OpenAI
重點新聞(0308~0314)
Transformer Debugger OpenAI 語言模型
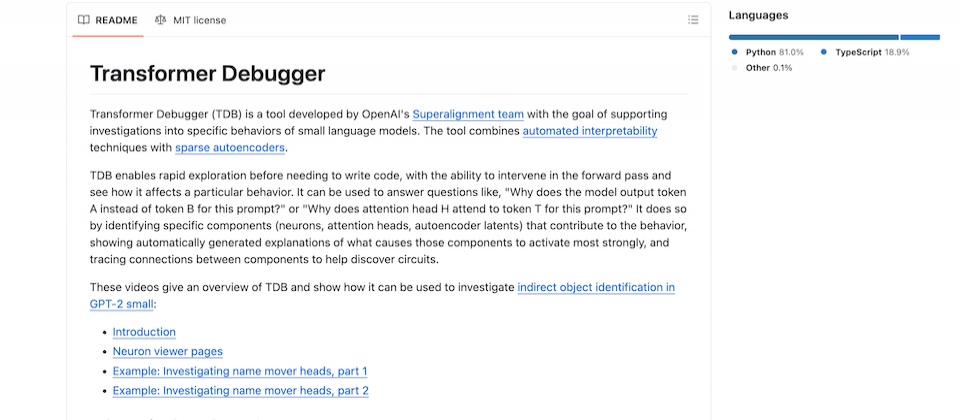
OpenAI開源內部專用LLM分析工具Transformer Debugger
最近,OpenAI在GitHub上開源一款分析工具Transformer Debugger,是內部超對齊團隊(Superalignment)專用的語言模型分析器,可用來理解Transformer內部結構和運作原理,提高透明度。這款工具含自動解釋功能和稀疏自動編碼器兩種功能,可快速探索語言模型,使用者不必寫程式,就能了解模型內部神經網路對模型輸出的影響。
比如,這個工具可用來干預模型向前傳遞訊息,特別是神經元和注意力頭部部分。使用者可刪除特定神經元,來觀察模型輸出的變化,也可對Transformer Debugger提問,如「為何模型在該提示中輸出Token A,而不是Token B?」等問題。OpenAI的機器學習和超對齊研究員Jan Leike表示,這個工具雖然還處於早期階段,但他們希望藉由開源,來推動這方面的研究進展。他也表示,這個工具是要讓專家理解小型語言模型如何運作,並提供模型決策過程的詳細流程圖。(詳全文)
Google 生成式AI 人才培育
Google臺灣揭露今年三大AI落地戰略
Google日前在臺灣春酒記者會中,揭露了三大AI戰略方向,包括培植各領域人才、強化開發者社群和協助各產業等面向,來協助臺灣掌握AI機會。進一步來說,AI是Google臺灣今年的重要在地發展目標,在培植各領域人才上,進一步會細分成三個策略,AI普及、AI應用和AI創新。
就AI普及來說,Google將在臺設立Gemini學院,來提升社會大眾的AI識讀能力,預計在2024年培育1,000名中小學老師接受訓練,並提供3套線上訓練,包括AI基本素養、安全負責任的使用AI、使用AI幫助教學。就AI專業人才的AI應用能力上,Google將繼續透過數位人才探索計畫,從今年第二季開始,在原本的兩大課程「數位行銷和網站分析」和「雲端技術」新增AI基礎介紹和新工具知識,如生成式AI、LLM、負責任AI等。最後一項人才培育則是要強化學研界的AI創新能力,將持續舉辦第七屆的AI創新研究營。
另外,強化開發者社群是Google今年的第二大AI落地戰略,會從工具、社群和技術三個層次展開。尤其在社群經營上,從今年1月展開,預計舉辦16場Build With AI活動,培訓800位開發者投入生成式AI,並計畫培育60位社群領袖成為AI工具的種子教師,以及4位生成式AI領域的Google開發者專家。最後一個AI落地面向是Google要用AI協助各產業創新,比如Google從去年12月陸續推出多項生成式AI技術產品和工具,並以Gemini為名來統一這個GenAI產品線,臺灣也有企業開始試用這些產品,像是中附醫去年底導入醫療專用生成式AI模型MedLM、PChome預計採用AI/ML來提供更精準的商品推薦、旅遊網站KKday則要透過Vertex AI來運用生成式AI技術,將網站旅遊行程商品翻譯6國語言。(詳全文)
Covariant 機器人 LLM
專門用來教導機器人!Covariant發表大型語言模型RFM-1
AI軟體公司Covariant專門開發用來教導機器人新技能的模型,他們最近發表一款大型語言模型RFM-1,也就是機器人基礎模型,可供任何人在幾分鐘內快速規畫新機器人行為。
Covariant自2017年開始建置機器人資料集,蒐集機器人於實體世界的行為,用來訓練模型。RFM-1利用Covariant建置的機器人資料集,再加上大量網路資料,包括文字、圖像、影片、機器人動作,以及各種感測資料進行訓練,是個具80億參數的多模態模型,能支援多種應用。比如,它可以透過圖像學習來分析場景,如分割或辨識;也能結合文字指令與圖像觀察,來產生所需的抓取動作或運動順序;還能將場景圖像與目標抓取圖像配對,以影片格式來預測結果,或模擬沿途數位感測器上的數字。(詳全文)

