Google發布開源嵌入模型EmbeddingGemma,定位在裝置端離線情境下,提供語義搜尋與檢索增強生成(RAG)所需的文字向量。官方指出,該模型以3.08億(308M)參數在MTEB多語榜單中,為5億(500M)參數以下的開源模型最高排名,支援100多種語言,並透過量化感知訓練降低記憶體占用,可在低於200 MB記憶體環境執行,目標是讓行動裝置、筆電與桌機在無網路下也能完成檢索與問答。
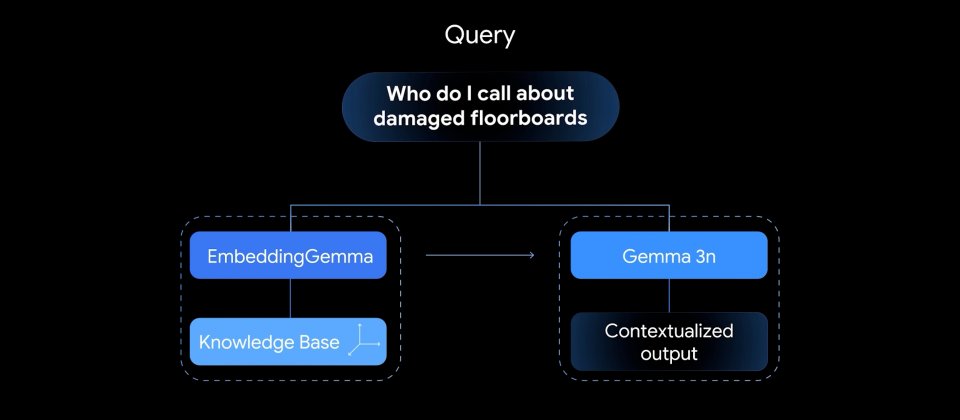
EmbeddingGemma以Gemma 3架構為基礎,由約1億(100M)模型參數與約2億(200M)嵌入參數組成。模型提供約2,000 Token上下文長度,並與Gemma 3n共用分詞器,便於在同一裝置上以EmbeddingGemma完成檢索,再交由Gemma 3或Gemma 3n生成回答,縮短系統整體記憶體使用量。官方強調在EdgeTPU上處理256 Token輸入時,嵌入推論延遲可低於15 ms,對即時互動式應用具參考價值。
EmbeddingGemma採用Matryoshka Representation Learning(MRL),單一模型即可輸出多種維度的向量,提供768、512、256與128等尺寸選擇,讓開發者在檢索品質、延遲與儲存成本之間調整取捨。對RAG流程而言,檢索階段的相似度計算仰賴嵌入品質,嵌入越能刻畫語意與語境,越有助於找出與查詢最相關的段落並減少離題或錯誤回答。
EmbeddingGemma以離線與隱私為設計重點,文件與查詢的向量化皆在本地硬體完成,可用於搜尋個人檔案、簡訊、電子郵件與通知等資料來源,或建立企業知識庫本地檢索入口。模型與常見工具鏈整合,包含llama.cpp、MLX、Ollama、transformers.js、LM Studio、LlamaIndex與LangChain,並提供瀏覽器端的互動展示以視覺化文字嵌入。
Google將EmbeddingGemma定位為裝置端的嵌入解決方案,對需要離線運作、注重資料主權或希望在終端快速回應的應用較為合適,而面向大規模伺服器端服務,官方建議改採Gemini Embedding。
熱門新聞

2026-03-06

2026-03-06

2026-03-09


2026-03-09


2026-03-06

2026-03-09