AWS
公有雲服務商在物件儲存服務中,提供多種層級的目的,是因應不同的存取需求,幫助用戶達到成本與效能的最佳化。
問題在於,實際應用環境中的存取需求,往往是持續變化的,在許多情況下,用戶自身也難以判斷與預測存取應用適用的儲存層級,因此,固定的儲存層級設定,通常難以適應持續變化、或帶有不確定性的存取應用環境。
理論上,用戶可以透過指令的操作,自行將個別資料物件轉換到合適的儲存層存放,但是在規模較大、較複雜的應用環境上,單靠手動調整資料儲存分層的方式,顯然是不切實際的,此時便是自動分層儲存功能派上用場的好機會。
自動分層儲存的原理,是監控個別資料物件的存取頻率,自動將很少存取的資料,遷移到合適的低成本儲存層級存放,幫助用戶達到儲存效能與成本的最佳化,進而實現自動化的資料生命週期管理。
自動分層儲存的2種實作形式
在公有雲物件儲存服務上,有2種方式可以實現自動分層儲存的目的:
第1種方式,是透過設定或編寫資料生命週期管理政策來進行自動調配,便能依照設定的資料到期(expiration)條件(例如該物件建立後經過一定天數),自動轉換Bucket容器內個別物件所在的儲存層級。
第2種方式,是透過服務商提供的自動分層服務功能,可省去麻煩的規則編寫工作,便能達到自動分層儲存的目的,應用上更為簡便,缺點則是物件分層遷移的條件是服務商預設的,無法依用戶需要自行設定。
主要公有雲的物件分層儲存功能
目前所有主要公有雲服務商的物件儲存服務,都能透過資料生命週期管理政策,來實作出自動分層儲存應用。另有少數服務商,提供了獨立的自動分層服務功能。
AWS S3
在AWS S3上,有2種方式可以達到自動分層儲存的目的。
第1種是透過S3主控臺、SDK或指令,編寫與設定Bucket儲存容器的生命週期組態(lifecycle configuration),藉此便能依照用戶設定的資料過期規則,將過期的資料從「S3標準」層,轉換到指定的層級,包括:S3標準—不常存取(IA)、S3標準—不常存取(單區域)、S3 Glacier、S3 Glacier Deep Archive或S3智慧型分層。
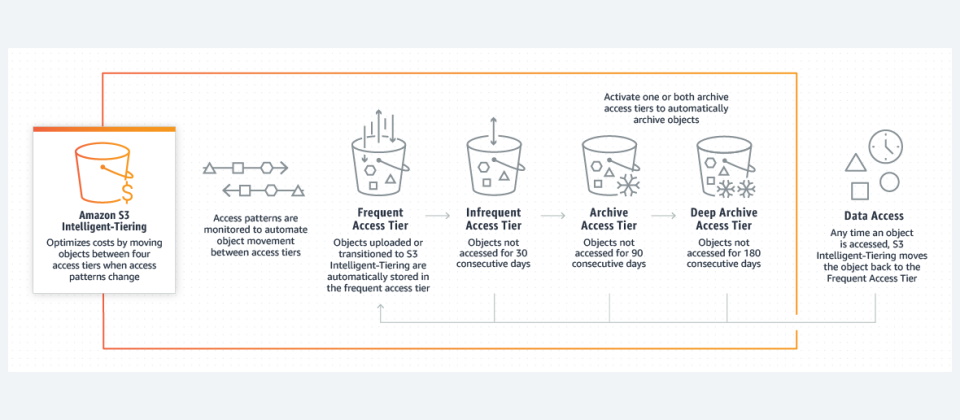
第2種是一開始便直接選用「S3智慧型分層(S3 Intelligent-Tiering)」這個儲存服務類別,其中提供了4種儲存分層,包括2個低延遲存取層——經常存取層(Frequent Access Tiers)、不常存取層(Infrequent Access Tiers),以及2個針對極少存取資料的非同步存取層——歸檔存取層(Archive Access Tiers),以及深度歸檔存取層(Deep Archive Access Tiers)。
經常存取層與不常存取層的規格,等同於這2個S3儲存服務類別:S3標準,以及S3標準—不常存取,但成本低了40%。而歸檔存取層與深度歸檔存取層的規格,則分別等同於「S3 Glacier」與「S3 Glacier Deep Archive」。
用戶上傳到「S3智慧型分層」儲存區的資料,會先存放在經常存取層,如果資料連續30天無存取活動,系統便自動會將資料轉存到不常存取層。如果用戶啟用了封存存取層的話,系統會將連續90天無存取的資料轉存到歸檔存取層,也會將180天無存取的資料轉到深度歸檔存取層。如果用戶稍後存取該資料,系統則會將其轉到經常存取層。
此外,S3智慧型分層中各層級的資料搬移或擷取下載,都無須額外支付費用,使用上相對比較經濟。
Azure
基本上,微軟Azure物件儲存服務提供的自動分層儲存功能,主要是透過編寫Bucket容器的資料生命週期管理政策(Lifecycle management policies)實現。
Azure的用戶可透過編寫JSON Web指令檔的script規則,依用戶設定的規則(例如該物件多久時間未被存取),即可將放置在經常性(Hot)儲存層的資料,轉存到非經常性(Cool),或是歸檔(Archive)儲存層中。
