
英特爾
在2019年11月的美國超級電腦大會期間,英特爾宣布,他們將基於自行發展的Xe架構,推出新的通用繪圖處理器(GPU),而為了因應高效能運算的建模與模擬工作負載、機器學習訓練等應用需求,他們預計推出代號為Ponte Vecchio的獨立GPU,基於Xe架構之餘,也將導入英特爾7奈米製程,以及Foveros 3D、EMIB封裝技術,當中會集結HBM記憶體、CXL互連介面等多種技術智財,整合至單一封裝。
英特爾期盼透過這樣的產品,搭配新世代Xeon Scalable系列伺服器處理器,也就是代號為Sapphire Rapids的產品,以及橫跨多種運算架構的統一程式開發模式:OneAPI,實現百萬兆級(exascale)運算。當時,他們也宣布美國阿貢國家實驗室Aurora系統,將運用上述產品來建置運算節點。
隔年8月的英特爾架構日,他們揭露Xe架構更多資訊,例如,細分為4種微架構,而Ponte Vecchio對應的是其中的Xe-HPC微架構,而在封裝方式上,採用Foveros、CO-EMIB等兩種作法,當中包含多種晶磚(Tile)。

到了今年3月舉行的Intel Unleashed線上發表會(也就是英特爾宣布IDM 2.0策略的那場活動),執行長Pat Gelsinger首度公開展示Ponte Vecchio晶片。

在6月的歐洲國際超級電腦大會期間,英特爾宣布Ponte Vecchio已過電開機,進入系統驗證階段,並將提供OCP Accelerator Module(OAM)外形的模組,以及基於4張OAM模組而成的子系統,以此支援高效能運算應用下的縱向擴展(Scale-up),以及橫向擴展(Scale-out)部署需求。

過了一個月之後,英特爾在他們的Accelerated線上發表會,重申加速製程與封裝創新,再度提及Ponte Vecchio,並表明這系列將是首款採用EMIB與第二代Foveros封裝技術的產品。

到了8月,在英特爾召開的年度架構日當中,針對Ponte Vecchio這款資料中心GPU,揭露更多技術層面的資訊。
例如,他們首度詳細介紹Xe-HPC微架構的組成,以及延展性。在效能方面,以設計定案送交製造的第一版為例,根據英特爾內部測試,FP32運算效能超過45 TFLOPS,記憶體存取頻寬達到5 TB/s以上,連結頻寬是2 TB/s以上。若使用ResNet框架來進行推論,每秒可處理4.3萬張以上的圖片,若使用ResNet進行訓練,每秒可處理3,400張以上的圖片。

提供超越競爭對手的運算效能與I/O頻寬
對於Ponte Vecchio運算效能、記憶體頻寬、連結頻寬等規格,英特爾在今年8月英特爾架構日首度公開相關資訊,就產品賣相來看,相當具有市場競爭力,足以威脅Nvidia這幾年主推的A100 GPU,甚至是尚未發布的第四代NVLink。圖片來源/英特爾

採用模組化、多晶磚架構,堪稱英特爾最複雜的晶片設計
就晶片設計方式而言,今年英特爾架構日也揭露Ponte Vecchio的特點。它和Sapphire Rapids一樣,也是由多個晶磚(Tile)組合而成,但架構設計上更為複雜,該公司負責這項產品的總工程師Masooma Bhaiwala,甚至將這項產品評為:「從事晶片建構工作30年以來,最複雜的晶片」。
簡而言之,這些單元是透過多片EMIB晶磚組裝起來,而能以低耗電、高速的方式,將晶磚與晶磚之間連結起來,而這群晶磚之後會放在Foveros封裝之中。
Ponte Vecchio本身所使用的晶磚類型也相當豐富,英特爾先前提到有47片之多,但到底有多少種?
他們也在2021架構日,首度揭露這款系統單晶片架構是由8種元件所組成,分別是:運算晶磚(Compute Tile)、Rambo晶磚、Forveros、基礎晶磚(Base Tile)、HBM晶磚、Xe Link晶磚、可容納多個晶磚的封裝(Multi Tile Package)、EMIB晶磚。