GPT Builder 微軟 Copilot GPT
微軟釋出GPT Builder工具,可打造客製版GPT
微軟最近宣布對付費的Copilot Pro方案用戶,釋出Copilot GPT Builder工具,來讓使用者打造Copilot GPT客製版。Copilot GPT Builder和OpenAI去年底推出的GPT Builder開發工具很像,可讓中小企業或個人用戶以文字輸入指令,打造具有專門用途的AI聊天機器人,像是在購物網站建一個根據用餐計畫建議購物清單的Copilot GPT。
Copilot Pro則是今年1月微軟公布給個人用戶的Copilot方案,費用為每人每月20美元。Copilot Pro底層模型也將提升到GPT-4 Turbo。微軟也提供Copilot Pro用戶使用GPT Builder的指示,用戶需安裝Edge或Chrome瀏覽器,連到copilot.microsoft.com或chat.bing.com網站,再登入微軟帳號操作即可。(詳全文)
(1).jpg)
Meta GenAI 基礎設施
Meta公開GenAI基礎設施
Meta最近公開自家使用的GenAI基礎設施,內含兩個各用24,576個Nvidia H100 GPU的大型資料中心叢集,以及相關的網路、運算與儲存部署。早在2022年,Meta就揭露自己打造的AI叢集AI Research SuperCluster,當時就稱這是全球速度最快的超級電腦之一,使用了1.6萬個Nvidia A100 GPU。
而最近Meta揭露的GenAI叢集,雖採兩種不同的網路架構,但都配備了24,576張Nvidia H100 GPU。因為,他們每天要執行數百兆個AI模型,因此需要客製自己的硬體、軟體和網路架構,來確保資料中心的高效運作。其中一個叢集是基於Arista 7800、Wedge400與Minipack2開放運算計畫(OCP)機架交換器的RDMA over Converged Ethernet(RoCE)解決方案,可透過乙太網路自遠端直接存取記憶體的網路協定,是高頻寬、低延遲的網路基礎設施。
另一個叢集則採Nvidia的Quantum2 InfiniBand架構,同樣也是專為高效能運算的低延遲與高頻寬所設計。這兩個叢集的端點互連速度皆高達400 Gbps,採用不同網路架構,將有利Meta評估不同類型的互連對大規模訓練的適用性及可擴展能力,以作為未來設計和建置更大規模叢集的參考。(詳全文)

DeepMind 通用AI AI代理
DeepMind開發通用AI,可接收指令玩遊戲
幾年來,DeepMind一直專攻AI代理人玩遊戲研究,最近開發一套新AI代理Scalable Instructable Multiworld Agent(SIMA),是第一個能理解廣泛遊戲世界的AI代理,可像人類一樣遵循自然語言指令、執行任務。
就技術架構來說,SIMA由兩個模型組成,一個專門處理圖像和語言映射的模型,另一個則是預測螢幕接下來會發生什麼事件的模型。團隊表示,SIMA不需存取遊戲原始碼,也不需要客製的API,只需兩個輸入值,即螢幕畫面和用戶所提供的簡單自然語言指令,並使用鍵盤和滑鼠來控制遊戲角色。
DeepMind與8個遊戲工作室合作,在9款3D遊戲中訓練和測試SIMA。團隊對SIMA進行了600項基本技能評估,涵蓋導覽、操作物件和使用選單等,目前SIMA可在10秒內完成簡單任務,DeepMind希望SIMA之後能完成需要高階策略規畫,並由多個子任務組合才能完成的複雜任務。他們也發現,SIMA具備泛化能力,能將學習到的技能和策略,應用在沒見過的環境中。(詳全文)

IBM NASA 科學文獻
IBM聯手NASA開發科學文獻專用LLM
IBM和NASA聯手訓練一套Transformer大型語言模型,用科學文獻訓練而成,能進行分類、實體擷取、問答和資訊檢索等各種科學自然語言理解任務。該模型也在Hugging Face上開源,供科學與學術社群使用。
進一步來說,為了讓模型理解科學專有名詞和複合詞,團隊使用來自天文物理學、地球科學與太陽圈物理學等多個專業領域資料集的600億個Token,來訓練模型。後來,團隊用生物醫學基準測試BLURB來評估IBM-NASA模型,分數比其他開源的RoBERTa模型高出5%。這個IBM-NASA模型,可針對許多非生成式語言任務微調,團隊還利用編碼器模型建立檢索器模型,來產生資訊豐富的嵌入向量,映射一對對文字間的相似性,讓檢索模型根據問題,找出最相關的文件或資訊。(詳全文)
Google 社會學習 知識轉移
Google用社會學習優化模型知識轉移能力
Google最近發表一項大型語言模型創新研究,提出社會學習(Social Learning)框架,為模型間的知識傳遞,找出新方法。社會學習能讓語言模型透過自然語言文字交流知識,而且,因為不需直接交換敏感資料或模型權重,還能保有資料隱私。社會學習的概念是,模仿人類在社交環境中,透過口頭指示向其他人學習。在Google提出的社會學習框架中,學生大型語言模型會向多個特定任務解法的教師模型學習,團隊也會評估學生模型在各種任務的表現,來衡量社會學習成效。
他們發現,即使語言模型只接收少數範例,一樣能獲得良好的任務解決能力。而這個方式的重要性在於,教師模型可依據實際資料集,合成出新的範例,與學生共享。特別是,合成資料集雖與原始資料不同,但具相同教育意義,因此,就算教師模型不直接共享真實原始資料,學生模型還是可以從合成資料中學習。實驗結果顯示,當合成範例足夠多,例如只要達到16個,社會學習方法和直接共享原始資料方法的模型解決問題能力就沒有顯著統計上的差異。(詳全文)
圖片來源/Covariant、微軟、Meta、DeepMind
AI近期新聞
1. Azure OpenAI服務正式上架Whisper模型
2. Amazon提供電商生成AI工具,貼連結就能產生產品頁
3. Patronus AI發表API工具,可用來偵測LLM有否輸出侵權內容
4. GPT-4競爭者報到:Gemini 1.5、Mistral Large、Claude 3 Opus與Inflection-2.5
資料來源:iThome整理,2024年3月
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-06

2026-03-09


2026-03-06