因應巨量資料市場崛起,微軟曾經一度自行研發非結構資料技術,然而,Hadoop的發展迅速形成氣候,迫使微軟改弦易轍,再次向開源軟體靠攏。微軟全球資深副總裁張亞勤表示:「微軟將全面支援Apache Hadoop,從資料處理平臺底層到前端的資料分析工具,微軟都將與Apache Hadoop充分整合,這是微軟現階段的長期發展策略」。
微軟在決定支援Hadoop之前,曾經嘗試過各種組合與可能,美國總部針對非結構資料的研發專案,甚至不只一個。但是,Hadoop的演進快速,儼然成為非結構資料處理的標準,以Apache Hadoop為基礎所開發的巨量資料解決方案,目前就有Hortonworks以及Cloudera兩大商用版本,相關的延伸應用套件與工具也越來越多,逐漸朝完整的生態體系進化。
張亞勤表示,微軟的搜尋技術Bing,原本就有MapReduce分散運算的概念,但是,越來越多的企業開始使用Apache Hadoop,已經是不爭的事實。因此,在非結構資料的企業解決方案上,微軟選擇支援Apache Hadoop,並且視Apache Hadoop為非結構資料處理架構的核心,讓企業可以在Windows環境中,也能處理Hadoop平臺的非結構資料。
目前微軟已經推出Hadoop on Windows Server以及Hadoop on Windows Azure預覽版本。在微軟的巨量資料處理架構中,一方面是把Hadoop與SQL Server等做一個整合,另一方面則是把Hadoop當作一個服務,透過Windows Azure雲端平臺來提供巨量資料服務。
此外,由於Apache Hadoop的技術,現階段還無法因應即時動態資料分析,因此,微軟將以自行開發的StreamInSight技術,來因應動態資料分析需求,例如:感測資料分析等。
巨量資料是雲端時代的殺手級應用
張亞勤表示,個人電腦時代的殺手級應用,如果是Windows作業系統,那麼,雲端時代的殺手級應用,就是巨量資料(Big Data)。資料成長的速度愈來愈快、種類愈來愈多,過去2年新增的資料量,就占了所有資料量的9成,面對爆量的資料成長速度,「能夠剖析資料,來協助企業做出決策的巨量資料技術,將會成為雲端時代的殺手級應用。」
巨量資料的應用技術,已經顛覆傳統的資料分析思維。過去,企業必須先理解資料之間的關係,才能依據分析需求,把資料儲存到資料庫。但是,巨量資料技術的突破,在於不需要事先建立資料關聯,就能進行儲存與分析。這個轉變,讓資料分析的範圍,得以從結構資料延伸到非結構資料,而且有效地提升了商業決策的精準度。
張亞勤表示,巨量資料的應用才剛剛開始浮現,巨量資料的商業價值與應用特性,將會是未來幾年的發展重點。過去,網際網路的發展,從Intranet到Internet,Web技術扮演著非常關鍵的角色。如今,在巨量資料的應用上,Hadoop在非結構資料的技術價值,就像是Web一樣。
微軟巨量資料平臺架構
在微軟的巨量資料處理架構中,一方面是把Hadoop與SQL Server等做一個整合,另一方面則是把Hadoop當作一個服務,整合到Windows Azure雲端服務中。目前並已推出HDInsight Server for Windows以及Windows Azure HDInsight Service兩大預覽版本。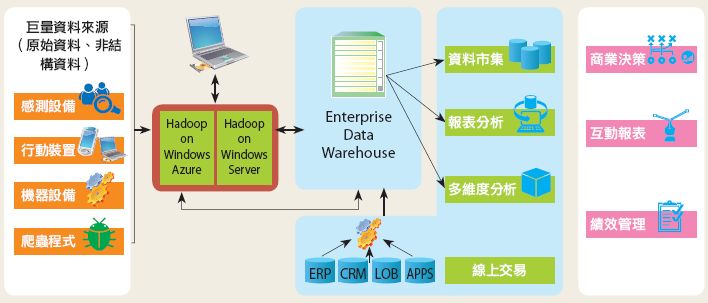 以Hortonworks Platform 1.1為非結構資料分析的核心
以Hortonworks Platform 1.1為非結構資料分析的核心
