")
Teradata技術長Stephen Brobst (圖片來源/Teradata)
「企業決策者多半浪費了90%的精力,來篩選、尋找有價值的數據」,曾被選為美國Top 4技術長的Teradata技術長Stephen Brobst如此說道。隨著AI風潮崛起,過去大力擁抱大數據分析的企業,紛紛轉向投入機器學習、深度學習技術。
但Stephen Brobst認為,企業對這些技術的運用方式,用錯地方。他認為,企業應該利用人工智慧和機器學習技術,來尋找對決策制定有影響的數據,而不是浪費大把時間來梳理數據。「這不是決策者該做的事。」
儘管調查機構Gartner預測,2020年時,超過3成CIO會將AI作為企業IT五大投資重點之一,但在Stephen Brobst看來,人工智慧只是一個市場行銷用語,他認為,許多企業CEO常把AI掛在嘴邊,認定AI能拯救公司,因此給出許多承諾,要用AI來改善各種現狀,不論目標實不實際,也要求公司CIO得實現這些承諾。「AI就像一把大傘,包羅萬象,但也可能什麼都不是。」他提醒。
就像Hadoop,也曾一度被企業視為是資料分析的銀彈,以為可以解決任何問題,後來發現也不盡然。他建議,企業得對人工智慧(AI)有正確的期待,必須先了解AI到底能做什麼、不能做什麼,而非對AI有過度期待,誤以為它就可以解決所有問題。
相較於沒有明確定義的人工智慧,機器學習是比較具體的技術。Stephen Brobst解釋,現今提到的機器學習,多半指的是線性數學,可用來歸類和預測結果,而且大多已是研究了數十年的資料探勘技術。
「人們對AI總有一種好萊塢式的想像,會問說機器能不能思考?」Stephen Brobst直接了當地回答:「不,機器不會思考。」他補充,比較適當的修正問法應該是,機器能不能仿照人思考特定問題的過程,來處理同樣的情況,「這個答案就會是可以,不過,只是有時,而非總是可以。」不過,靠機器來處理問題的好處是,可以比人更快、更便宜,甚至不用5秒就可以做出決定。
Stephen%20Brobst_TERADATA%E6%8F%90%E4%BE%9B.jpg)
企業得先了解AI能做什麼、不能做什麼,而非過度期待,誤以為AI可解決所有問題。── Teradata技術長 Stephen Brobst (圖片來源/ Teradata)
機器學習和深度學習的應用與工具
機器學習正是利用疊代學習技術,讓電腦可以從數據自動找出可用的趨勢和洞察,而不是靠人工定義明確的規則來尋找數據的意義。也因此,「機器學習技術的優點是快速、低成本和高準確率。」他說。
而深度學習,則是更進一步運用比機器學習更多層的神經網路,來分析數據,並從中找出模式。Stephen Brobst提到,深度學習可以容忍雜訊高的數據,也能夠整合看似不相關的數據來源,還能解釋數據中非線性的關係。甚至,他強調,深度學習有趣的地方,在於它的「自動化」。進一步說,深度學習具有自動抽取特徵(Feature Extraction)的能力,人們也稱之為特徵學習(Feature Learning)。
正因為深度學習適合用來分析複雜、高維度的數據,比如影像、音訊、影片、時間序列和文字檔等,或像是即時數據流、感測器數據等。也因此在各行業開始出現廣泛的應用,如在汽車業將深度學習技術用於自駕車的導航系統,利用深度學習圖像辨識的優勢,來識別路標、交通號誌和道路狀況等。而在高科技製造業,也能用深度學習技術辨識影像和音訊,來優化工廠營運。在醫療業也透過深度學習技術來判讀醫療影像,或是來尋找新藥組合。
不過,Stephen Brobst認為,深度學習最大的價值是這3個領域:預測配對、詐騙偵測和故障預測。第一個預測配對應用,指的是透過分析顧客過往的網路行為歷史,比如購買歷史或瀏覽歷史,進而預測、推薦顧客可能會需要的產品或服務。他舉例,不少零售業者利用深度學習技術,以數據為原料,來打造推薦引擎(Recommendation engines),成功讓特定類型產品的銷量增加了30%。
