微軟在其小型語言模型Orca和Orca 2的研究基礎上,發展出了Orca-Math,這個新模型的特點在於,雖然僅為70億參數的小模型,但是經過代理指導(AgentInstruct)與迭代學習(Iterative Learning)的微調過程,其解決小學數學問題的能力已能超越大型語言模型,而數學過去被認為是對小型語言模型較困難的領域。
微軟在去年6月發表了130億參數的小型語言模型Orca,並在11月的時候更新釋出Orca 2,而Orca系列的研究貢獻在於,微軟證明改進訓練訊號和方法,能夠強化小型語言模型,使其接近大型語言模型的推理能力。Orca-Math也是依循相同的想法所開發出來的特化小型語言模型。
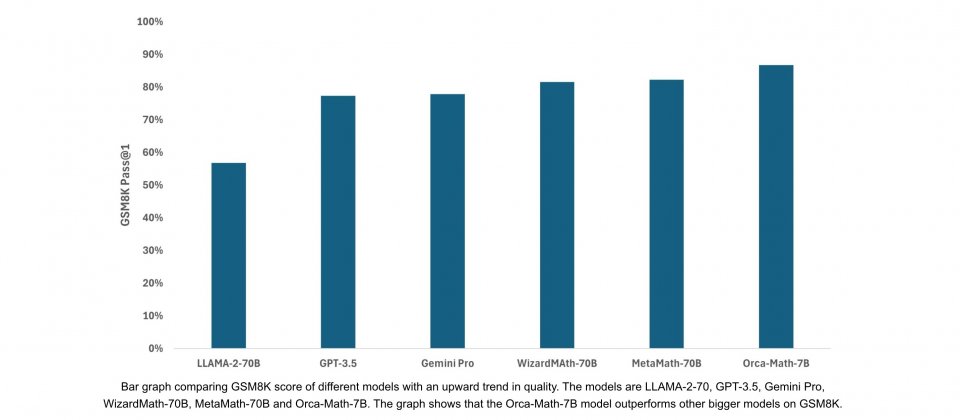
Orca-Math是一款以Mistral 7B模型為基礎,針對解決數學問題任務微調的70億參數語言模型,可在基準測試GSM8K pass@1達到86.81%,而這超過了通用模型LLAMA-2-70、Gemini Pro以及GPT-3.5的表現,甚至也超過專為數學開發的模型像是MetaMath-70B和WizardMa8th-70B。Mistral 7B未經微調的GSM8K準確率則是37.83%。
GSM8K是一個數學領域的資料集,全名為Grade School Math 8K,也就是小學數學8,000題的意思,這個資料集包含了8,500題高品質的小學數學應用問題,這些問題需要多步驟推理解決,因此GSM8K被設計來評估和訓練人工智慧模型,尤其是語言模型在數學領域的解題能力。
GSM8K問題涵蓋小學數學的加法、減法、乘法、除法、分數和百分比等,語言模型需要理解問題的脈絡,進行適當的計算才能得到正確的答案。整體來說,GSM8K是一個具有挑戰性的資料集,不只測試模型的運算能力,同時也評估模型以自然語言理解數學問題的能力,是評估和改進人工智慧在數學領域的重要資料集。
要能在GSM8K基準上達到超過80%準確率,通常模型參數量需要超過300億。因此該領域研究人員為了要提高小模型解決問題的能力,需要採取一些特別的方法,像是訓練語言模型生成程式或是使用計算機以避免運算錯誤,也會使用整合(Ensembling)技術,透過多次呼叫模型來重新解決問題,以提高小型語言模型的準確性。雖然Ensembling可有效提升模型效能,但是由於模型可能會被呼叫高達100次,因此運算成本也大幅增加。
微軟在Orca-Math研究中,堅持不用外部工具、驗證器以及Ensembling技術,嘗試提升模型原生能力。主要朝兩個研究方向前進,第一是代理指導,第二則是迭代學習。
過去的研究在合成訓練資料中,常會使用先進模型參考種子問題生成相似的問題,而微軟提到,為了創建更具挑戰性的問題,他們採用AutoGen多代理流程,此方法可創造更多問題範例,同時增加問題的多樣性和難度範圍。
多代理流程配置可以由建議者(Suggester)、編輯者(Editor)、驗證者(Verifier)三個代理組成,由建議者檢查問題並提出多種增加複雜性的方法,而編輯者則接受原始問題和建議者的建議,生成更新、更具挑戰性的問題,並透過迭代多輪來逐漸增加問題的複雜性,並由驗證者檢查新問題是否有解,並創建解決方案。
迭代學習是Orca-Math表現良好的另一個原因,微軟提到,使用高品質訓練資料,可引發像是解釋等更豐富的學習訊號,大幅改進小型語言模型的能力,而這種能力過去僅會在大型語言模型中出現。
微軟將這種範式應用於老師學生訓練方法,由大模型擔任老師,小模型則是學生角色。在示範教學過程,微軟使用代理指導向小型語言模型,展示問題及其解決方案,而在練習與回饋階段,小型語言模型嘗試自己解決問題,並創建多個解決方案,之後才由老師模型對這些解決方案提供回饋,當小型語言模型無法正確解決問題,則由老師模型提供解答。
微軟研究人員不只希望小型語言模型會解決問題,也希望其採用較好的解決方案,因此由老師模型回饋偏好資料,向小型語言模型展示好的與壞的解決方案,並重新訓練小型語言模型。微軟提到,練習、回饋和迭代改進的步驟,會重複多次以提升小型語言模型的能力。
微軟研究結果顯示,在有限範圍小型模型可以表現優異,Orca-Math經過20萬道數學題目的訓練,其在解決數學問題的能力,效能已經能夠與大型語言模型相競爭甚至超越。微軟公開了資料集,還有一份描述訓練程序的報告,以促進小型語言模型的發展。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09
