
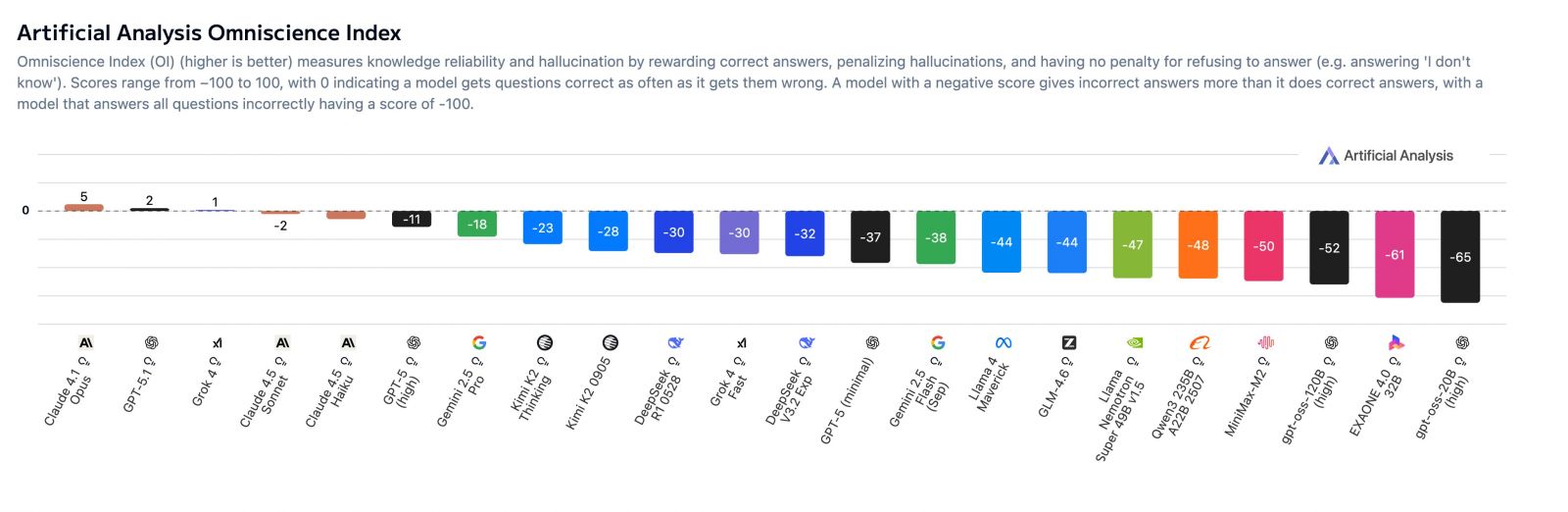
英國AI研究與評測公司Artificial Analysis於周一(11/17)發表全新的幻覺基準測試AA-Omniscience,用以衡量模型在知識覆蓋度與誠實自我校準(避免亂猜)之間的平衡。該測試除了計算模型的準確率外,若出現幻覺則會扣分,因此只有Claude 4.1 Opus、GPT-5.1與Grok 4等3款模型的得分高於0,其餘皆為負分,顯示多數模型在高難度題目中給出錯誤答案的機率,仍高於正確答案。
Artificial Analysis指出,語言模型的內嵌知識對許多實際應用至關重要,若缺乏知識,模型容易作出錯誤假設,無法於真實情境中運用,儘管可藉由網頁搜尋補強,但至少必須知道該搜尋什麼;看似事實的幻覺是信任模型的主要障礙,且在多數測試資料集中被持續放大,若僅以準確率評分、對錯誤不予以懲罰,模型反而會被誘導亂猜,特別是在知識領域,錯誤知識比不回答更有害。
AA-Omniscience會對出現幻覺的行為進行扣分。該測試共收錄6,000個專家級的高難度問題,涵蓋6大領域(商業、人文社會、健康、法律、軟體工程、理科與數學),共42個主題、89個子領域;錯誤答案會在「知識可靠度指數」中被懲罰;其3大指標分別是準確率、幻覺率與Omniscience Index(全知指數),在全知指數中,答對會+1,答錯會-1,不答則是0分,總計測試36個模型。
結果發現,Claude 4.1 Opus全知指數第一,其次為GPT-5.1與Grok 4,但這些頂級模型的得分也僅略高於0,其中,Anthropic的優勢來自低幻覺率,OpenAI與xAI則以高準確率取勝。
Grok 4在準確率上居冠,其次為GPT-5與Gemini 2.5 Pro,猜測xAI的優勢可能來自龐大參數量與前訓練運算力;而Claude系列橫掃幻覺榜,4.5 Haiku的幻覺率28%,遠低於 GPT-5(高達80%)與Gemini 2.5 Pro(70%);Claude 4.1 Sonnet與Claude 4.1 Opus的幻覺率皆為48%。
該測試透露出,高知識不等於低幻覺,且每個模型在不同領域的表現也不一,大型模型的準確率雖高,但不見得可靠,整體而言,Anthropic Claude系列在幻覺控制最穩定,OpenAI GPT-5.1在商業領域最準確,xAI Grok 4在數理與健康領域最強大。
至於在AA-Omniscience敬陪末座的,則是LG AI Research的EXAONE 4.0 32B,最後3名還包括OpenAI開源系列的gpt-oss-20B與gpt-oss-120B,這3個模型的全知指數約在-70至-80之間,顯示它們「答錯的次數遠高於答對」,屬於高幻覺、低可靠模型。
熱門新聞

2026-03-06





2026-03-06

2026-03-09