Anthropic
重點新聞(0109~0115)
Claude Code MCP Token
還沒寫程式就沒Token了?Claude Code新功能解決MCP擴充痛點
Anthropic為旗下程式開發工具Claude Code推出新功能MCP Tool Search,來解決多數開發者的共同痛點:MCP工具一多,Context很快就被吃光,還沒開始寫程式就先用完token了。
Anthropic技術人員Thariq Shihipar在X上說明,當Claude Code偵測到MCP工具描述占用超過10%的Context時,系統就不再把所有工具一次載入,而是改用搜尋方式動態載入。也就是需要時才找工具,避免事前預載造成浪費,等同替MCP伺服器加入延遲載入機制。
Anthropic指出,過去有使用者同時接了超過7個MCP伺服器,就耗掉6.7萬多個 token,Context在真正開始工作前就已用完。但新機制可以大幅改善這個問題。在實作上,MCP Tool Search是一個相似度搜尋工具,輸入關鍵字即可回傳相關工具名稱。由於它本身也是代理流程的一部分,Claude Code可以多次搜尋、調整關鍵字,甚至平行查詢,直到找到合適工具。(詳全文)
Falcon-H1R 小模型 推理
不靠堆參數,Falcon-H1R用7B小模型挑戰大型推理AI
阿聯酋科技創新研究院(TII)最近發表Falcon-H1R 7B,是一款主打輕量但具高推理能力的開放權重大型語言模型。Falcon-H1R僅有70億參數,卻以架構和訓練策略取勝,對標更大規模的開源和閉源模型。
Falcon-H1R以Falcon H1架構為基礎,結合了Transformer和Mamba架構,針對多步推理進行強化訓練,讓模型在數學、邏輯和代理任務中,更有效率地使用參數。TII公布的測試結果顯示,Falcon-H1R在AIME-24等推理基準上,表現可逼近甚至超越部分15B、32B規模的模型。
除了準確度,效能也是重點。官方測試顯示,Falcon-H1R在實際部署情境下的推理速度明顯快於Qwen3 8B,而且越忙、輸入越長時,差距越大。比如一次同時處理32個請求,Falcon-H1R每張GPU每秒可產生約1,000個Token;請求數增加到64個時,速度可提升到約每秒1,500個Token,是Qwen3 8B模型的兩倍。當輸入內容拉長到8,000~16,000個Token(例如整份文件或長推理流程),Falcon-H1R的速度仍可維持約每秒1,800個Token,而Qwen3 8B則低於 每秒900個Token。
Falcon-H1R這樣的推理速度,對實務部署相當友善,特別適合要即時推理、又受限於算力的場景。Falcon-H1R以開放權重方式釋出,並提供完整技術文件,延續Falcon系列高效能、可部署、可研究的定位。(詳全文)

自主型AI Cowork Claude
Anthropic揭自主型AI代理,瞄準知識工作
Anthropic推出自主型AI代理Cowork,把Claude的功能從聊天、寫程式,擴展到一般知識工作。Anthropic形容,Cowork就是「非工程師版的Claude Code」,能在少量人為介入下,自行規畫並完成多步驟任務。
