Meta研究世界模型對程式碼生成能力的提升,釋出開放權重326億參數(32.6 B)模型Code World Model(CWM),專門鎖定程式碼生成情境。與僅以靜態程式碼的訓練做法不同,CWM在預訓練與強化學習之間加入中期訓練(Mid-training),導入大量來自Python直譯器與容器化環境的觀察、動作軌跡,讓模型不只學會語法與範式,也能從實際執行過程推估狀態變化,具體提升錯誤定位與修補、長上下文程式分析以及多回合系統互動的效率與穩定性。
CWM的訓練目標是在可驗證情境中提升推理與規畫能力。其中,在中期訓練階段特別加入兩類可觀測的資料來源,其一是大量Python程式在容器中的記憶追蹤,其二是多回合代理與計算環境的互動軌跡。隨後以多任務、多回合的可驗證增強學習(RL)進行後訓練,讓模型能逐步模擬程式執行與錯誤修補過程,接近開發者日常的執行、觀察、修正的流程。
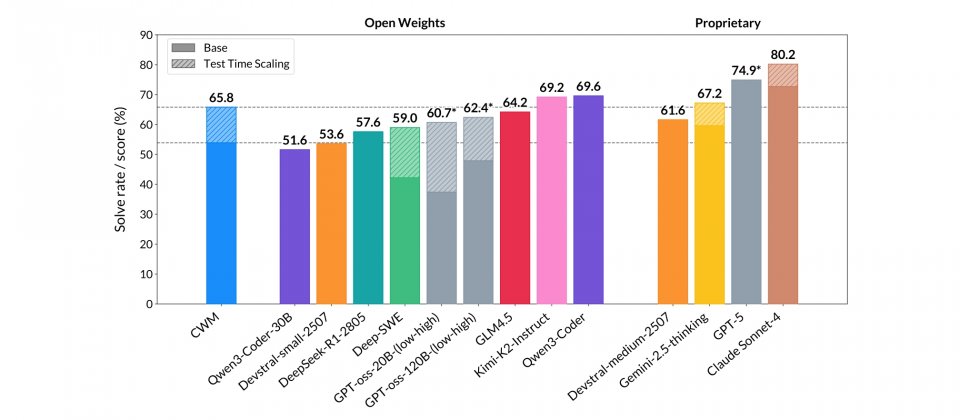
就基準測試成績來看,CWM在SWE-bench Verified 上,未啟用測試時擴展機制(Test-time Scaling,TTS)的單次作答正確率為53.9%,啟用後提升到65.8%,顯示在代理式工作流與TTS下有明顯的效能提升。在LiveCodeBench v5/v6分別為68.6/63.5,表現屬於開源模型前段水準,與Qwen3-Coder-32B、Devstral-1.1-24B互有領先。在數學任務中,Math-500達96.6%,屬於頂尖表現,但在AIME-24/25為76.0/68.2,落後於針對競賽題最佳化的Magistral與Qwen3系列模型。
整體來看,CWM並非全能第一,但在程式理解、錯誤修復與容器化執行這些工程導向的場景表現突出,要是目標為長上下文程式分析、可驗證修補與系統互動,CWM的世界模型訓練與TTS設計更具實用價值。
CWM的價值在於提供一個能觀察、推理、修正的實驗平臺,便於分析世界模型對程式碼生成與規畫的影響,並測試不同訓練階段對最終行為的貢獻。研究者可從釋出的各階段權重著手,評估中期訓練與增強學習在可驗證任務的效益,並觀察長上下文與多回合互動下的穩定性與可重現性。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-09

2026-03-06


2026-03-06
