
許多工程師經常思考一個問題,到底我的系統瓶頸在哪裡?事實上可能在你的 Web Server 上,可能在服務裡面的某個複雜邏輯,也可能在 API、資料庫,或落在一個令我們意想不到的地方。
欲解決前述的謎團,必須倚靠持續不斷的監控,才能發現問題點,進而改善問題。因此在「ModernWeb'21 VIRTUAL EVENT」中,特別安排來自新加坡商鈦坦科技的碼農 Norman,提出「使用 APM 改善系統效能」演說,引導工程師知道如何透過監控找出真正的系統瓶頸,據此進行處理或改善,避免越改越糟的窘境。
經由 APM 畫面,掌握交易的延遲與吞吐量
Norman 指出,APM 為「Application Performance Monitoring」縮寫、即是應用程式效能監控。他以 Elastic APM 為前提進行 APM 架構說明,首先用戶需要在服務上安裝 APM Agent,接著 Agent 會蒐集系統資訊、傳送到 APM Server,然後 APM Server 就把這些資料存放於 Elasticsearch,之後用戶即可透過 Kibana 查看 APM 的整合資訊,涵蓋一些服務名稱、處在什麼樣的環境、執行何等類型的交易(Transaction),乃至相關的延遲(Latency)、吞吐量(Throughput)、第 95 個百分位(95th Percentile)等等內容。
.jpg)
「在實務上,我們需要留意的是『Impact』,」Norman 說,其計算方式是處理時間乘以吞吐量,意謂假使你的服務蘊含較高的交易處理量,且所需處理時間較久,就會對系統產生較大影響。
.jpg)
接著他列舉多個在鈦坦內部發生的實例,以彰顯 APM 發揮的作用。第一例是「改善非同步呼叫」,從 Elastic APM 畫面可看出每個交易內含不同顏色的 Span,象徵不同服務之間有一些請求在進行;後來發現儘管採用非同步呼叫,但實際上卻呈現近似同步處理的狀況,係因不同團隊合作開發某些功能時,未留意彼此間的實作細節,以致每個人都做了非同步請求,最終這些請求一個接著一個送出去。
鈦坦發現此問題後,隨即透過程式的小幅修改,讓這些請求能在當下同時送出;使原本歷時 1.8 秒的頁面處理過程,驟減到 0.2 秒完成。
.png)
.png)
第二例是「高度相關的功能」。曾發現某個交易呈現 4 個 Span,分別針對同一服務的 4 個 API 進行呼叫,起因於迭代開發下不斷疊加新功能,卻未注意新舊功能是否有高度重複性或相關性,才導致這個狀況。後來改善 API 設計,將較多的 API 整合為少數 API,甚至只用一個 API 做完這個交易。
.png)
第三例是「冗餘的呼叫」,曾導致鈦坦的某個交易處理時間增加近一倍;檢視交易細節,發現頁面上有一些資料是少數使用者需要的,而使用者經由第三方 API 獲取這些資料,豈料因所有人都打了這個 API,以致整個頁面處理時間增加 0.3~0.9 秒,對使用者體驗影響甚大。後來多加一個判斷,便迅速解決此問題。


調整程式碼或設定,化解 CPU 異常飆高現象
接下來第四例是「重複的呼叫」。實際狀況是,前端在頁面載入的一開始先執行 API 呼叫,當前端的 JavaScript 載完後,就對使用者身份進行驗證,驗證完後又會因應不同使用者身份,再打一次相同的 API,造成短時間內重複呼叫這些交易。發現此問題後,鈦坦決定在前端呼叫加上 Debounce 處理,成功提升頁面執行效率。

第五例是「異常高頻率的呼叫」。曾有一個交易的吞吐量特別高、遠遠凌駕其餘交易;仔細一看,發現癥結在於一個低變化頻率的 API 呼叫,因此後來經由簡單的處理程序,快取該 API 的內容,迅速讓此交易的吞吐量降回正常。