與一般聊天介面不同,Cowork可存取使用者指定的電腦資料夾,直接讀檔、改檔與產出文件,並在過程中回報進度,不必每一步都下指令。官方舉例,它能整理下載資料夾、把支出截圖轉成試算表,或從零散筆記生成報告初稿。
在實測中,《Lenny’s Podcast》主持人Lenny Rachitsky讓Cowork分析320份逐字稿,成功整理出關鍵主題。Cowork也能分析本地端的會議紀錄、產生摘要,搭配行事曆與瀏覽器完成跨應用任務。Cowork目前以macOS研究預覽版提供給Claude Max訂閱者。(詳全文)
Cursor AI代理 協作
Cursor實驗多代理協作自動寫程式,從零打造瀏覽器
AI程式開發新創Cursor最近分享一項實驗成果,他們運用幾百個AI代理,在同一個專案連續工作好幾周,將原本需要人類團隊好幾個月才能完成的工程,一口氣平行推進。
在這個專案中,AI代理累積寫出100多萬行程式碼、用了數十億個token,整個系統已能以周為單位,穩定運作。Cursor也發現,真正的難題不是算力,而是如何避免AI彼此重複做事、互相卡關。為解決這個挑戰,團隊先定義分工,由「規畫者」負責分析程式碼、拆任務、排順序;「執行者」照指示把程式寫完、送出修改。每一輪任務結束後,再交給「裁判AI」判斷要不要繼續下一輪。
他們也實際測試,像是從零打造一個網頁瀏覽器,或把前端框架從Solid換成React,都能連續跑好幾周不中斷。團隊也發現,模型選得對很重要,像GPT-5.2在長時間任務中比較不會失焦,因此改為依角色搭配不同模型。不過Cursor也坦言,這套多AI協作還沒到完美,仍需要定期重啟、調整節奏。但整體來看,AI 寫程式已開始從單一助手,走向一整個工程團隊。(詳全文)

醫療AI Anthropic GenAI
進軍商用醫療AI領域,Anthropic推醫療B2B服務
Anthropic最近推出Claude for Healthcare,這不是AI看診服務,而是把生成式AI導入醫療行政與臨床試驗等內部流程,鎖定醫院、保險公司和藥廠等B2B市場的服務。Anthropic也宣告,Claude已具備進入正式醫療流程的商用成熟度。
Anthropic強調,Claude for Healthcare依美國HIPAA法規設計,可在合規前提下處理高度文件化、錯誤成本高的工作,例如事前授權審查、理賠文件整理、給付規範與臨床指引比對,以及醫師與機構資格驗證,這些正是醫療體系長期的人力黑洞。同樣能力也能延伸到生命科學領域,比如支援臨床試驗設計、收案與法規文件準備。
實例顯示,部分流程可節省最多90%的時間,像臨床試驗文件處理從數天縮短到1小時,製藥大廠Novo Nordisk的臨床文件處理更從12周減至10分鐘。Anthropic強調,Claude for Health的定位是降低錯誤、輔助流程,而非提供診斷建議;不確定時會交由人工審核。目前該服務已部署於AWS、Google Cloud和微軟雲端。(詳全文)
資策會 趨勢預測 GenAI
