MLCommons
過去2個多月來,儲存業界最熱門的消息之一,便是專門設計、開發AI應用效能測試基準工具的組織MLCommons,推出針對儲存效能的測試基準工具:MLPerf Storage Benchmark 1.0版,短時間內就獲得14家儲存廠商支持,提交多達數十份測試結果,儼然成為衡量儲存設備AI應用效能的業界基準指標。
MLCommons是由超過 125 個學術界組織、研究實驗室與業界供應商組成的非營利AI工程聯盟,主旨是發展衡量AI應用效能的基準指標,開發AI應用資料集與模型,以及建立AI應用最佳實務範例等,藉此促進AI應用的發展與普及。
而且,MLCommons推出的一系列MLPerf Benchmark效能評估工具,是當前業界衡量與比較AI模型與設備效能的基準,例如MLPerf Training、MLPerf Inference,MLPerf Training HPC等,可用於測量AI模型訓練時間、推論效能,以及科學運算案例執行能力。我們在許多場合,都能見到AI模型開發者,以及相關的軟、硬體廠商或服務商,以這些MLPerf Benchmark效能工具的執行結果,作為自身平臺AI應用效能的證明。
今年9月登場的MLPerf Storage Benchmark 1.0版,則是MLPerf Benchmark效能評估工具家族最新成員,目的是衡量在AI模型訓練時,儲存系統提供訓練資料的速度。由於這項效能評估工具,是以模擬真實的AI訓練工具負載為基礎,因而可以做為可信的儲存系統AI應用傳輸效能基準,同時也能比較不同儲存設備與平臺之間,作為執行AI訓練應用的傳輸效能評估基準。
模擬實際AI工作負載的效能工具
在MLPerf Storage Benchmark問世之前,儲存業界缺乏衡量AI應用儲存效能的可靠基準。
一些廠商是以Linux內含的fio效能測試工具,或是Nvidia GPUDirect Storage(GDS)內含的效能測試工具gdsio執行結果,作為儲存平臺在AI應用的傳輸效能指標,不過,這些工具都只是單純的I/O效能量測程式,僅僅是依用戶的設定,產生指定形式的I/O負載(檔案大小、I/O區塊大小、I/O執行續數量等),來衡量傳輸效能,而非基於實際AI應用的工作負載,因而只能當作理論上的效能表現參考值。
MLPerf Storage則不同,當中實際使用醫學影像、宇宙學(cosmology)資料集,以及視覺資料庫的影像,模擬執行影像分割、影像分類、宇宙學參數預測等工作負載,來衡量儲存系統的傳輸速度,可以實際反映儲存平臺在真實AI應用的資料傳輸能力,因而能作為可信的儲存AI應用效能指標。