Ponte Vecchio的硬體製程設計
從產品設計工程的角度來看,Ponte Vecchio這款系統單晶片,使用超過1千億顆電晶體,裡面放了47片晶磚(Tile),總共使用5種製程,因此,在架構設計上,相當複雜,也突顯其挑戰性。圖片來源/英特爾


提供運算組建區塊,能以層層堆疊方式擴充GPU應用規模
就運算與擴充性而言,Ponte Vecchio不只導入多晶磚式設計,就其採用的Xe-HPC微架構而言,英特爾目前區分成4種階層式組建區塊(building block),包含:核心(Core)、片段(Slice)、堆疊(Stack)、連結(Link),並以圖解方式呈現各自的特色,以及彼此的關係,讓所有人理解GPU規模如何擴充。
Xe-Core
首先是核心,也就是Xe-Core,內含8個向量引擎、8個矩陣引擎(Xe Matrix eXtensions,XMX),以及號稱業界最大的512 KB容量L1快取記憶體。
Xe-Core當中的每個向量引擎可支援512位元寬度的向量,以此處理整數運算與浮點運算,若是FP16、FP32、FP64型別,每個週期可分別執行512、256、256個運算。

至於矩陣引擎的部分,每個內建8個脈動陣列(systolic array),而且,在每個運算週期中,可執行8組512位元寬度的向量處理。
無論是向量引擎或矩陣引擎,都可支援寬型的載入/儲存單元(Load/Restore),每個運算週期可餵送512 Bytes資料。

Xe-HPC Slice
Core往上一層就是Slice,這一層的擴充,包含16個Xe Core、16個光線追蹤單元(Ray Tracing Unit)、1個硬體式脈絡交換處理(Hardware Context)。
基本上,16個Xe Core能為整個Xe-HPC GPU,提供8 MB的L1快取記憶體(16 x 512 KB);光線追蹤單元包含多種固定功能的計算。

Xe-HPC Stack
串連更多Xe-HPC Slice,即可組成Xe-HPC Stack,事實上,這個階層也等同於一套完整的GPU。基本上,每1個Xe-HPC Stack,包含了4個Xe-HPC Slice,而此時,也等於坐擁64個Xe Core、64個光線追蹤單元,以及1個硬體式脈絡交換處理。
這一層還配更大容量的L2快取記憶體(英特爾稱為Xe Memory Fabric),以及4個HBM2e記憶體控制器、複製引擎(Copy Engine)、媒體引擎(Media Engine),以及8個Xe Link。

同時,Xe-HPC的架構支援多堆疊式(Multi-Stack)設計,英特爾強調這也是業界首創的作法。之所以能實現這種方式,主要仰賴的是他們發展的EMIB封裝技術。而且,每一座Xe-HPC Stack堆疊中的Xe Memory Fabric,可以直接相互連結,如此可促成兩座Xe-HPC Stack之間,能有統合、一致的記憶體。