為了因應非結構資料,微軟決定支援Hadoop。台灣微軟營運暨行銷事業群資深協理周旺暾表示,微軟與Hadoop平臺的整合,具有幾項重要特色,包括可以SQL Server直接支援Hadoop,可與微軟Office等前端應用整合,可以單一平臺管理結構資料與非結構資料,可以充分整合Azure雲端平臺與Azure Store的資源。
目前主要是以Windows Server以及Windows Azure兩大平臺作為基礎,同時並以Hortonworks Platform 1.1為非結構資料分析的核心,在 Windows Server與Windows Azure內建Hadoop,來達到結構資料與非結構資料的跨平臺分析。微軟將Hadoop內建於Windows Server以及Windows Azur後,已經推出HDInsight Server for Windows以及Windows Azure HDInsight Service預覽版本。
其中Hadoop on Windows Server,除了內含Hadoop的重要元件,包括HDFS檔案系統以及MapReduce運算元件之外,還有Pig模組、Hive模組以及其他資料處理工具,同時並進一步整合微軟的系統監控工具System Center。此外,Hadoop on Windows Server也能在微軟Hyper-V虛擬化環境中執行。為了讓Hadoop環境的元件,都能順利在Windows Server與 SQL Server上執行,相關元件甚至都經過Hortonworks進行最佳化調整。
Hadoop on Windows Azure則是針對雲端平臺所提供的巨量資料服務,讓企業可以在雲端平臺,快速部署企業專屬的巨量資料平臺,或將資料上傳到雲端平臺上分析。周旺暾表示,目前微軟並沒有特別針對巨量資料這項服務,祭出新的價格策略。既有收費模式,主要是依據輸出的資料傳輸量、資料儲存量以及處理器使用量來收費。
相較於其他資料處理廠商,微軟更加強調混合雲的應用模式,主要是因為企業的非結構資料成長與分析需求,企業本身現階段還不容易掌握,資料處理平臺的軟硬體配置,也相對不容易規畫,這樣的前提下,周旺暾認為,企業可以用Hadoop on Windows Azure雲端平臺來做巨量資料分析的平臺,是較具成本效益的做法。
周旺暾表示,Hadoop on Windows Azure預覽版本,已經開放免費下載,使用者申請帳號後,只要完成開通程序,就能立即使用。不過,由於考量到測試環境的資源配置,現階段採取的是批次放行策略,用戶須等待核可後才能使用。
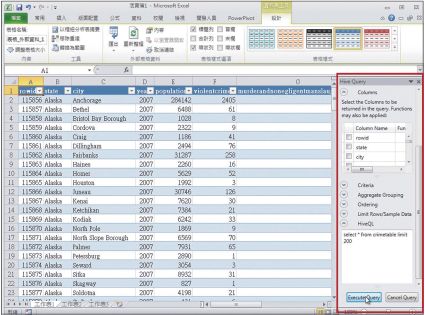
Excel的使用者,可以ODBC讀取Hadoop資料
不論是Hadoop on Windows Server或Hadoop on Windows Azure都可以讓Excel的使用者,在Excel介面下,讀取Hadoop平臺的資料,進而在Excel環境下,整合分析結構資料與非結構資料。目前相關應用將支援Excel、PowerPivot for Excel以及Power View等工具。
周旺暾表示,使用者只需要完成安裝Hive ODBC驅動程式,就可以在Excel的操作介面上,看到新增功能Hive Query,並且在下拉選單中,輸入要分析的資料源,也就是Hadoop平臺的資料路徑,就可以在Excel環境中,以ODBC模式,讀取Hadoop平臺的資料,分析結果則以資料表(Table)或Cube形式,儲存在Excel或SQL Server。文⊙楊惠芬
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09