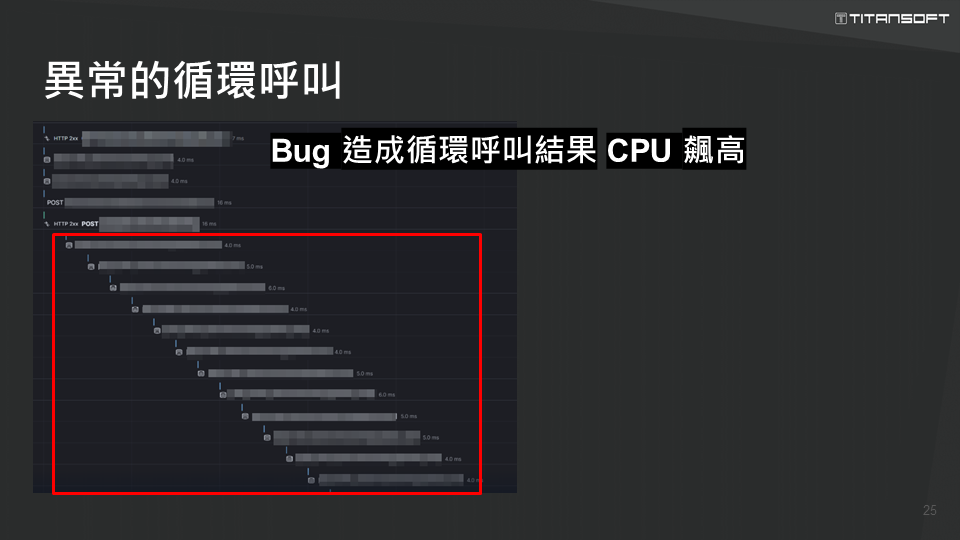
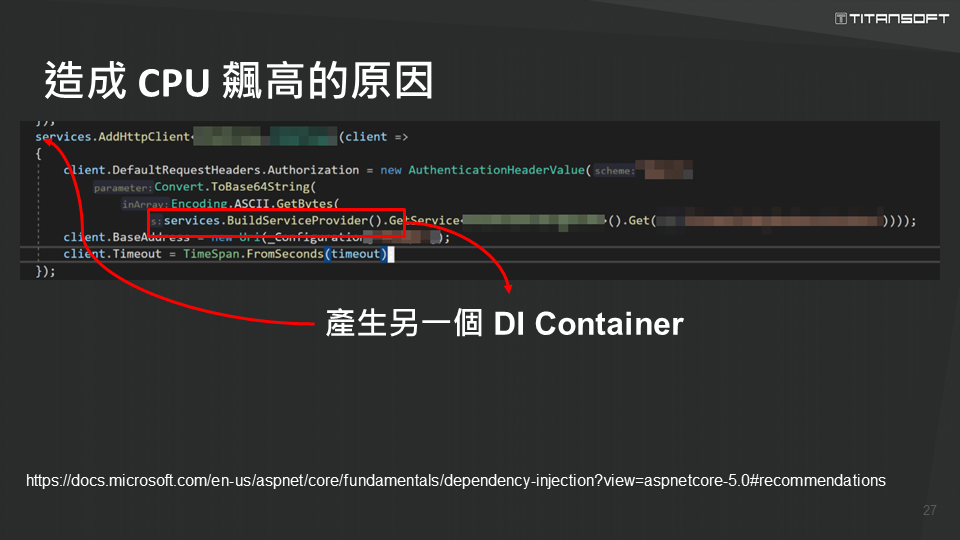
再來第六例是「循環的呼叫」。鈦坦在某次發佈新版本後,意外造成服務當機,原因為「High CPU」;查看 APM,得知此事件為一連串循環呼叫所致。接著查看相關程式,發現原來在撰寫這段程式碼時,不慎在依賴注入的地方觸發另一個產生依賴注入的容器,再重新做一次依賴注入,因而循環不止,導致 CPU 使用率飆高。後來轉換寫法,確保依賴注入時、不會再觸發另一次依賴注入的容器產生,圓滿解決難題。
第七例是「異常高的反應時間」,查看 APM 的延遲資訊,赫然發現一些 Peak 存在於Kubernetes(K8s)服務。接著回去查看 Grafana Monitor,證實有一些 K8s Pod 的 CPU 使用率異常飆高;詳加研究後,發現是 K8s ReadinessProbe 設定不佳所造成,使得即便 K8s Pod 越來越忙仍不斷接收服務端的請求。爾後調整 ReadinessProbe 設定,只要達到一定負荷,就不再繼續接收服務端傳來的請求。