Xe-HPC 2-Stack型態的Ponte Vecchio
英特爾頂級資料中心GPU:Ponte Vecchio,今年已在兩個重要場合亮相,一次是3月的IDM 2.0策略的線上發表會,執行長Pat Gelsinger首度公開展示這款晶片,另一次是英特爾架構日,負責這項產品的總工程師Masooma Bhaiwala,展示Xe-HPC 2-Stack型態的Ponte Vecchio。圖片來源/英特爾
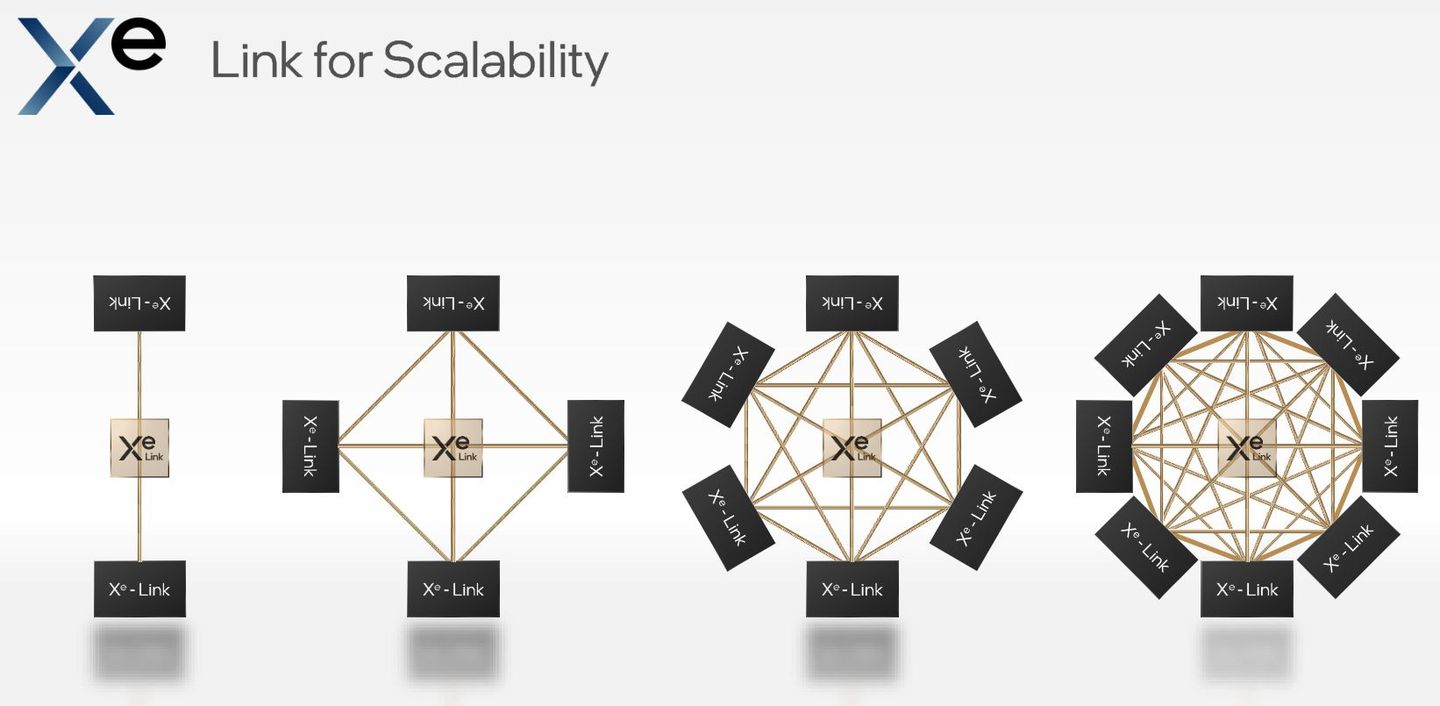
Xe Link
這項介面可針對GPU對GPU之間的連結,提供高速、一致的I/O交織存取,支援載入/儲存、大量資料傳輸。
同時,它內建了8埠交換器,可用於單節點、8個完全連結的GPU,而不需要其他元件的協助。而這個特色也讓用戶能藉此建立有彈性的拓樸。透過圖解的呈現方式,英特爾也逐一示範單節點的多種GPU連接架構,從最基本的2個GPU,常見的4個GPU,到因應更大型處理需求的6個GPU、8個GPU。而基於這樣的架構,若要做到縱向擴展,不需要額外元件。


整體而言,無論是Ponte Vecchio或Xe-HPC,就英特爾本次公布的硬體架構設計,以及層層堆疊的擴充性,的確具有一定的說服力,然而,能否讓市場接受,進而挑戰競爭廠商的領導地位,關鍵可能在於軟體生態系的健全與開放,以及各種應用場景的拓展。


熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
