MIT
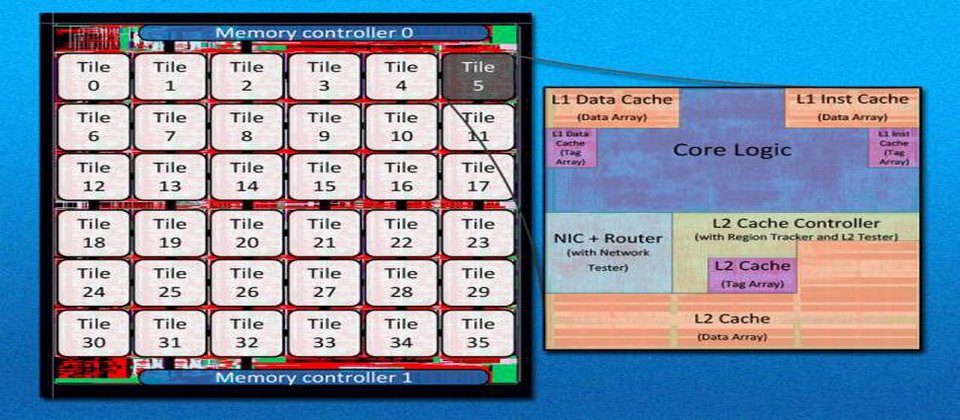
新一代處理器核心數越來越多,但核心間的資料交換複雜度也越高,成為了超多核心處理器提升效能的瓶頸。近日,在國際計算機架構大會(International Symposium on Computer Architecture,ISCA)上,麻省理工研究人員則公開最新開發的36核心處理器優化技術和實作成品,在處理器內部增加了資料路由排序機制,解決核心數越來越多後,衍生的快取一致性和執行效能問題。
(完整論文全文)
一般處理器核心與核心之間,主要是透過單一資料匯流排(bus)來進行溝通,好處在於透過snoopy協定,可讓核心與核心在溝通時保持快取資料一致性,壞處是當兩個核心溝通時就會占用資料匯流排,導致其他核心必須延遲等待,而隨著核心數量越多時,等待問題也就越明顯,往往也就容易造成多核處理器執行效能不彰。
不過麻省理工研究團隊則是找到新方法來改善這個問題,該校電氣工程和計算機科學教授Li-Shiuan Peh表示,儘管目前已有不少針對多核心處理器的晶片網路機制(network-on-chip)進行的研究,不過該研究小組則是在此晶片網路機制下加入一個具「迷你路由」功能的影子網路(shadow network),以解決多核心快取一致性和延遲等待問題。
根據研究小組成員Bhavya Daya指出,在這個晶片網路機制下,每顆核心都能迅速與它相鄰核心進行溝通,而不同的核心之間則可透過影子網路(shadow network)方式溝通,每當核心接收到相關聯的核心對主網路發出請求時,就會經由影子網路的節點找到最佳資料傳遞路徑讓其迅速通過,以減少其他核心執行時的等待周期時間。
而核心內的迷你路由功能,也能紀錄下每顆核心到達另一顆核心的時間間隔,讓核心之間的資料傳送變得更加有序,經由這種資料傳遞方式也能解決過往多核心與快取一致性問題,而隨著核心數量越多,也代表可供連結路徑也變更多,也能提升核心之間的使用率。
此外,在處理器晶片內的影子網路也具備有分層優先權機制,以36核心來說,在一間隔時間,核心1與核心10同時皆發出請求時,核心1擁有較高的優先權,此時,儘管處理器的路由可能先收到核心10發出請求,但仍然會等核心1的資料封包通過後才會執行核心10的請求,不過每隔一段時間晶片內的核心優先等級就會被重新洗牌標註不同優先權,確保能作為長久使用。
另外,根據研究人員的測試結果也發現,在進行模擬36核心以及64核心測試環境時,採用此晶片網路技術的處理器比起沒採用的處理器,在效能分別提升了將近24.1%與12.9%。
不過Bhavya Daya也指出,目前這種高效能36核心處理器還在原型測試階段,接下來該研究小組將會進行調整,並改套用在Linux系統中測試其效能表現。未來,MIT也有意計畫以Verilog的硬體描述語言方式,將此晶片技術的開放原始碼分享出來,讓更多人共同參與開發。
2014/6/25更正說明:原文提及MIT新發表的36核心處理器,顛覆傳統處理器架構,且是多核心處理器技術的大變革敘述有誤,正確應為MIT提供一個新的晶片網路(Network-On-Chip)架構方法,可在多核心之間建構一個具 「網路優先順序」的路由功能網路,用以解決多核心間的快取一致性,進而提高多核心的使用率來優化處理器效能。(內文已更正)
另外原提及核心與核心之間的「溝通」,但並未說明其溝通方式,完整為在核心之間透過單一匯流排來溝通,符合Snoopy協定快取一致性,而當核心數越多時,核心間快取一致性就會發生問題,造成處理器執行上的等待延遲越長。(內文已補充)
熱門新聞

2026-03-06


2026-03-11

2026-03-12



2026-03-10