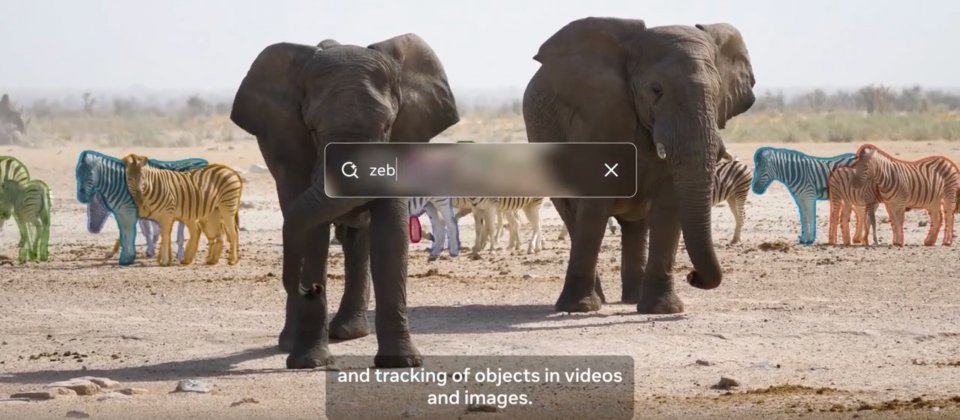
Meta發表新一代影像理解模型SAM 3(Segment Anything Model 3),並同步推出針對3D世界的SAM 3D,讓原本聚焦二維影像分割的技術,延伸到物件偵測、影片追蹤與3D重建。官方開放SAM 3模型權重、研究論文與微調程式碼,並推出Segment Anything Playground,讓研究人員與內容創作者都能在瀏覽器中直接試用。
SAM 3最大的變化是讓使用者可用短提示詞提示分割,例如條紋紅色雨傘或手上沒有拿禮物盒的人,要求模型在影像或影片中找出所有符合描述的實體,替每個實例產生遮罩並維持追蹤ID,要是目標難以用文字描述,也可以提供示例影像,讓模型比對外觀。
Meta建立結合AI與人工標註的資料引擎,來實作開放詞彙概念的分割能力。系統先由SAM 3與Llama系統從大量影像與影片中自動產生文字標籤與候選遮罩,再交由人工與AI標註器驗證與修正,總共建構出涵蓋逾四百萬個獨特概念的訓練資料,並提出SA-Co(Segment Anything with Concepts)評測基準,讓社群在同一套大詞彙分割任務上比較模型表現。
和前一代SAM 2相比,SAM 2核心任務仍以可提示視覺分割為主,強調透過點擊或框選,在影像與影片中建立遮罩片段(Masklet)並維持同一物件跨影格的一致性。SAM 3延續這套記憶設計與SAM 2風格的遮罩片段,但前端加上Meta Perception Encoder負責文字與影像編碼,偵測部分則採用DETR架構,整體重組為單一模型,同時處理概念偵測、分割與追蹤。
官方強調,在自家SA-Co評測基準上,SAM 3相較現有系統有明顯優勢,在SAM 2原本的互動視覺分割任務上,多數指標也能與SAM 2持平甚至更好,同時維持毫秒等級的推論時間。
Meta同時推出SAM 3D,把分割物品的能力延伸到實體場景,可以從單張影像推估一般物件與人類姿態與體型的3D結構。Meta已將SAM 3與SAM 3D導入Facebook Marketplace的View in Room功能,先用SAM 3分割出桌子、燈具等商品,再透過SAM 3D將物件放入使用者房間照片中,協助預覽風格與尺寸是否合適。
Segment Anything Playground則是這些模型的應用展示,使用者可以上傳影像與影片,直接套用範本,系統會自動替臉孔、車牌或螢幕馬賽克處理,也能替指定物件加上聚光、運動軌跡與放大效果。
熱門新聞

2026-03-06


2026-03-11

2026-03-12



2026-03-10