Google Cloud
目前Google Cloud採行的做法與Azure相似,用戶可透過編寫JSON或XML型式的物件生命週期管理(Object Lifecycle Management)指令,利用其中的「SetStorageClass」功能,便能依照設定的時間條件,調整指定Bucket容器中個別物件的儲存層級,例如從標準級轉換到Nearline、Coldline或Archive級。
不過,「SetStorageClass」功能的使用上有其限制,那就是:轉換後的新儲存層級,必須比原有層級更低,而不能更高,例如:「Nearline」只能往下轉為「Coldline」或「Archive」,而不能往上轉為「標準」級。
Oracle Cloud
現今Oracle Cloud物件儲存服務的自動分層應用有2種方式,第1種是利用物件生命週期管理政策(Object Lifecycle Management,OLM),依照用戶預先設定的條件,自動將資料從「標準級」的Bucket儲存容器,轉換到「不常存取級」或「歸檔級」。
第2種則是透過自動分層(Auto-Tiering)功能來實現,當用戶建立「標準級」的Bucket儲存容器,便可選擇啟用這個功能。啟用後,自動分層功能會監控儲存容器中大於1 MB的全部物件,如果物件超過31日都未被存取,將會自動移到「不常存取級」儲存容器。
不過,Oracle Cloud這個功能有2個限制,若用戶已為特定Bucket儲存容器建立了物件生命週期管理政策(OLM),將資料轉存到「不常存取層」後,將無法啟用自動分層功能;其次,他們此處的自動分層功能,無法將物件轉存到「歸檔級」儲存容器,用戶必須另外透過指令或OLM政策,才能將物件轉存到「歸檔級」儲存容器。
IBM Cloud
目前IBM Cloud物件儲存服務的分層儲存應用方式,是利用物件儲存容器的生命週期管理功能,藉由編寫歸檔政策(Archive Policy)或到期規則(expiration rules),將標準、儲存庫、冷儲存庫等3個儲存層的資料,依規則轉存到「歸檔」或「加速歸檔」這2種長期保存儲存層。
特別值得一提的是,IBM Cloud提供十分特別的「智慧分層(Smart Tier)」類型Bucket儲存容器,從名稱看來,這項服務很類似自動分層儲存應用,但實際上並非如此。
其實,IBM Cloud的「智慧分層」是簡化的分層費率計算模式,系統會持續追蹤存放於這種容器的物件儲存行為,每月月底結算費用時,會依照該Bucket容器整個月的存取行為,將費率分為Hot、Cool與Cold等3個層級,依此向用戶收費。
阿里雲
最後來看阿里雲的做法,他們對於物件儲存服務實現分層儲存的方式,也是在主控臺建立生命週期管理政策,設定管理規則(如過期天數),將「標準」級儲存區中的物件,依政策設定,自動轉存到「低存取頻率」或「歸檔」級的儲存區。
分層儲存功能的限制
整體而言,以6大公有雲服務商的物件儲存服務來看,都提供利用編寫資料生命週期管理政策的方式,來建立自動分層儲存應用。而AWS與Oracle Cloud還提供獨立的自動分層儲存服務或功能,應用上更為簡便。
但無論是透過資料生命週期管理政策,還是透過自動分層儲存功能,都必須注意適用的層級限制,還有兩者之間的相容問題。
一般來說,資料生命週期管理政策可以套用的儲存層級較廣,相對地,自動分層儲存功能往往只適用少數層級。例如,Oracle Cloud物件儲存服務的物件生命週期管理政策(OLM),可適用於其提供的3種儲存層級(標準、不常存取與歸檔),但他們提供的自動分層儲存功能,只適用於2種儲存層級(標準與不常存取)。
另外,有些公有雲業者的自動分層儲存功能,無法與資料生命週期管理政策同時使用,如Oracle Cloud便是如此。
.png)

熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-06