另一方面,MLPerf Storage雖然使用真實的AI工作負載,但其執行環境使用的運算單元,是基於模擬的GPU,不需要使用真實的GPU,因而可大幅降低使用門檻。
MLPerf Storage的運作架構
日前發布MLPerf Storage Benchmark 1.0,其實是這項效能測試工具的第2個主要版本,先前MLCommons在1年多前(2023年8月初),就曾發布MLPerf Storage的0.5版。
這兩個版本同樣都是以模擬的GPU作為測試環境,並透過讓GPU保持90%的利用率作為測試基準,輸出的測試結果,同樣都是每秒傳輸的樣本數量,單位是MiB/s。
2個版本的不同之處,則在於可模擬的GPU型式不同,使用的測試工作負載類型也有異。
0.5版只能模擬Nvidia V100這一款較舊型的GPU,1.0版則能選擇模擬Nvidia A100或H100等2種GPU。
在測試使用的工作負載方面,0.5版使用兩種工作負載,一為針對醫學影像分割的3D Unet(每個樣本146 MB),另一為語言處理的BERT NLP(每個樣本2.5 KB)。
1.0版則使用3種工作負載,一為針對醫學影像分割應用的工作負載3D Unet(樣本平均大小139 MB),二為來自ImageNet影像資料庫的影像分類工作負載ResNet50(樣本平均大小111 KB),三為針對宇宙學參數預測的工作負載CosmoFlow(樣本平均大小2.69 MB)。3種工作負載與2種模擬的GPU,會構成6種不同的測試組合。
測試執行時,是透過PyTorch或TFRecord reader將資料集讀取載入到系統記憶體中,然後批次載入模擬的GPU,執行模擬的訓練工作。在維持90%或70%的GPU利用率前提下(3D Unet與ResNet50為90%,CosmoFlow為70%),量測儲存系統提供訓練樣本資料的傳輸速度(傳輸率)。
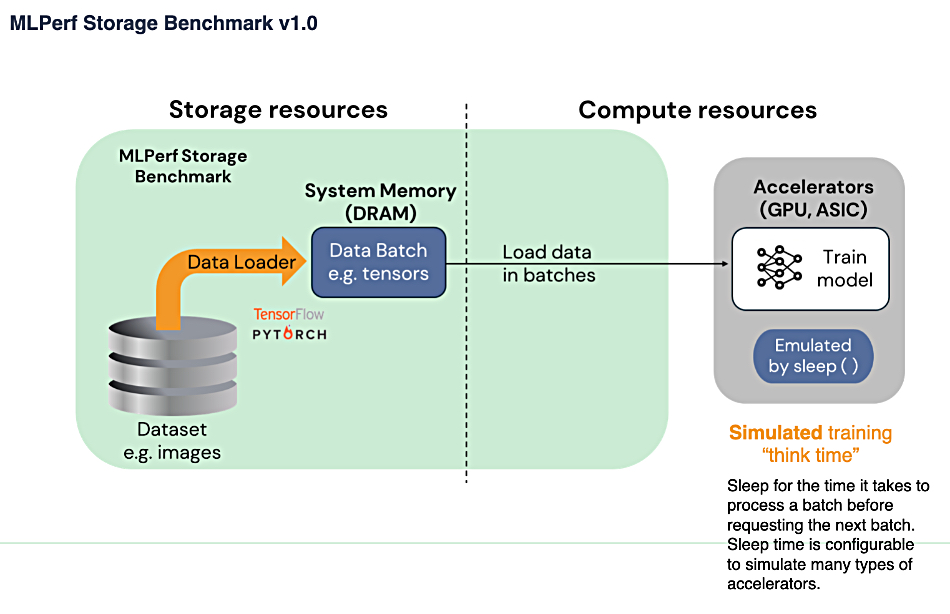
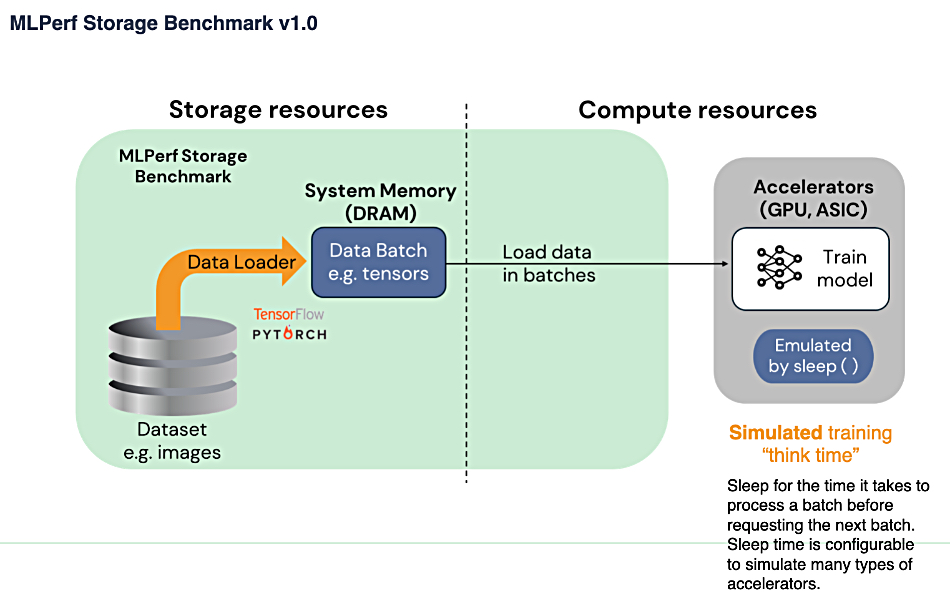
MLPerf Storage測試架構
在儲存端,先由儲存系統將測試資料載入系統記憶體,再載入運算單元的GPU處理。MLPerf Storage要求GPU在測試過程中,須保持90%或70%以上的利用率,但使用的GPU是模擬的,而非實際的GPU。
資料來源:MLCommons
當前的MLPerf Storage測試結果
目前一共有14家廠商,提交MLPerf Storage Benchmark 1.0測試結果,包括DDN、Hammerspace、HPE、華為、IEIT Systems、Juicedata、Lightbits Labs、MangoBoost,美光、Nutanix、Simplyblock、Volumez、WEKA與YanRong Tech。
