Cloudian
隨著AI訓練資料量的持續增加,也讓從儲存裝置向GPU伺服器傳輸資料的效率,成為影響AI應用整體效能的關鍵環節。
為改善GPU伺服器的資料傳輸效率,Nvidia推出的GPUDirect Storage(GDS)架構,藉由提供儲存裝置向GPU直連傳輸資料的方法,儼然成為AI應用的資料傳輸標準架構,截至目前為止已獲得超過15家廠商,近20種儲存平臺支援。
但GDS架構也存在一大限制——僅在檔案系統層級上運作,這也導致廣大的物件(Object)儲存系統被排除在GDS架構外。這也成為我們這幾年來觀察GDS相關議題時,一直存在的疑問,由於Nvidia官方始終未將GDS支援範圍擴展到物件儲存領域,以致物件儲存因缺乏對GPU直連傳輸架構的支援,在AI儲存應用陷於劣勢。
近幾個月來,這個問題總算開始獲得改善,在MinIO、Cloudian、DDN等廠商的努力下,開創出適用於物件儲存的GPU直連傳輸架構。
克服物件儲存的AI應用困境
歷經十多年發展後,物件儲存在非結構化資料儲存應用的各個領域,都已能與歷史更悠久的檔案儲存設備分庭抗禮,甚至猶有過之,例如在規模越大的應用情境中,物件儲存設備能憑藉近乎無限的擴展能力,較檔案儲存設備更占有優勢。而對於強調資料搜尋、檢索的儲存應用,物件儲存也能憑藉更豐富、彈性的metadata屬性,提供更高效的管理能力。
然而在以GPU運算為核心的AI儲存應用中,物件儲存設備卻遇上阻礙——由於物件儲存設備未獲得Nvidia的GPU直連傳輸架構支援,以致限制在AI儲存應用的傳輸效能表現。這也促使物件儲存廠商自行發展出同類的GPU直連傳輸架構,以克服物件儲存平臺在AI傳輸面臨的束縛。
我們在今年1月的封面故事《2025 AI資料傳輸架構新進展》,曾初步介紹物件儲存廠商這方面的努力成果。時隔兩個月的此刻,又有更多廠商投入這個領域,進一步擴大物件儲存的GPU直連傳輸應用生態系。
AI應用必備的GPU直連傳輸架構
GDS這種直連傳輸架構的基本目的,是在儲存裝置與GPU之間,建立直接記憶體存取(Direct Memory Access,DMA),讓資料傳輸路徑繞開主機CPU記憶體回彈緩衝區(Bounce Buffer)的中介,允許儲存裝置直接將資料傳輸載入GPU記憶體,藉此免除不必要的資料複製作業,並避開因主機CPU導致的效能瓶頸,獲得減少存取延遲、減輕主機CPU負荷、提高傳輸頻寬等效益。
但GDS對儲存裝置的存取,是在檔案系統層級上進行,這也成為GDS應用的限制。
GDS能支援GPU伺服器本機的SSD,以及外部掛載的區塊儲存設備、還有網路附加儲存設備(即NAS),但無論何種類型,最終都是以檔案系統形式為GDS存取。本機SSD與外部掛載的區塊儲存區(Volume),都須格式化為EXT4或XFS檔案系統形式,再掛載給GPU伺服器使用。而相容於GDS的網路附加儲存設備,則是透過修改的NFS協定(NFS over RDMA)或InfiniBand介面,來建立GDS存取。
這也意味著,透過S3、Swift、REST、HTTP等物件傳輸協定來存取資料的物件儲存設備,不相容於GDS架構,所以,也無法獲得GDS提供的GPU直連傳輸效益。
為物件儲存建立GPU直連傳輸
藉由堆疊大量儲存節點,以及採用高頻寬的傳輸介面(如400GbE),物件儲存設備在AI應用環境中,依然可以提供相當高的傳輸頻寬,但由於不支援GDS的GPU直連傳輸,所以物件儲存設備向GPU伺服器傳輸資料時,資料傳輸路經必須經由主機CPU與記憶體的中介,導致明顯更長的存取延遲,並給主機CPU帶來更大負荷,進而影響到整體效率。
在CPU低負載的情況下,是否使用GPU直連傳輸,對資料傳輸率與存取延遲的影響,大約只有20%到30%的差異。真正的挑戰在於:CPU處於高負載的情況下,此時是否採用繞過CPU的GPU直連傳輸,對傳輸效能與延遲的影響,差距將會高達數倍之多。
要讓物件儲存設備避開前述限制,與GPU伺服器建立GPU直連傳輸,目前有3種方法:
第1種方法,是透過物件—檔案雙重存取服務能力。一些新進發展的儲存平臺,同時具備原生支援物件與檔案等2類傳輸協定的能力,即便GDS不相容於物件傳輸協定,這些平臺仍可改用檔案傳輸協定來建立GDS傳輸,如Pure Storage FlashBlade,Quantum Myriad,以及Weka、VAST Data的物件儲存平臺等,都提供這種功能。但這種方式只是繞開問題,而沒解開物件儲存不支援GPU直連傳輸的限制。