其次是詐騙偵測,Stephen Brobst解釋,由於詐騙人士常在網路活動中隱藏自己的足跡,但藉助深度學習用多層神經網路來分析複雜的數據,能夠找出這些詐騙人士的活動模式,進而有效偵測詐騙,而且「深度學習模型的預測力,比傳統線性數據分析模型要好上許多」。電信業、零售業和金融業等產業都可運用這類反詐騙偵測技術。知名第三方支付服務商PayPal,就是利用深度學習成功偵測出詐騙行為的例子。
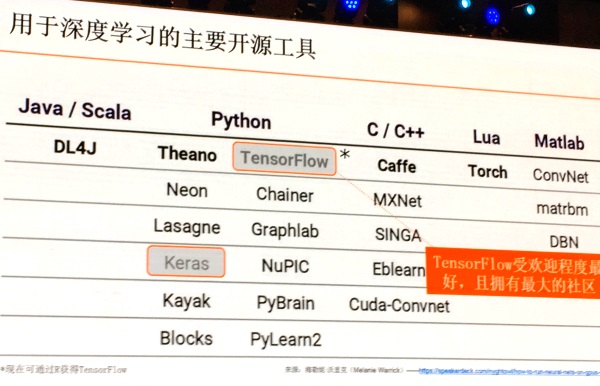
Teradata技術長Stephen Brobst列出了一份深度學習主要開源工具,這也是他認為企業想導入深度學習時可參考採用的技術。 (攝影/王若樸)
PayPal光是2017年交易量超過77億次,出色的成績也引來不少有心人士。PayPal透過深度學習技術來偵測詐騙行為模式,以過濾可疑的使用者或遭盜用的帳號。PayPal從支付交易歷史資料中,甚至還有使用者登入裝置,或是交易時的地理位置、IP地址和使用者帳戶資料等資料點,來建立詐欺行為特徵的模型,來分析每筆交易的細節,以判斷是否有詐騙或盜用情形。過去靠線性模型只能處理20到30個變數,但PayPal改導入深度學習技術後,可以處理到數千個資料點,更容易從大量資料中找出偵測模型。
Stephen Brobst舉的另一個例子是丹麥銀行的詐騙檢測系統,過去作法是先仰賴專家人工建立的規則引擎來篩選詐騙事件,再展開進一步調查,但這樣的篩選誤報率很高,導致後續調查費時費工,也只能順利找出4成的詐騙事件。有時銀行一天就會收到1,200件誤報事件(正常交易,但被規則引擎誤判為疑似詐騙交易),導致大多數調查工作都是做白工,也讓這些應該正常完成的交易,為了調查而暫停或延後執行,進而影響了不少顧客的生意。後來,丹麥銀行導入Teradata深度學習技術,以真實發生的詐騙案例為數據來源,來訓練誤報事件的判斷模型,讓報錯率大幅減少至少6成。隨著誤報事件的減少,詐欺調查資源也可以集中,進而提高了成功找出詐騙交易的比例。
此外,丹麥銀行還採取了「冠軍/挑戰者」(Champion/Challenger)的方法,透過不斷比較模型效果,來優化最終的深度學習預測模型。每個挑戰者(也就是每個模型)的預測表現若低於門檻,系統就會匯入更多資料,比如客戶的地理位置或最近ATM交易資料,讓挑戰者重新訓練新模型,不斷比較每個挑戰者的表現,並從中選出冠軍,來找出最有效率又最能避免報錯率的模型。最後,丹麥新的檢測系統可以分析每年數百萬次的交易行為,甚至尖峰時期可以分析每分鐘數十萬次的交易行為。
儘管在金融業,運用深度學習來進行詐騙偵測頗有效果,不過,Stephen Brobst認為,深度學習運用最有成效是第三個應用領域,也就是故障預測。他解釋,透過感測器蒐集到的數據,比如IoT裝置的數據流、工廠機器感測器數據,或是自駕車和飛機引擎感測器的數據等,然後以深度學習演算法分析,可用來預測機器什麼時候會故障,並因此提早維修,避免事故發生。這些用來分析的感測器數據,不論是簡單的溫度、壓力和功耗數值,或是複雜的機器運轉聲音等非結構化資料,都可以放進深度學習模型中訓練來進行預測。
儘管深度學習在以上三方面表現突出,但卻不代表它是萬用金鑰。Stephen Brobst表示,「深度學習雖然是解決問題的好方法,卻不見得是最好的方法。」結合淺層學習和深度學習來解決問題,也未嘗不是個好辦法。他進一步解釋,淺學習與深度學習的結合,就是線性數學模型與非線性模型的結合,而線性模型可用來完成簡單任務,比如在網購上用淺層學習,就足以預測顧客挑襯衫會順便看領帶,所以,系統應推薦幾款領帶給顧客。但是,「若要進一步依據不同顧客的偏好,更精準推薦領帶的款式,實現個人化行銷,就得用到深度學習的非線性模型來分析。」他說。