無論哪套 APM 工具,都有助釐清問題、改善瓶頸
Norman表示,APM 提供的資訊非常豐富。如「Metrics」頁提供 CPU、Memory 資訊,讓使用者得以查看哪些時間點是系統的 Peak Hour;這些現象,也許是某次的發佈造成記憶體流失(Memory Leak)狀況,你只要查出這個版本,再回去修正問題即可。
此外在「Errors」頁,會記載所有錯誤狀況,以利使用者探究是否某個時間點後因為第三方服務不正常,或是上了某版本後有改錯東西,導致 Error 數量攀高。
「前面的例子,大多偏向後端服務,但其實 Elastic APM 有提供一些套件,讓你輕易整合前端服務。」 Norman說,此套件名為 RUM(Real User Monitoring),可讓 APM 幫你從使用者瀏覽器收集資訊,再傳送到 APM Server,你就可以在 APM 畫面看到類似 Chrome DevTools 裡的 Network tab 內容,得知每一段請求花費多少時間。
他並提醒企業在使用 APM 時,須特別注意環境設定,若設定有誤,可能造成資料混亂、影響分析結果。另須留意 Sample Rate 不要設得太高,以免過度消耗系統資源。此外 APM 對於框架版本的支援性,難免有所限制,例如在舊框架底下難以呈現太多交易細節;此時我們其實可以善用 APM 為自己定義的 API,藉由此 API 來定義你自己的交易與 Span,以便於依然使用 APM 去監控一些 採用舊框架版本的系統。
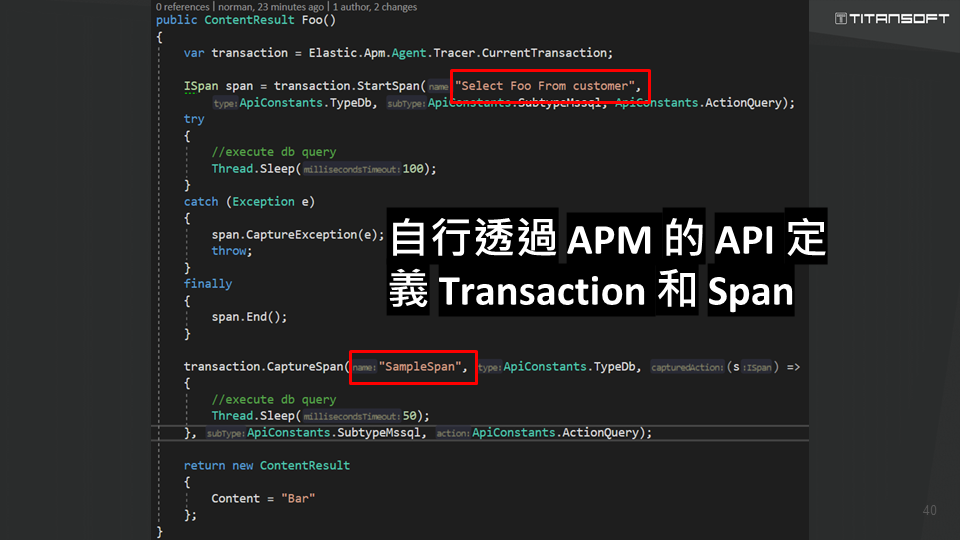

雖然本次演講內容以 Elastic APM 為主,但像是 OpenTelemetry 等類似工具,仍可以達到同樣效果,幫助你不斷監控系統,好讓你不斷做修改,有效解決每一個瓶頸。
想看更多鈦坦人的分享,歡迎到新加坡商鈦坦科技 YouTube 頻道並訂閱就不會錯過最新內容囉~
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10