圖片來源/IBM,iThome製表
關於認知運算系統的發展,在市面上,我們比較熟悉的解決方案,以商用領域來說,可能會先想到的是IBM的Watson,而消費端應用裡面,是以整合的平臺或行動App的方式來提供。
整體而言,想要建立認知系統,所涵蓋的技術類型相當廣泛,像是大資料處理與分析、自然語言處理、語義分析、資訊擷取、機器學習、自動推理(Automated Reasoning)、人工智慧。
在認知系統上,需要搭配的硬體設備也相當多樣,像是後端是伺服器、雲端服務,前端則可能是個人電腦、智慧型手機、平板電腦,或是各式各樣的智慧型設備,例如穿戴裝置、環境感測器、視訊監控系統,甚至是家電。
但不論是何種軟硬體,認知運算終究脫離不了資料處理與分析。
未來會走向認知型的世界,臺灣IBM系統硬體事業群總經理魏大洋表示,就各行各業而言,或從人、物的角度來看,都在走向數位化,資訊爆炸的力道相當驚人,而且所面對的大部分都是非結構化資料,單靠人為的判斷,無法及時處理許多事情。若要建構出資訊系統來協助因應這樣的環境變化,魏大洋認為,這樣的電腦所提供的功能,需要滿足3個條件:了解、推理、學習。系統要能了解使用者身處環境裡面的資料,然後能發現資料之間的關聯性,並且可以從這些資料、關聯性,進行自我學習,協助你面對未知的挑戰,使適應變化的成本能夠降低。
以資料為中心,將是新一代運算系統發展的重要目標
對於現在電腦運算與存取資料的速度,很多人可能覺得速度已經相當快,甚至認為實際使用率有限、效能經常處於過剩狀態,然而,在認知運算的時代,大資料的處理將會是常態,若用現在的電腦架構是無法因應的,有些廠商開始對此提出對策。
以IBM為例,從2012年起,他們開始提出了以資料為中心(Data-Centric)的系統概念,企圖突破目前系統處理資料的局限。
這是因為既有的電腦系統的運作模式,是以處理器的運算為中心(Compute-Centric)。而且,在這樣的系統架構下,資料存放在硬碟或磁帶上,若要將當中的內容輸入處理器,或從處理器輸出到儲存裝置上,都需要載入記憶體,才能抵達目的地。此外,不同的儲存裝置所能提供的容量、存取速度差異很大,例如記憶體可提供GB等級容量、存取速度最快;硬碟的儲存容量是TB等級,I/O速度平平;磁帶可保存好幾PB的資料,存取速度最為緩慢,因而單是儲存資料的所在,就構成了多個階層。
而所謂以資料為中心的運作模式,資料是在可持續存放資料的記憶體中,當中可放置內容的容量高達PB等級,而且許多處理器是環繞著這些記憶體旁邊,當它們要存取資料時,面對的儲存階層也較為扁平。
認知就在一瞬間發生,須在毫秒或微秒內完成資料分析工作
而在認知運算時代,改用以資料為中心的系統,主要的理由在於要達到這樣的目的,我們不只是把資料拿過來、放到系統,然後再加以分析,就夠了,所謂的認知,有很大部分的工作是要判斷、推理,做到即時假設、評估,而這裡的「即時」,所指的是在毫秒或微秒內完成任務。
要求電腦認知的方式,就像人腦在處理資訊。舉例來說,我們眼睛一看到別人時,就馬上知道對方戴眼鏡、穿了襯衫、打了領帶,推測他可能要見重要的人,類似這樣的理解,就是即時的假設──我們會以先前所學習到經驗,來看待所收集到的資料,然後給予意義,進而體認到這個現象的價值。
因此,認知運算不只是分析工具而已。因為透過這樣的工具,固然能夠去資料裡面,去抽取一些意義,或看出其模式、找出重要資料,魏大洋強調,認知運算並不僅止於此,系統還要有辦法從資料去做學習,以及了解你手上所擁有的資料。然而,在大資料的浪潮下,我們對於所面臨的狀況,往往是資料的數量(Volume)過於龐大、種類太多(Variety)、產生速度太快(Velocity),連帶地,要確認價值(Value)與真實性(Veracity),也變得相當困難。因此我們需要有一套系統來因應這樣的局面,才能夠快速抽取這些資料其中的價值,然後從資料中得到更多的洞察力。
為了能夠支援大資料與認知運算,資訊系統需要非常快速的處理效能,以IBM而言,他們認為運算架構必須有所調整,不論是儲存、運算或是記憶體,不能只是連接到系統的零件,其實應該是屬於系統運作核心的一部分,而這個核心就像中央處理器本身,因為這些地方都是資料所存在的位置。
除了有高效能的系統,另一個不可或缺的部分是對於自身擁有資料的了解,我們需要有資料科學家、資料工程師,還要有能夠管理資料的人,才能用認知的角度來看待這些資料。
