
GitHub
Google周四(2/15)透過GitHub開源了內部所使用、基於深度學習的檔案類型辨識系統Magika,宣稱此一深度學習模型即便是在CPU上運作都能在幾毫秒內準確辨識出檔案類型,效能比現有的其它工具高出20%。
Google解釋,要判斷如何處理檔案之前,必須先確認檔案類型。在這50年來,Linux所配備的Libmagic函式庫及檔案公用程式一直是檔案類型辨識的標準,現代的瀏覽器、程式碼編輯器或是各種軟體,都必須仰賴檔案類型偵測來決定如何正確呈現檔案,然而,準確檢測檔案並不容易,因為每種檔案格式都有不同的結構,或者根本沒有結構。此外,文字格式與程式語言在結構上非常類似,迄今不管是Libmagic或是其它檔案類型辨識軟體,都是藉由手工蒐集的啟發式或客製化規則來偵測檔案格式。
手動的方法既耗時又容易出錯,因為人類很難手動建立通用規則,特別對安全應用程式更具挑戰性,因為駭客會不斷試圖混淆視聽。
為了解決檔案類型偵測的問題,Google研發了Magika,它採用TensorFlow平臺上的Keras函式庫,來設計與訓練一個客製化且高度優化的深度學習模型,用來訓練的資料集含有逾100種檔案類型的2,500萬個檔案,其模型大小只有1MB,並以Onnx作為推論引擎,確保可於幾毫秒內辨識檔案,辨識率超過99%,且在CPU上運作的速度幾乎與非AI工具一樣快。
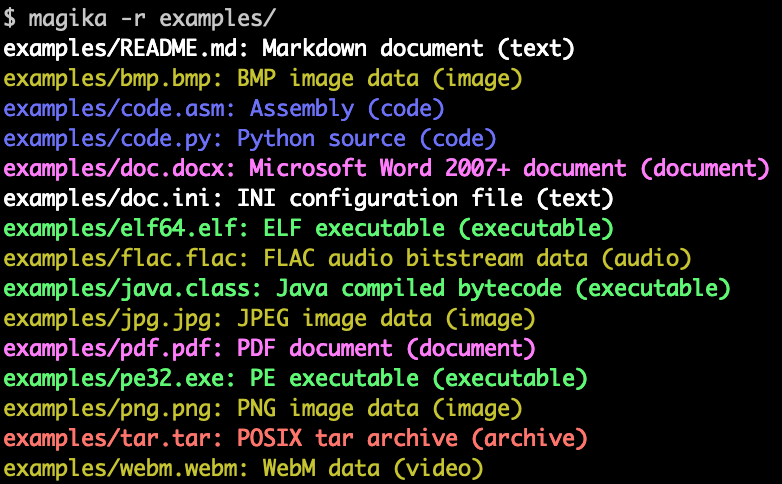
當在含有上百種檔案類型的逾100萬個檔案上進行評測時,Magika的效能比其它現有工具高出20%,且在程式檔案或是配置檔案等文字檔上的效能則更佳。
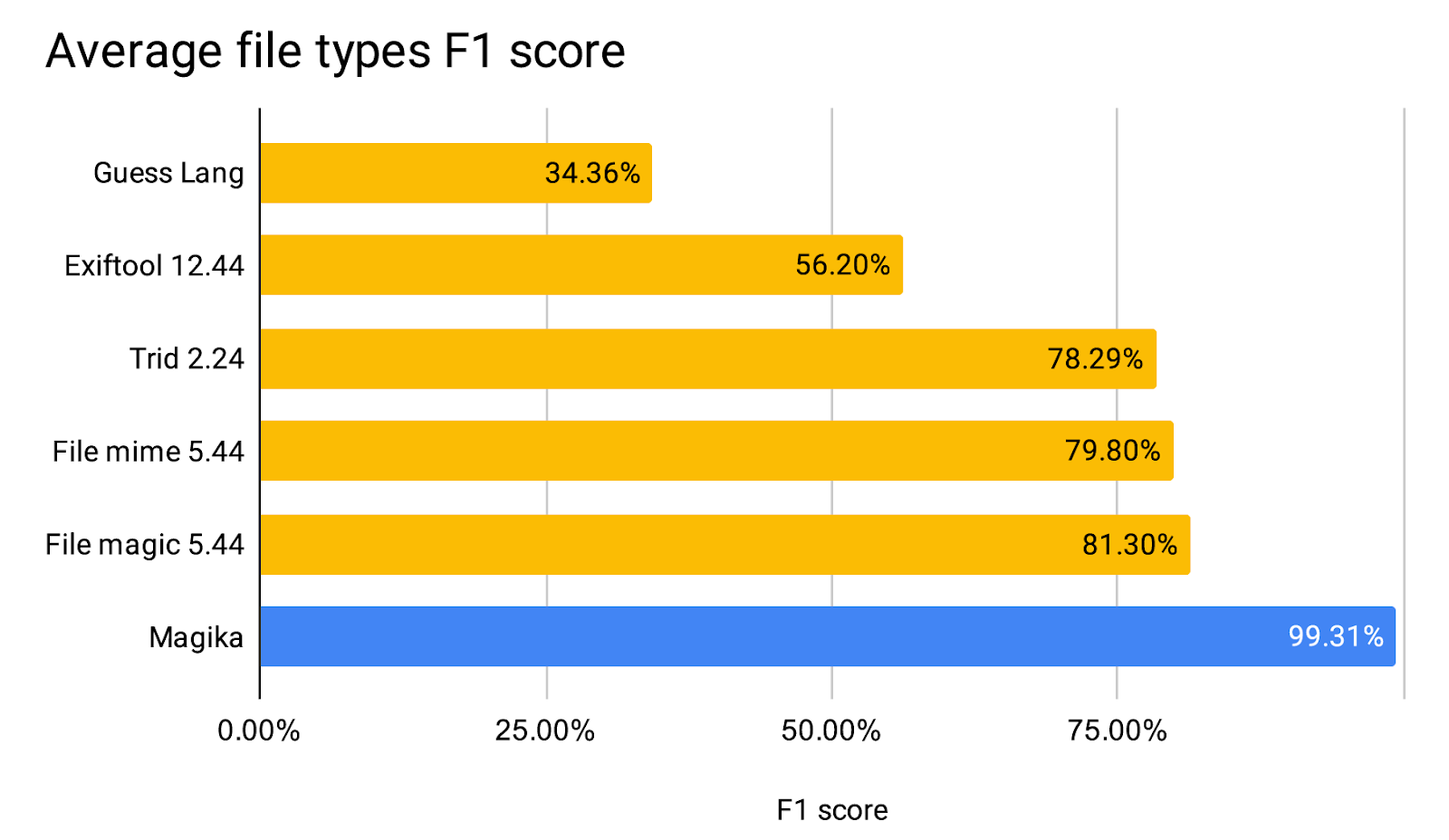
Google內部已大規模採用Magika,主要負責將Gmail、Drive及Safe Browsing所收到的檔案、傳送至適當的安全或內容政策掃描機制上,根據Google的統計,相較於過去依賴手動規則的系統,Magika的準確性提高了50%。
開發者可透過網頁試用Magika,或是將它安裝成一個Python函式庫,也能作為單獨的命令列工具。
未來Magika也將被整合至惡意程式分析平臺VirusTotal上,搭配該平臺上部署Google生成式AI的Code Insight 功能,把Magika作為Code Insight分析文件之前的過濾機制,提高VirusTotal的效率及準確性。
圖片來源/Google
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09

2026-03-06