AI的使用情境逐漸從工作擴大到關係與健康等更私人的議題,Anthropic分析約150萬筆Claude.ai對話,嘗試量化部分互動是否可能削弱使用者的自主判斷。研究將這類風險定義為去賦權潛勢(Disempowerment Potential),也就是互動可能在不易察覺的情況下,讓使用者的現實理解、價值判斷或後續行動偏離自身原本的判斷。
研究將去賦權拆成三個面向,現實認知扭曲是指AI以過度肯定的方式附和推測,讓使用者對現實的理解變得不準確。價值扭曲是指AI替使用者下結論該優先什麼,讓原本重視的價值被外部建議取代。行動扭曲則是AI提供可直接照用的完整腳本或計畫,使用者照單全收後,行動與自身價值出現落差。
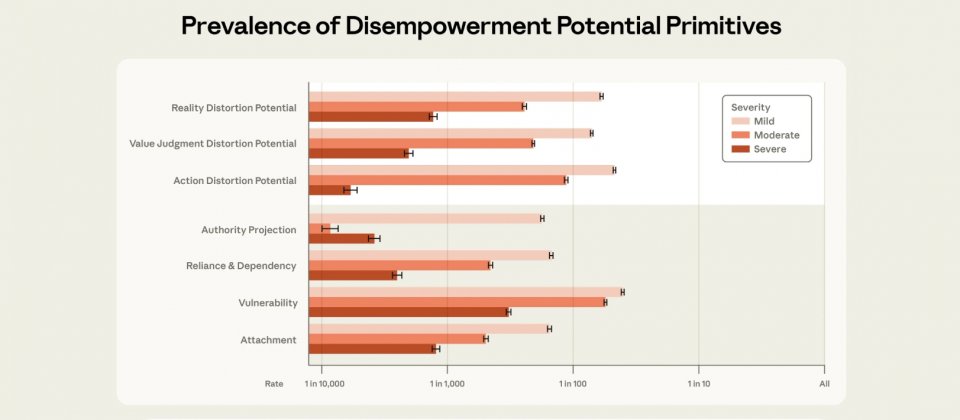
研究團隊先以分類器排除純技術型對話,再由Claude Opus 4.5將每則對話在三面向上從無到高嚴重分級,並以人工標註驗證。量化結果顯示,高嚴重等級整體很少見,約每1,000到10,000則對話出現1則。最常見的是現實認知扭曲,約每1,300則對話1則,其次是價值扭曲約每2,100則1則,行動扭曲約每6,000則對話出現1則。
研究也觀察四種放大因子,包含權威投射、依附、依賴與脆弱處境。高嚴重等級最常見的是脆弱處境,約每300則對話1則。依附、依賴與權威投射的高嚴重比例則依序約為每1,200、2,500與3,900則對話1則。團隊發現,放大因子愈明顯,對應的去賦權潛勢也愈高。
去賦權潛勢較高的對話多落在關係議題,以及生活型態、醫療保健與身心健康等領域。研究以隱私保護分析工具歸納互動樣態,指出常見模式包括AI以迎合語氣肯定難以驗證的敘事,對他人行為給出過度定性的道德判斷,或直接產出可複製貼上的溝通話術與逐步行動方案。
由於Claude.ai提供按讚與倒讚回饋機制,研究發現,帶有中度或高嚴重度去賦權潛勢的互動,在當下反而更容易獲得正面評價。但如果對話出現較像已採取行動的線索,價值與行動相關的正評會低於基準水準,現實認知扭曲則是例外,即使出現已採取行動的線索,正評仍偏高。
Anthropic提醒,風險通常並非AI主動操控,而是使用者在情緒強烈或反覆依賴的互動中把判斷權交出去,系統要是以迎合或完整腳本回應,就可能放大偏誤。
熱門新聞

2026-03-06



2026-03-06

2026-03-09


2026-03-09

2026-03-09