
資料處理器(DPU)的應用概念,是以輔助運算裝置的角色,來幫助CPU卸載運算負擔,一方面可以將更多的CPU資源保留給應用程式,另一方面則能改善整體I/O效能。概念上雖然如此,但當DPU實際應用在企業環境時,效能可提供到何種程度?以往很少有可供參考的實證數據。
不過,恰好在2021年底,Fungible與Nvidia等2家DPU供應商,先後公布一系列DPU儲存效能驗證結果,也讓大家有了實際檢視DPU應用效果的機會。
Fungible的DPU效能測試
首先是Fungible透過聖地牙哥超級電腦中心(San Diego Supercomputer Center)所進行的效能實測,當中使用該公司的FS1600 DPU儲存伺服器,作為儲存系統端,搭配安裝Fungible S1 DPU卡的技嘉R282-Z93伺服器,作為應用伺服器端(搭載2顆64核心AMD EPYC 7763處理器與2TB記憶體),兩者透過100 GbE網路互連,執行NVMe/TCP傳輸協定,結果在4K讀取測試中,達到了1,000萬IOPS的效能。
作為對照,當應用伺服器端安裝一般網路卡時(Mellanox ConnectX-5),在相同環境下,只得到655萬IOPS效能,而且,其CPU資源占用率接近飽和。也就是說,在應用伺服器端以Fungible的S1 DPU卡取代一般網路卡,IOPS效能提高了50%以上,CPU資源耗用率也從原本的將近飽和狀態,控制在63%。
而在儲存端,Fungible僅僅以1臺基於DPU的FS1600,就為伺服器端提供了1,000萬IOPS的效能輸出。
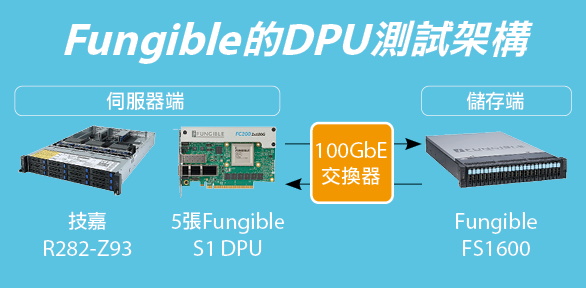
資料來源:iThome整理,2022年4月
【Fungible的DPU測試架構】伺服器端本身是安裝5張Fungible S1 DPU卡的技嘉伺服器,儲存端是Fungible的FS1600 DPU儲存伺服器(內含2組Fungible F1 DPU),構成全面搭配DPU的傳輸架構。至於對照組,則將技嘉伺服器上安裝的Fungible S1 DPU卡,換成一般網卡(Mellanox ConnectX-5)。
Nvidia的DPU效能測試
繼Fungible之後,另一家廠商Nvidia也發布BlueField-2 DPU卡實測結果。
由於Nvidia不像Fungible有DPU儲存陣列產品,所以,他們的效能測試,是以1臺HPE DL380 Gen10 Plus伺服器來扮演儲存端角色,另1臺DL380 Gen 10 Plus扮演應用程式伺服器端角色。
每臺DL380 Gen10 Plus伺服器當中,都安裝2顆Intel Xeon Platinum 8380處理器,一共160個處理器核心,搭配512 GB記憶體,還有2張BlueField-2 DPU卡。伺服器端與儲存端之間透過Nvidia LinkX 100GbE DAC纜線直連。結果在512Bytes NVMe/TCP的100%讀取測試中,得到4,150萬IOPS效能,在4K測試中的IOPS效能,也超過500萬。
不過,Nvidia上述效能測試的驚人IOPS表現,似乎是以儲存端的DRAM作為I/O傳輸的目標端,因此,I/O可能並未實際落到底層的SSD上,主要目的應該是藉此展現作為傳輸端點的BlueField-2 DPU卡吞吐能力。
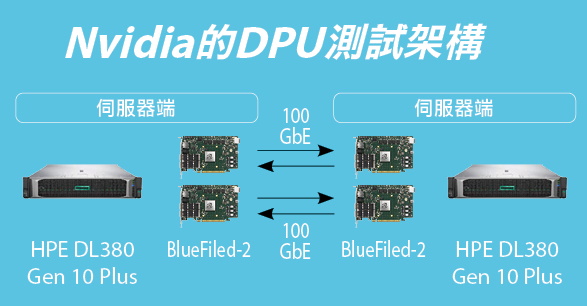
資料來源:iThome整理,2022年4月
【Nvidia的DPU測試架構】伺服器端是一臺安裝2張Nvidia BlueFiled-2 DPU卡的HPE DL380 Gen 10 Plus,儲存端是另一臺HPE DL380 Gen 10 Plus,同樣安裝2張Nvidia BlueFiled-2 DPU,兩端以Nvidia LinkX 100GbE DAC纜線直連,同樣構成全面DPU傳輸架構。
效能與功耗的雙重效益
Fungible與Nvidia兩家廠商,都基於橫貫各個環節(End-to-End)的DPU應用環境來測試,也就是說,不僅在儲存端安裝DPU,在伺服器端也安裝了DPU,兩個端點都具備DPU加速能力。除此之外,兩個端點之間也都是透過100GbE網路連結。
兩組測試的主要差別有二:首先,在兩端點的連結上,Fungible的測試環境,是以一臺100GbE交換器作為中介,至於Nvidia,則是以Nvidia LinkX 100GbE DAC纜線直皆互連。
其次,Fungible的測試是標準的儲存端測試,I/O有實際進到儲存端的NVMe SSD上,可以展現出儲存端的FS1600儲存伺服器實際輸出能力;而Nvidia的測試應該只涉及網路端,展現的是作為傳輸端點的BlueField-2 DPU卡 I/O吞吐能力。
從Fungible與Nvidia的測試結果來看,DPU確實能發揮顯著的加速效果。與未使用DPU的環境相比,只需要耗用1/3不到的處理器數量,就能提供同等的IOPS效能表現,不僅節約了硬體資源,更顯著減少了電力消耗。
在此同時,兩家廠商的測試架構,還有幾點值得我們注意。
第一,兩家廠商都選擇使用NVMe/TCP作為傳輸協定,顯示了NVMe/TCP已逐漸被視為iSCSI接班人,作為新一代低成本區塊儲存傳輸協定的角色,相較之下,NVMe/RoCE協定儘管有更高效能,但考慮到成本,仍難撼動這樣的技術搭配趨勢。
Nvidia在他們的DPU測試中,也另外使用了NVMe/RoCE作為對照,在512Bytes 100%讀取測試當中,可獲得超過5,500萬IOPS效能,比NVMe/TCP的測試效能高出30%。但Nvidia在宣傳上仍舊是以後者為基準,顯示對NVMe/TCP的重視。
第二,在Nvidia的測試中,我們看到伺服器端用於連接儲存端的Initiator軟體,對測試結果有顯著的影響。
例如,Nivdia在此測試使用3種Initiator軟體——SPDK、standard kernel storage initiator(包括4.18與5.15版兩種),以及FIO plugin for SPDK,
測試結果顯示,在4種不同的組合當中(SPDK to SPDK,FIO to kernel 5.15,FIO to kernel 4.18,FIO plugin to SPDK),SPDK to SPDK的效能略勝其他組合。而同為standard kernel storage initiator時,若採用較新的5.15版來測試,其效能也略優於4.18版。

熱門新聞

2026-02-06
")
2026-02-09
")

2026-02-06

2026-02-06


2026-02-06

2026-02-06