Google Gemma 3模型正式支援QAT(Quantization-Aware Training)技術,同步釋出多種已量化版本,讓開發者即便使用消費級顯示卡如Nvidia RTX 3090,也能在本地執行最多達270億參數的語言模型,進一步降低大型人工智慧模型的硬體門檻,擴大本地部署與邊緣運算應用可能性。
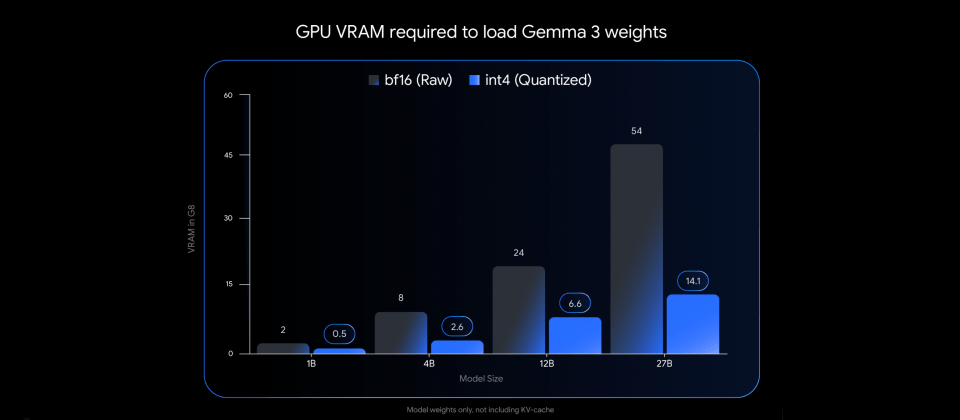
Gemma 3原始模型以BF16格式於Nvidia H100等高階GPU上執行,可提供先進的推論效能。而本次QAT版本則是透過訓練期間模擬低精度運算,有效抑制傳統量化技術可能帶來的效能衰退,支援int4格式,大幅縮減模型權重所需GPU記憶體容量。Gemma 3 27B模型經QAT後,以int4格式儲存時僅需約14.1 GB VRAM,較原本BF16格式的54 GB顯著降低,實際已可在RTX 3090等顯示卡載入執行。
新版本整合主流開源工具與本地推論框架,開發者可透過Ollama、LM Studio、MLX、llama.cpp與gemma.cpp等平臺快速載入,並開始使用QAT版本模型。官方模型目前已於Hugging Face與Kaggle開放下載,支援常見的GGUF格式與Q4_0變體,也可搭配社群貢獻的PTQ模型版本使用。
熱門新聞

2026-03-06





2026-03-11

2026-03-06

2026-03-09
Advertisement