我們可以注意到這些參與者有2個特色,首先,中國廠商的參與十分積極,14家公司中,中國廠商就有4家,包括華為、浪潮信息(IEIT Systems)、果汁數據(Juicedata)、焱融科技(YanRong Tech)。其次,參與者以新創廠商居多,傳統儲存大廠中,目前只有DDN、HPE、華為、Nutanix與美光等幾家參與。
MLPerf Storage的測試,分為封閉(Closed)與開放(Open)等2個部分,大多數廠商都採用前一種,使用固定的可調參數與選項,藉此具備跨系統與跨供應商的可比較性;後者目前只有Volumez一家參與,這部門允許更彈性的設定,以展現創新程度的結果,但測試數值不具備可比較性。
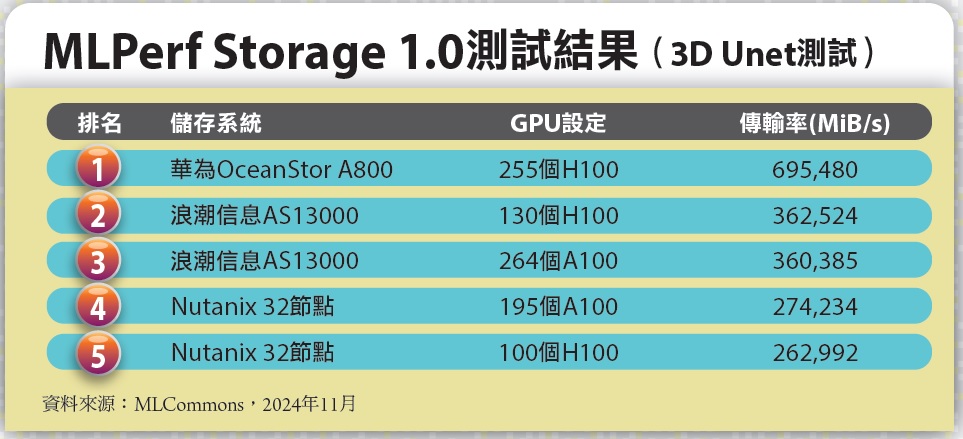
測試結果方面,我們這裡只看具備可比較性的封閉部分。在3D Unet測試方面,就傳輸率數值來看,目前是以華為OceanStor A800稱冠,IEIT Systems AS13000的兩種測試組態分居2、3名,然後是Nutanix 32節點平臺的兩種組態。
在CosmoFlow測試方面,領先者是YanRong Tech的F9000X,然後是IEIT Systems AS13000的2種組態,接著是DDN AI400X2T的兩種組態,再來是YanRong Tech F9000X的另兩種組態。
最後是ResNet50測試,領先的是Nutanix 32節點平臺的兩種組態,然後是YanRong Tech F9000X,再來是DDN AI400X2T。
完整測試結果請參見MLCommons的MLPerf Storage網站。
難以橫向比較個別儲存單元的能力
MLPerf Storage雖然為儲存業界提供了一種可信的AI應用傳輸效能指標,但其測試結果,即便是聲稱具備跨系統、跨供應商可比較性的封閉部分,仍難以做為橫向比較不同廠商儲存系統效能的基準。
顯然的,直接比較2個組態規模相差極大的儲存系統測試數據,是沒有意義的,要做有效的橫向比較,必須對測試結果予以標準化(normalization)的處理,也就是說,將不同廠商系統的測試結果換算為相同的基準,再來做比較。就MLPerf Storage針對的AI儲存傳輸應用來說,需要關注的是運算單元——也就是用戶端GPU主機節點從儲存系統獲得的資料傳輸率。
理論上,將每個系統得到MLPerf Storage測試總傳輸率,除以測試中設定的GPU總數,或是GPU主機節點總數,就能得到標準化的傳輸率表現——平均每個GPU獲得的資料傳輸率,或平均每臺主機節點獲得的傳輸率,藉此就能進行跨廠商的比較。但MLCommons表示,這種標準化換算沒有多大價值。