如果把全部資料都交給處理器去分析,會變得沒有意義,因此我們要提供的是「重要的」資料,而且是聚焦在跟眼前正在處理的事情有關的資料,這才是真正的資料管理。IBM認為,目前的問題在於,很多用戶在資料管理的作法上,並沒有搭配恰當的階層化資料儲存基礎架構,而且很缺乏資料科學家,也沒有足夠的資料工程師來管理資料品質和數量,所以勢必要在資訊基礎架構或組織整體發展的觀點上,做出一些改變,以便讓我們得以擁有更多看待資料的方式。
-600-1.png)
以運算為中心的舊架構
從System 360大型主機以後所發展的個人電腦,基本上,都是依循以運算為中心的模式來建立,資料會持續存在的位置,主要是在硬碟和磁帶上,資料可以載入記憶體,但不會持續常駐,一旦系統關機,記憶體不會保留任何資料。此時,處理器是系統架構的核心,記憶體、儲存裝置都是圍繞在處理器旁邊,而且是以多個階層方式存在。一般而言。資料在系統需要執行工作時,才會傳輸到處理器。(圖片來源/IBM)
-600-5.png)
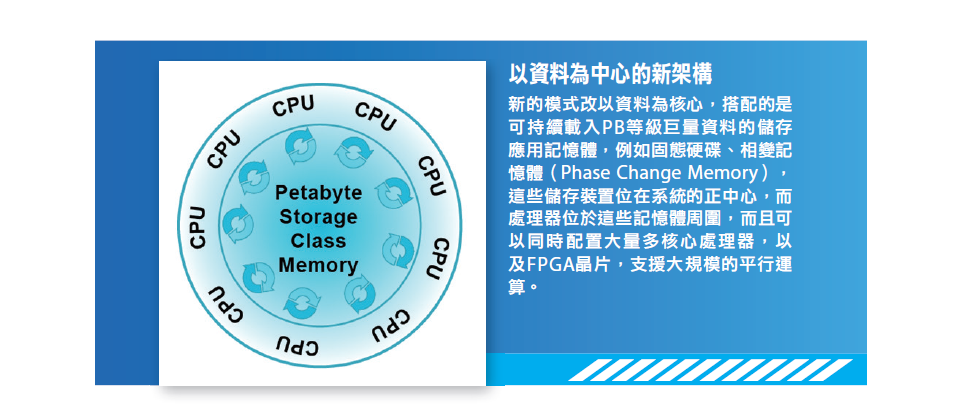
以資料為中心的新架構
新的模式改以資料為核心,搭配的是可持續載入PB等級巨量資料的儲存應用記憶體,例如固態硬碟、相變記憶體(Phase Change Memory),這些儲存裝置位在系統的正中心,而處理器位於這些記憶體周圍,而且可以同時配置大量多核心處理器,以及FPGA晶片,支援大規模的平行運算。(圖片來源/IBM)
提升系統性能需要新作法:設法集中以減少資料傳輸成本
若要充分支援認知運算,提升系統處理大資料的能力,已經成為必須面對的課題,前面我們提到了以資料為中心的新模式,希望調整資料與處理器之間的位置,設法聚焦在資料,由處理器環繞著它們來運作,而不像既有系統架構的作法是聚焦在處理器,而資料是圍繞於運算資源之外。
然而,上述的架構演進仍在持續發展中,至今仍未大量普及,但以目前的系統而言,已經開始有廠商陸續導入新作法,設法縮短處理器與儲存裝置之間的距離,減少傳輸資料的動作,這種擴充效能作法稱之為斂合(Scale-In),顧名思義,重點似乎在於系統架構的「收斂、整合」。
在IBM資深副總裁暨全球研發中心總負責人John E. Kelly II的《智慧科技:推動大智移雲的利器》,也提到這件事。書中寫道:「未來以資料為中心的電腦將具備一個基本特徵:電腦工程師會設法把記憶體跟邏輯線路,整合在一顆緊緻的立體晶片中,採用斂合(Scale-In)的新堆棧方法。」
可能對很多人來說,Scale-In是個很陌生的技術名詞。我們經常聽到的相關名詞描述,主要是縱向擴展(Scale-Up),以及近年來紅遍半邊天的橫向擴展(Scale-Out)──在企業儲存、雲端運算領域,一談到系統延展性、擴大系統運作規模的作法,幾乎人人皆知Scale-Out。
的確,Scale-In應用方式在企業IT領域較為罕見,先前我們只看到Citrix曾經使用這個名詞──在該公司旗下的應用程式服務派送控制器產品NetScaler,支援3種擴充系統執行規模的作法,除了較多廠商實作的Scale-Up、Scale-Out,也引進了Scale-In的概念,但這裡的Scale-In主要是為了簡化、系統整併,當中借助了伺服器虛擬化技術,讓一臺SDX系列的應用設備,可同時執行大量NetScaler系統(之前是40臺,現在可到80臺),並支援多租戶的服務模式。
而在系統廠商來說,特別強調Scale-In作法的IT公司並不多見,大部分廠商所推出的整合式方案,大多是融合式基礎架構(Converged Infrastructure),以及超融合基礎架構(Hyper-Converged Infrastructure),可收伺服器整併、簡化管理、快速部署之效,但並非是為了縮短處理器與儲存之間的傳輸成本而設計,因為這些公司畢竟沒有設計處理器、推動運算架構變革的能力。想要做到更深度的整合與改良,對於本身可研發處理器的IBM和Oracle而言,就比較有機會。
-600-3.png)
既有擴充系統規模方式
若要提升電腦運算能力,我們目前已採用了Scale Down、Scale Up、Scale Out等作法,其中,Scale Down稱為微縮,是在單晶片上堆放更多電路布局、記憶容量;Scale Up是換裝運算能力更強大的系統元件,俗稱升級;Scale Out則是橫向擴充,將多臺伺服器聚集在一起串連,成為一臺更大的系統。(圖片來源/IBM)
-600-4.png)
新的擴充系統規模方式
