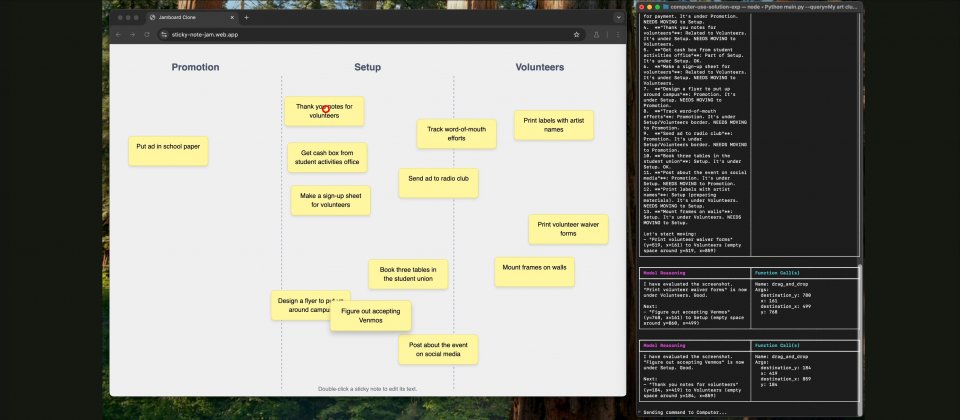
Google釋出Gemini 2.5 Computer Use預覽版,透過Gemini API在Google AI Studio與Vertex AI向開發者開放。這是一款建立在Gemini 2.5 Pro視覺理解與推理能力上的專用模型,目標是讓代理能直接操作使用者介面,可執行點擊、輸入到拖曳操作。
Gemini 2.5 Computer Use模型運作為迴圈,每個回合的輸入包含用戶請求、當前環境的截圖與近期動作歷史,並可明確排除部分動作或加入自訂函式。模型分析後輸出一個具體的介面操作函式呼叫,例如點擊或輸入文字,而涉及購買行為等重要操作則會請求使用者確認。客戶端收到指令後在瀏覽器執行,再回傳最新截圖與當前URL,重新進入下一回合,直到任務完成、發生錯誤或因安全回應與用戶決定而終止。
適用範圍以瀏覽器控制為主,示範中可原生填寫與提交表單、操作下拉選單與篩選條件,並能在登入後的環境執行必要操作。官方同時指出,該模型在行動裝置介面控制上展現潛力,桌面作業系統層級的控制則尚待最佳化。對多數內部系統或第三方服務而言,這種以畫面為目標的自動化,可補足缺乏結構化API時的實作空白。
Google以Browserbase的Online-Mind2Web測試架構呈現成效,模型在該量測下同時達到較高準確率與較低延遲,並在Online-Mind2Web、WebVoyager與AndroidWorld等基準表現突出。
Google已將風險因應直接訓練入模型,以應對惡意使用、意外行為以及網頁端詐騙或提示注入等情境。此外,Google提供開發者控管機制,防止模型自動執行高風險或有害操作,此機制包含獨立的把關步驟,在推論階段逐步審查模型擬議動作的合規性。開發者事先也能用系統指令,規範必須拒絕或徵求使用者確認高風險行為,同時官方文件也建議避免嘗試繞過CAPTCHA或控制醫療裝置,此類行為屬性質上應被阻擋。
Google內部團隊已將此模型應用於UI測試,作為脆弱端對端測試的備援方案,以復原失敗流程。此外,Project Mariner、Firebase測試代理以及搜尋的人工智慧模式在部分能力,也採用了類似技術。
熱門新聞

2026-03-06

2026-03-06


2026-03-09


2026-03-09

2026-03-06

2026-03-09