首先,MLPerf Storage的基本要求之一,是GPU利用率必須達到90%或70%以上,此時每個GPU的傳輸頻寬都接近滿載極限,所以無論哪一家廠商的測試結果,換算為每GPU的平均傳輸率時,差距都很小,最高與最低相差不到10%,不具備鑑別性。
其次,MLPerf Storage測試中的GPU是模擬的,而且可以模擬的GPU數量沒有限制,每一臺主機節點可以設定任意數量的模擬GPU,因此個別廠商間的設定差異極大。
有些廠商採取多達數百甚至上千個GPU的設定,如華為與IEIT Systems在3D Unet測試中採用255個與264個H100 GPU的設定,而在ResNet50測試中,Nutanix甚至採用高達2,100個A100 GPU與1,056個H 100GPU的設定,DDN也有2個組態採用864個A100 GPU與512個H100 GPU,YanRong Tech也採用了540與288個H100 GPU設定。
有些廠商則採用相對很少的GPU數量設定,例如HPE提交的5種3D Unet測試組態,只採用2到15個H100 GPU的設定,Juicedata也只有2個H100,WEKA稍多一些,但也只有13個H100與24個A100。
在MLPerf Storage測試採用不同的GPU數量設定,與真實環境中,在主機節點上實際安裝相同數量的GPU沒有任何關係——在MLPerf Storage測試中為主機節點設定10個H100 GPU,不等同於真實環境中在相同主機節點實際安裝10個H100 GPU的情況,因此,不能以前者推論後者。
MLPerf Storage設定GPU模擬數量的作用,主要是調整儲存系統端的工作負載壓力,設定模擬10個GPU時的負載,是模擬1個GPU時的10倍,設定更多的模擬GPU,可以從儲存系統壓榨出更高的總傳輸率。但另一方面,設定的GPU數量越多,則GPU間消耗在同步上的頻寬資源也越多,會略為減損每個GPU的平均傳輸頻寬。
由於MLPerf Storage沒有限定主機節點與模擬GPU的總數,在個別廠商採用的主機與GPU規模不同的情況下,也就無法有效的橫向對比不同系統的測結果。
所以MLPerf Storage的測試結果,只能看出某個儲存系統在測試組態下的總體傳輸能力,以及此時能支援多少個模擬GPU。顯然的,採用的儲存節點、主機節點數量與模擬GPU數量越多,獲得的總傳輸率也越高,因此,這項測試反映的狀態,其實是各廠商的測試環境投資規模,而難以看出個別儲存系統單元的能力。
熱門新聞
")
2026-02-09
")

2026-02-06

2026-02-06
")
2026-02-09

2026-02-06

2026-02-06

2026-02-06