在對機器學習和深度學習的能力有所了解後,才能給予合理的期待。下一步就是要知道,有哪些工具適合打造深度學習模型?Stephen Brobst表示,開源機器學習框架TensorFlow就是一個廣受歡迎的工具,因為它可適性強,可以應用在不同設備或環境上,不論是雲端、移動裝置或使用CPU和GPU都支援,也支援多種語言,如Python和C/C++。而其他開源框架,他也推薦兩個開發人員愛用的工具,適合訓練CNN的Caffe和RNN的Torch。
而以資料倉儲起家的Teradata,Stephen Brobst表示,近來在深度學習的布局也正是鎖定第三個應用領域,在自家數據分析平臺(Teradata Analytics Platform)上,最近推出了4D Analytics功能,主打IoT邊緣裝置的數據分析。
這套分析平臺的4D Analytics,是指在原本的3D空間位置數據外,還加上了第四維度的時間,讓使用者可以在Teradata分析平臺上處理地理空間、時態和時序數據。由於許多感測器的數據會隨著時間不斷有微妙變化,比如飛機每次起飛的高度,但人們常忽略這些變化,而4D Analytics就像一連串的截圖分析一樣,來呈現不同感測器在不同時間的數據。例如可分析一段時間內,地鐵、計程車或餐廳人潮的變化,作為智慧城市發展的參考,或是分析穿戴裝置或醫療設備上的心跳變化數據等。
用開源框架LIME來面對不可解釋性的挑戰
不過,雖然深度學習可帶來精準預測,但卻有不可解釋性的問題。Stephen Brobst表示,一般線性數學有公式可以解釋預測結果,但由於深度學習由層層神經網路堆疊而成,涉及非線性數學,而其中又有許多隱藏層,就像黑盒子一樣,無從理解演算法運作的原理。也因此,人們對於深度學習演算法做出的決策,會抱持懷疑態度,像是在金融業等,對可解釋性就有嚴苛的要求。而在醫療方面,Stephen Brobst舉例,雖然已知某套演算法的判斷能力通常比人要好,但當它告知醫生該給某位病人截肢時,醫生還是會質疑,或是不願意做,因為他們不了解系統下決策的原因。
然而,面對不可解釋性的挑戰,Stephen Brobst表示,現在也有一些方法用來加強深度學習的可解釋性,其中一個就是華盛頓大學開發的開源框架LIME(Local Interpretable Model-Agnostic Explanations)。LIME試圖透過一些局部保留、取樣的作法,嘗試建立一個較可理解的解釋層,例如用簡化模型來描述深度學習模型所抽取的特徵,來幫助解釋為何某些特徵比較重要。丹麥銀行的防詐騙深度學習模型也應用了LIME框架在深度學習模型上增設了一個解釋層,來說明諸如封鎖某交易的原因,提高透明性來爭取顧客信任。
CTO小檔案
Teradata技術長Stephen Brobst
學歷:MIT電腦科學暨人工智慧博士
經歷:1999年進入Teradata,現為該公司技術長,主導產品技術研發,2014年時更入選為美國Top 4技術長。加入Teradata前,他則是一位連續創業家,創立過Tanning、NexTek和Strategic科技系統等三家專注於資料庫技術的新創。不只業界經驗豐富,也曾任教於波士頓大學和麻省理工學院。
Teradata.jpg)
公司檔案
Teradata
● 成立時間:1979年
● 主要業務:提供客戶大數據分析、資料倉儲和整合行銷管理解決方案
● 總部:美國俄亥俄州
● 全球員工數:11,100人
● 年營收:約21.6億美元(2017年)
● 總裁兼CEO:Victor Lund
公司大事紀
● 2014年:併購Think Big Analytics
● 2016年:推出Teradata Everywhere服務
● 2017年:發布Teradata分析平臺
● 2018年:在分析平臺中,新增4D Analytics功能
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09

2026-03-06