第2種方法,是在物件儲存平臺前端,加上相容於GDS的檔案系統層,物件儲存設備先將儲存空間掛載到檔案系統層上,再由檔案系統層與GPU伺服器建立直連傳輸。例如,Hammerspace便宣稱可透過他們的Hyperscale NAS,為後端無GDS連接能力的儲存設備,提供GDS直連存取服務。這個方法理論上適用所有未支援GDS的現有儲存設備,但作為中介的檔案系統層,會增加傳輸路徑中的延遲,並形成新的效能瓶頸,折損GPU直連傳輸的效益。
第3種方法,便是在現有的GDS框架外,發展出基於S3物件儲存協定的GPU直連傳輸架構,讓儲存設備可透過S3協定,與GPU進行RDMA遠端存取。
基於S3協定的GPU直連傳輸
目前已有3家物件儲存廠商發表基於S3的GPU直連傳輸架構,首先是新興物件儲存廠商MinIO,在2024年11月中旬為其Object Store物件儲存平臺引進的S3 over RDMA,接著是老牌物件儲存廠商Cloudian,在2024年11月稍晚,為其HyperStore物件儲存平臺新增的GPUDirect for Object Storage。最晚近是老牌高效能運算儲存服務商DDN,在2025年2月底發表Infinia 2.0物件儲存平臺時,宣稱接下來將會支援GPUDirect for Object。
目前DDN尚未公開GPUDirect for Object的細節,而從MinIO與Cloudian已揭露的S3 over RDMA,以及GPUDirect for Object Storage架構訊息來看,他們採用與GDS不同的方法,達到建立GPU直連傳輸的目的。
對於在檔案系統層級上運行的GDS來說,外部儲存設備的檔案系統是透過修改核心,連接GDS的nvidia-fs.ko軟體元件,實現外部檔案系統對於GPU記憶體的DMA存取。
而S3 over RDMA與GPUDirect for Object Storage,我們認為兩者應該都是透過網路卡GPUDirect RDMA的中介,讓物件儲存平臺建立GPU直連傳輸。利用GPUDirect RDMA在網路卡與GPU之間建立直連傳輸架構,GPU伺服器再透經由前述RDMA網路卡、以S3協定來存取物件儲存平臺上的資料。
透過這種方式,也能達到讓物件儲存設備與GPU建立直連傳輸的目的,資料傳輸同樣不會經過CPU與主機記憶體,而是直接進到GPU記憶體,從而避開CPU與主機記憶體導致的瓶頸,還能將資料傳輸工作卸載給網路卡處理,同時減輕儲存端與GPU伺服器端的主機CPU負擔。但也存在2點限制:
首先,可能會限定搭配使用的網路卡形式。如Cloudian便表示他們的GPUDirect for Object Storage,是搭配Nvidia的ConnectX與BlueField DPU來建立。
其次,目前仍缺乏標準化。不同於GDS的情況,GDS是Nvidia先行發起的技術架構,再推廣到儲存廠商,支援廠商也有Nvidia的官方認證。而物件儲存領域的GPU直連架構,則是物件儲存廠商們自行發起,目前也是各自為政,且缺乏Nvidia官方認證。
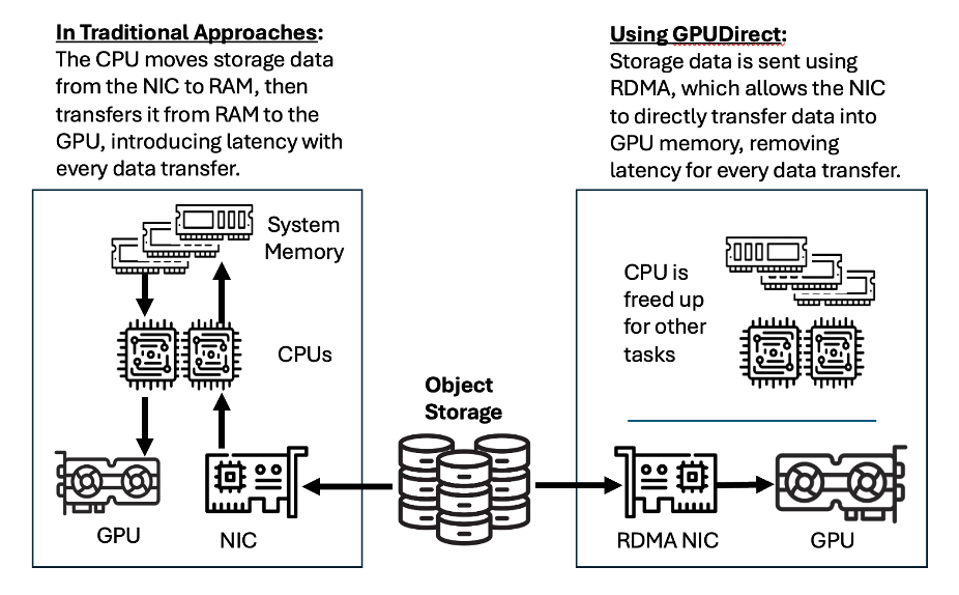
以往物件儲存設備由於不支援GPU直連傳輸,與GPU伺服器間的資料傳輸存取,須經由伺服器主機CPU與系統記憶體中介,從而帶來延遲增加、CPU負荷攀升、傳輸頻寬受限等問題。
Cloudian 發展的GPUDirect for Object Storage則能透過RDMA網路卡,建立與GPU的直連傳輸,透過S3物件儲存協定,與GPU記憶體直接進行存取,避開主機CPU與記憶體導致的瓶頸。
圖片來源:Cloudian
可望成為物件儲存領域新標準
透過新進誕生的物件儲存GPU直連傳輸架構,解決以往物件儲存設備在AI儲存應用的傳輸效能瓶頸問題,儘管目前仍存在周邊搭配與標準化的問題,但支援GPU直連與否,對AI儲存應用的效能影響十分重大,進而也將衝擊物件儲存設備在AI應用領域的競爭力。
我們認為,在MinIO、Cloudian與DDN等廠商率先投入後,應該會有更多物件儲存廠商跟進,支援基於S3物件儲存協定的GPU直連傳輸架構,進而在物件儲存領域形成共通的標準。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06

2026-02-09
")
2026-02-09

")