapReduce雙引擎處理不同批次任務
再者,批次處理系統中,目前小米引入Spark及MapReduce作為核心元件。他表示,雖然普遍認為Spark的運作必然較順暢,但當資料成長至一定規模,除了相當耗費記憶體外,即使建立許多Spark叢集,也很容易將儲存空間占滿,「根本無法運作Spark。」後來歐陽辰也發現較有效的運作模式:使用者可將簡單的任務交給MapReduce,複雜任務則由Spark進行運算,「兩者各有自己的特色。」
第三則是讓系統能支援即時串流運算,他表示,過去業界僅需要按天為單位,產生統計結果。但是即時運算需求,在過去幾年中成長飛快,「使用者對於它有無止盡的需求」,想要隨時都能查詢結果。
最後則是檔案格式擁有許多不同標準,像是某些使用者想使用SQL指令查詢資料,「但資料不是儲存在MySQL架構中,對我們產生許多挑戰。」
推小米統計2.0,加強即時分析功能
因應這些挑戰,歐陽辰也重新設計了系統架構,推出了小米統計2.0平臺,新架構仍然採取Lambda的分流架構,但是分別加入了2個新個開源元件:即時資料分析系統Druid以及SQL資料庫Crate.io。
歐陽辰表示,Druid的運作邏輯與Storm不大一致。像是小米統計平臺中,提供使用者不同條件選項,如自訂時間區間、應用程式版本等條件,「進行以秒為單位的即時查詢。」
此功能利用Storm實作時,每當開發者新增一個篩選條件,就必須更改程式碼。而透過Druid,只需要撰寫組態設定檔,讓Kafka根據開發者需求分類資料。「Druid是為分析而生的軟體,程式碼數量很少」,他表示,在使用者定義資料篩選條件後,Druid就會自動地分類資料。而它也有處理TB級資料的能力,「只需用幾臺伺服器就可以搞定,效率非常高。」歐陽辰說。
再者是Crate.io,他表示,此元件水平擴充能力的效能不錯,也可以架設多個儲存節點。雖然Crate.io將新資料加入資料表的性能並不突出,但可用於儲存使用頻率不高的資料。反而Crate.io提供SQL查詢功能為一個亮點,「查詢功能必須要提供使用足夠的靈活度。」
歐陽辰也總結設計小米統計的心得。他表示,數據分析處理是個無底洞,「需求是源源不盡的。」企業對於即時性、靈活性的需求越來越多,「系統要設計成支援串流分析的架構,每天產生報表的時代已經過去。」
此外,與其提供使用者僵固、不易更改的查詢介面,不如讓使用者根據需求,自行打造資料查詢工具。
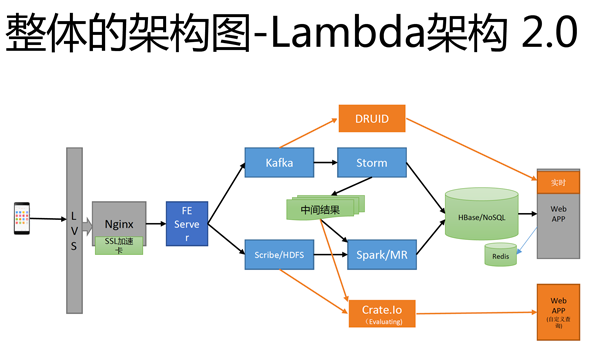
歐陽辰重新設計系統架構,推出了小米統計2.0平臺,仍然採取Lambda的分流架構,但是分別加入了2個新個開源元件:即時資料分析系統Druid以及SQL資料庫Crate.io。圖片來源/小米
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-02

2026-03-05