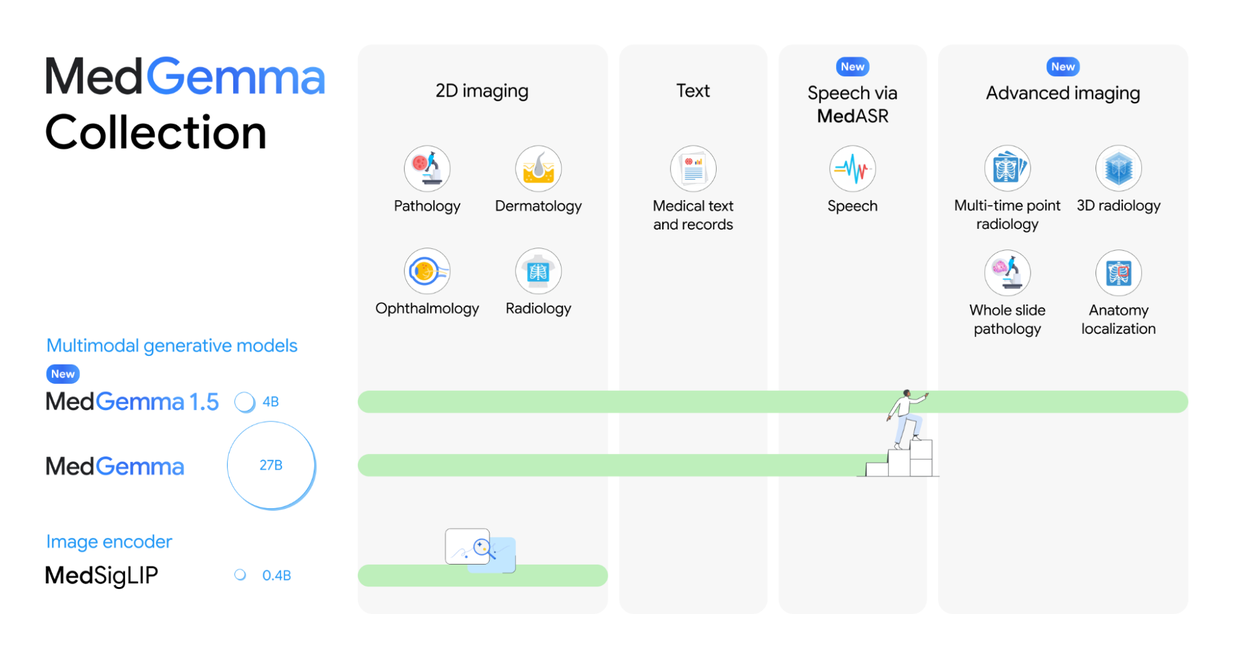
Google升級醫療多模態模型MedGemma,可讀3D影像了
Google最近更新開放權重醫療生成式AI模型MedGemma 1.5,同時推出醫療語音轉文字模型MedASR,要讓開發者更容易把影像、文字和語音,帶進醫療AI應用流程。
Google先提醒,MedGemma 1.5並非直接安裝就能看病的成品,在實際上線前,醫院或廠商仍得用自家資料微調、驗證。Google這次釋出的是4B多模態版本,模型較小、所需的算力也比較省,適合拿來評估或做客製化應用。如果要執行更複雜的文字任務,使用者仍可選擇27B參數的MedGemma 1。
技術上,1.5版最大的進步是能處理電腦斷層(CT)、MRI這類3D醫學影像,甚至是容量非常大的病理切片,只要將把影像切成多個區塊或多張切片,再搭配提示詞一起丟給模型,就能處理。Google內部測試顯示,3D影像判讀準確率確實提升,如CT的宏平均準確率由58.2%提升到61.1%、MRI則由51.3%提升到64.7%。
在系統整合上,Google 也補齊DICOMweb影像傳輸標準流程,讓應用可直接用連結在伺服器端讀取CT、MRI,再交給模型推理,不必來回傳輸龐大的影像。至於MedASR則是為醫療口述特別調教的語音辨識模型,針對醫療名詞和說話習慣優化,錯誤率明顯低於通用模型,適合用於醫師對話聽寫,後續再整理或進行AI分析。(詳全文)
DeepSeek 殘差網路 資訊丟失
DeepSeek提出新方法,穩住深層模型的訊號傳遞
DeepSeek發表最新研究,釐清一個常被混為一談的問題:大模型推理變弱,未必是記不住,而是資訊在深層網路中傳遞失真。團隊證明,一種原本潛力高、卻在大規模下不穩定的神經網路設計,經過調整後可穩定訓練,並能實際提高模型表現。
這項研究提出受限超連結(Manifold-Constrained Hyper-Connections),讓模型能在多條殘差路徑間動態混合資訊,提高推理彈性。這種設計本來能提高推理彈性,但在模型變深、變大後,常因訊號被過度放大或壓縮,導致梯度不穩、訓練直接失敗。
DeepSeek的作法是在混合路徑加上約束,只允許重新分配資訊、避免訊號放大,確保推理線索能穩定走完整個網路深度,來避免已學到的資訊,在深層模型中被沖淡。實驗顯示,模型可穩定訓練至270億參數規模,在基準測試BIG-Bench Hard中的準確率,由43.8%提高到51.0%,訓練成本僅增加6–7%。DeepSeek指出,未來推理能力的突破,可能更多來自架構層級的精修,而非單純把模型做得更大。(詳全文)
圖片來源/TII、Cursor、Google
AI近期新聞
1. Google推出個人化Gemini功能 可從Gmail、搜尋、相簿擷取資訊
2. 微軟釋出全球AI使用報告,臺灣AI採用率為全球第23名
資料來源:iThome整理,2026年1月
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09


2026-03-09