
Google Cloud
Google周四(12/7)發表了新的張量處理器(Tensor Processing Unit)Cloud TPU v5p、超級電腦架構AI Hypercomputer,以及資源管理工具Dynamic Workload Scheduler,以協助組織執行與處理AI任務。
Google甫於今年11月推出Cloud TPU v5e,再於本周發表Cloud TPU v5p,前者強調的是成本效益,後者號稱是迄今最強大的TPU。每個TPU v5p pod具備8,960個晶片,晶片間的互連速度達4,800 Gbps,相較於上一代的TPU v4,Cloud TPU v5p提供了2倍的FLOPS與3倍的高頻寬記憶體(HBM)。
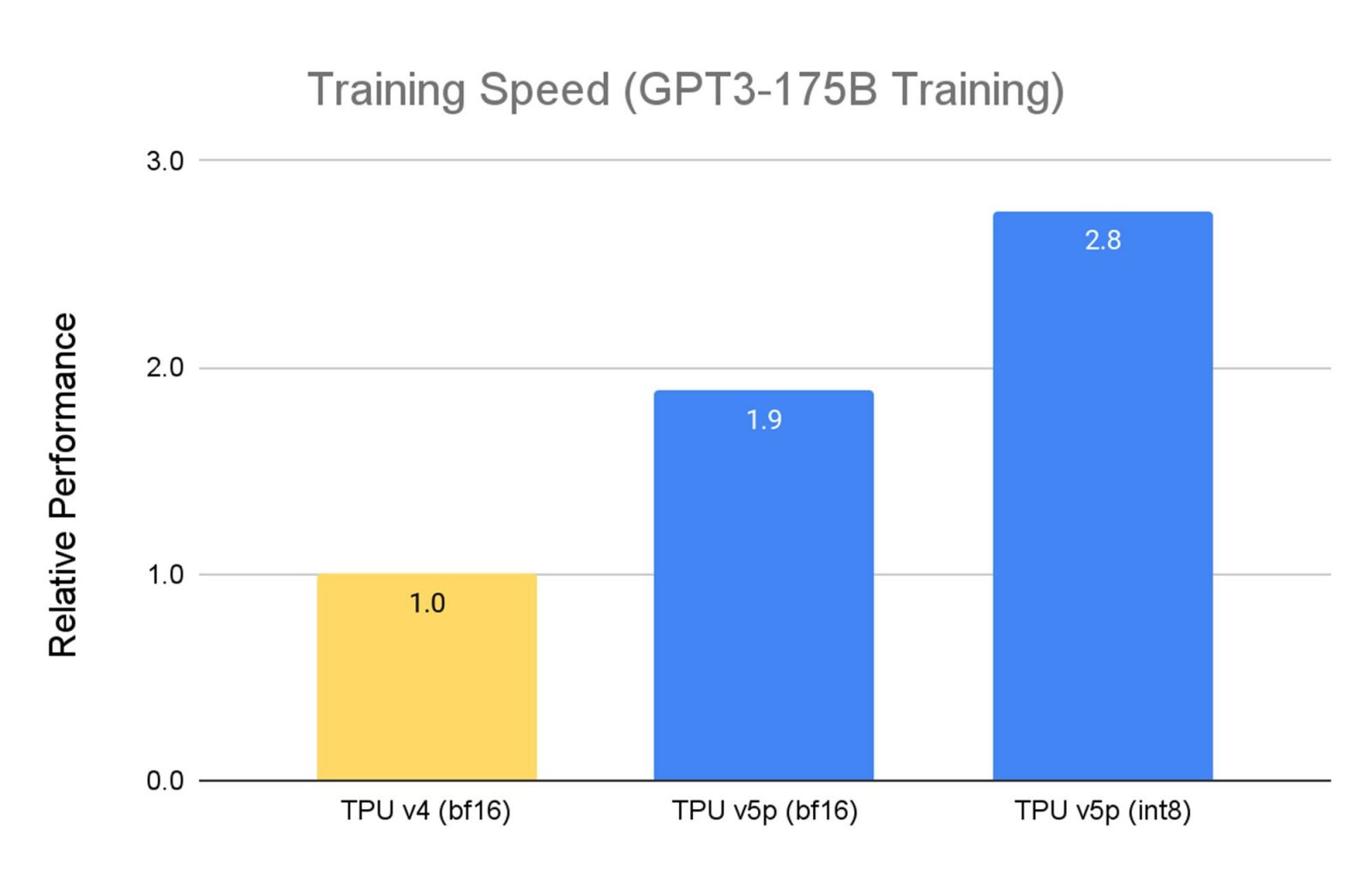
由於Cloud TPU v5p是效能取向,因此在訓練大型LLM模型時的速度,比TPU v4快了2.8倍,在第二代 SparseCores的助益下,TPU v5p訓練嵌入式密集模型的速度,也比TPU v4快了1.9倍。
至於AI Hypercomputer則是個超級電腦架構,它整合了最佳化效能的硬體、開源軟體、主要的各種機器學習框架,以及靈活的消費模式。Google解釋,傳統上通常藉由強化分散的元件來處理嚴苛要求的AI任務,然而,AI Hypercomputer則是利用系統上的協同設計來提高AI在訓練、微調與服務上的效率及生產力。
在硬體效能的最佳化上,AI Hypercomputer具備基於超大規模資料中心基礎設施在運算、儲存與網路設備的最佳化設計;亦允許開發者透過開源軟體來存取相關硬體,以微調與管理AI任務,包括支援JAX、TensorFlow與PyTorch等機器學習框架,以及Multislice Training與Multihost Inferencing等軟體,並深度整合了Google Kubernetes Engine(GKE)與Google Compute Engine。

AI Hypercomputer提供了更靈活的消費模式,除了特定用量的折扣(Committed Use Discounts,CUD),以及隨選(On-Demand)與競價(Spot)之外,AI Hypercomputer也藉由全新的Dynamic Workload Scheduler,來提供專為AI任務設計的兩種消費模式,Flex Start與Calendar。
Dynamic Workload Scheduler為一資源管理及任務調度平臺,它支援Cloud TPU與Nvidia GPU,可同時調度所需的所有加速器來協助用戶最佳化支出。其中的Flex Start主要用來微調模型、實驗、較短的訓練任務、蒸餾、離線推理及批次任務,並在準備執行請求GPU與TPU容量,是一種相對經濟的選擇。
而Calendar模式則可替AI任務預留開始時間,適用於需要精確開始時間,與特定持續期間的訓練及實驗性任務,可於此一固定時間的區域中請求GPU容量,所持續的期間可以是7天或14天,最早可提前8周購買。
圖片來源/Google Cloud
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-02

2026-03-05

2026-03-02