臉書(Facebook)希望讓每個人都能上網的願景不僅限於協助貧困者能夠免費或低價上網,還包括讓難以瀏覽網頁內容的視障者,也能夠透過影像辨識技術,知道網路上的各種影像到底是甚麼面貌。
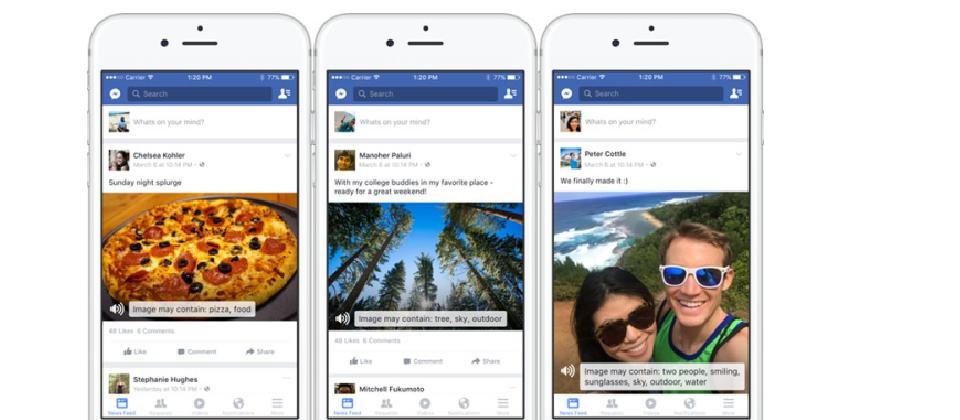
Facebook在周二推出新服務,automatic alternative text,結合人工智慧(AI)及影像辨識技術,分析臉書上的照片存在那些物件,透過外加的文字描述告知視障者照片內容。舉例來說,描述的文字會向視障者說明「這張照片中有兩個人,它們正在微笑」或是當臉書親友分享晚餐享用Pizza的照片時,說明「照片中有食物、Pizza」等類似的口述。
Facebook強調這項技術仍在發展中,現在已能辨識80種物品或活動,並將隨著人工智慧系統接觸更多照片,進而提升其辨識能力。
目前能辨識的物品類別包括運輸、環境、運動、食物,以及特定外型/情境。舉例來說,運輸類別能夠辨識出汽車、飛機、船舶、火車、腳踏車、道路、摩托車、公共汽車等;而特定外型與情境則可辨識出嬰兒、眼鏡、鬍子、微笑、珠寶、鞋子與自拍照等。
發展出此項技術的工程師Matt King本身就是因為色素性視網膜炎導致失明的視障者,他表示,Facebook的許多特色都與視覺有關,身為視障者,那種被排除在外的感覺特別強烈。儘管這個計畫仍在發展初期階段,但長期而言這有助於讓每一個個人,都有機會加入彼此的對話,不會被排除在外。
目前這項功能只適用於透過screen reader瀏覽Facebook的iOS用戶,而且僅提供美國、英國、加拿大、澳洲等地英文地區使用。未來會增加其他裝置平台、支援更多的語言及市場。
台灣也有團體與企業發展類似技術,例如盲用點字顯示器、視窗導盲鼠等,但隨著網路上的影像內容愈來愈多,也讓以文字為主要使用媒介的視障者不容易跟上新的網路服務。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-02-26

2026-03-02
%3A \">圖片來源/Novee</a>")
2026-03-02