OpenAI
OpenAI周二(12/16)發表全新研究基準FrontierScience,用於評估AI在物理、化學與生物等領域中,執行專家級科學推理與研究任務的能力。
OpenAI解釋,一項由博士級專家撰寫的科學基準GPQA在2023年11月推出時,GPT-4僅獲得39%的成績,低於人類專家70%的平均值,但2025年的GPT-5.2在GPQA已拿到92%。顯示出模型能力的快速進化,已使既有以選擇題為主、難度趨於飽和的科學評測,不足以用來衡量AI是否真能加速科學研究。
由物理、化學及生物領域專家撰寫並驗證的FrontierScience基準測試,包含了數百道具備高難度、原創性與實質意義的題目,它設計了兩種不同的測試方向,一是用來衡量奧林匹亞競賽風格之科學推理能力的Olympiad,它是由國際奧林匹亞競賽獎牌得主設計的短答題,用於評估模型在受限條件下,是否能進行精確、嚴謹且可驗證的科學推理。
二是衡量真實世界科學研究能力的Research,它由博士級研究人員設計,題型為多步驟、開放式研究任務,要求模型分析問題、展開推論並給出完整解釋,並透過10分制量表評估其推理過程與結論是否合理。
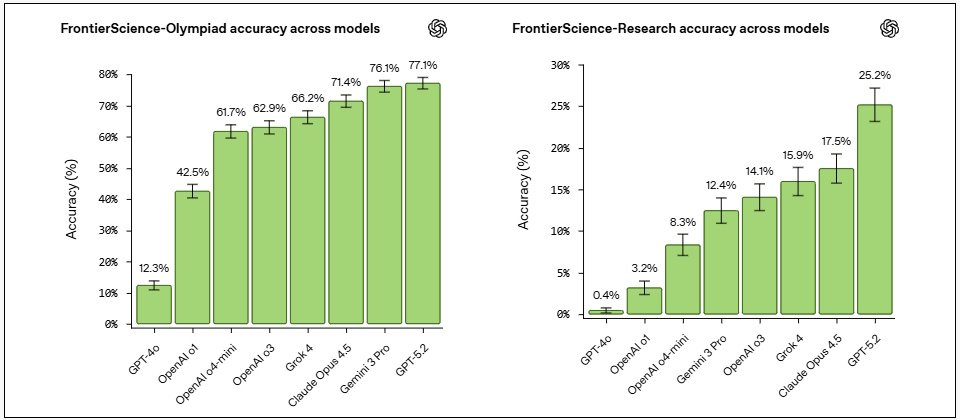
GPT-5.2在Olympiad的得分為77%,領先Gemini 3 Pro的76.1%、Claude Opus 4.5的71.4%與Grok 4的66.2%;在Research的得分為25%,大幅領先Claude Opus 4.5的17.5%、Grok 4的15.9%,以及Gemini 3 Pro的12.4%。對科學家而言,這代表現有模型已能支援研究中涉及結構化推理的部分,但在開放思考方面仍有大量改進空間。
OpenAI認為,衡量AI科學能力最重要的標準,應是它能促成多少全新的科學發現,FrontierScience並非最終驗證工具,用來在研究成果出現之前,檢視模型推理能力進展、辨識不足之處的評測基準,協助研究團隊確認模型是否朝正確方向發展。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-09


2026-03-06