為了更進一步縮短每個系統元件之間的距離,在單一晶片內,就可以執行更大規模的資料存取與網路傳輸,有廠商推動Scale In的作法,希望將記憶體和邏輯線路整合在一顆立體晶片上,實作以資料為中心的架構。(圖片來源/IBM)
以IBM來說,他們近幾年持續在其產品推動Scale-In的作法,並逐步實施在不同類型的產品上,他們端出的成果所涵蓋了多種類型的系統,大至整櫃式IT基礎架構系統PureSystems、資料倉儲應用伺服器Netezza,以及伺服器Power7 775,小至今年5月推出的CMOS整合奈米光子(CMOS Integrated Silicon Nanophotonics)的矽晶片。在這些設備上,IBM都做到了同時整合處理器、記憶體、網路、儲存,相當難得。
若就現有系統產品來說,IBM近年來在Power平臺及大型主機系統的設計上,主要焦點就是大資料,他們希望處理器、伺服器的架構,可協助大量資料的存取作業,讓資料處理的速度變得非常快。為了達成這個目的,他們會改變運算平臺的一些配置,例如處理器晶片本身是否需整合特定元件,以及能否與其他系統元件直接連結。
例如,從Power8世代運算平臺開始,IBM引進了CAPI介面(Coherent Accelerator Processor Interface),使得伺服器的處理器與FlashSystem全快閃儲存陣列,可直接連結在一起,以較低成本做到類似記憶體內處理(In-memory)的效果,比起傳統的作法,據說指令長度可節省97%(從2萬個指令減至500個指令以下)。
另一個減少運算資料傳輸的作法,則是針對處理器與繪圖處理器(GPU)的協同運算應用,讓兩者可以直接彼此互連。
為此,IBM在Power處理器支援Nvidia的NVLink互連技術,將使得Tesla系列GPU存取Power處理器的記憶體時,得以運用完整的頻寬來進行資料傳輸。
除了上述的例子之外,對於處理器平臺的發展而言,做出不需要離開晶片就能存取到資料的技術,已經是大勢所趨,而這些方法包括:持續增加互相連結的匯流排,以及記憶體的快取容量、傳輸頻寬,提供相關的演算法。
在這樣的架構下,系統可以用非常快的速度將資料傳輸到運算晶片上,因為要這麼做,並不需要連接到外接儲存裝置或系統,或任何其他的離線儲存。IBM也預言Power運算平臺的下一代處理器Power9,也將繼續為了強化大資料應用而設計,將會聚焦在更大容量、而且是能持續存放資料的記憶體運用上,進一步實現以資料為中心的新型運算系統。
另一條縮短資料傳輸成本的出路:近端資料處理系統
為了將資料與運算之間的距離縮短,也有一些廠商在推動近端資料處理(Near-Data Processing,NDP)的作法,後續發展值得觀察。
簡而言之,NDP是將資料所在的儲存裝置或系統上,例如快取、主記憶體、可持續保有資料的儲存設備上,直接執行運算,如此一來,可降低對於I/O頻寬上的需求。
採用NDP概念的產品或廠商,主要有IBM Netezza、美光的Hybrid Memory Cube與Automata處理器、被儲存大廠EMC併購的DSSD,以及Oracle的Exadata資料庫應用設備。
|
程式化電腦與認知運算時代的系統管理差異 程式化電腦時代 ● 以處理器為中心 ● 固定式計算 ● 縱向擴展、橫向擴展 ● 手動管理系統
認知運算時代 ● 以資料為中心 ● 統計式分析 ● 收斂整合 ● 自動管理系統與工作負載 資料來源:IBM,iThome整理,2012年 |
|
4種擴展規模方式對應的關鍵技術 在現行的系統擴展規模方式中,可運用Scale Down、Scale Up、Scale Out、Scale In等4種作法。 ● Scale Down:重點在於使有限的晶片密度提供最多功能,因此廠商會在當中發展原子等級的電晶體和儲存。 ● Scale Up:目的是提升裝置可負載的容量,因此會在處理器和硬碟來實施。 ● Scale Out:是針對整體系統提供最大容量,因此像是刀鋒伺服器和NAS這類系統會採用這概念。 ● Scale In:要做到的是降低每個元件之間的I/O延遲,並提供更高的系統密度,因此多核心運算的導入、FPGA晶片的搭配、晶片採用3D立體架構設計,以及固態儲存、相互連結匯流排的直接存取,都與此概念相關。
|
-600-2.png)
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05