
國泰金控首度公布AI治理六大原則,包含數據安全與隱私保護、公平與反歧視、透明性與可解釋性、可靠性、可認責性和倫理道德。
國泰金控今日(9/20)在自家技術年會上,首度公開了實現AI治理原則所投入的4大技術研發進展,包括運用SHAP演算法來解釋AI模型、自建公平反歧視模型驗證方法、導入聯邦學習,以及在模型加入人類回饋增強學習(RLHF)方法的最新成果。
用SHAP演算法解釋模型輸出值
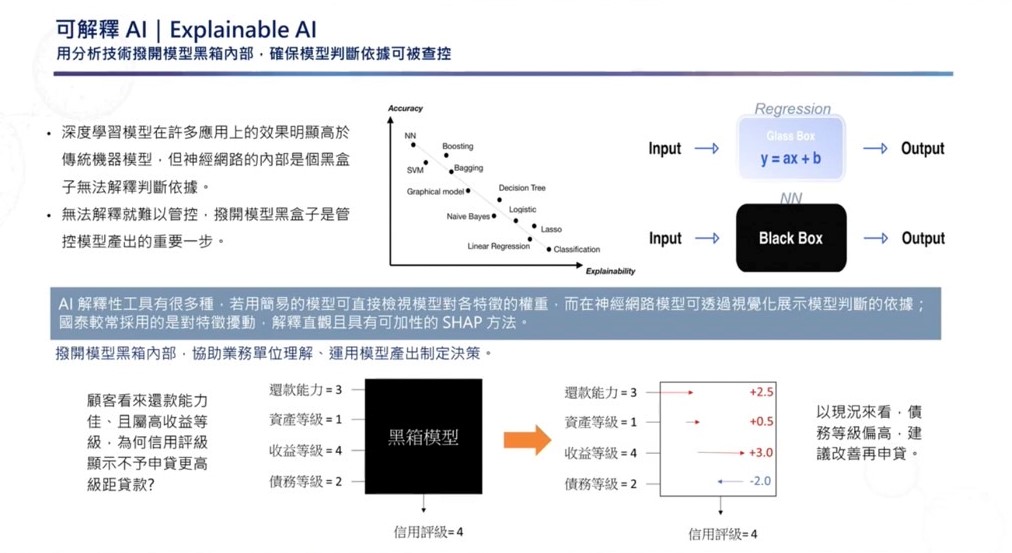
透明性和可解釋性是國泰金控AI治理中的重要原則。過去,傳統模型中的特徵數量較少,權重可被觀察,然而,現在常用的神經網路模型參數量大,資料科學家難以觀察權重變化,運算過程猶如黑盒子,使用者無法得知模型產出答案背後的依據。
為解決這個痛點,國泰金控數據科技發展部協理劉浩翔在自家技術年會指出,在他們採用的可解釋性方法中,SHAP演算法是最常用的一種,可用來視覺化模型中的判斷依據。簡單來說,SHAP可根據模型的輸出值(Output),來回推、解釋模型特徵與產出答案的關係,進一步讓業務單位了解AI算出該答案的原因。
他舉例,原先業務僅能看到顧客還款能力好,且收益等級高,無法得知信用評級低的原因,但經過SHAP反推結果,可以得知顧客在債務等級相較過去高了兩個等級,是信用評級低的主要原因。這個做法可讓模型運算更透明,協助業務單位制定決策。
另一個例子是,由於SHAP演算法針對結果逆推運算過程,因此可藉由反覆抽換單一個體,來測試個體對評分造成的影響,也就是計算單一個體對整體模型的邊際貢獻值。對整體樣本而言,SHAP可以幫助使用者瞭解模型對於各構面的偏重程度,並以程度高低進行排列。而對個案而言,使用者可以藉SHAP檢視最高分或最低分的個案,並進一步觀看評分規則是否合理。
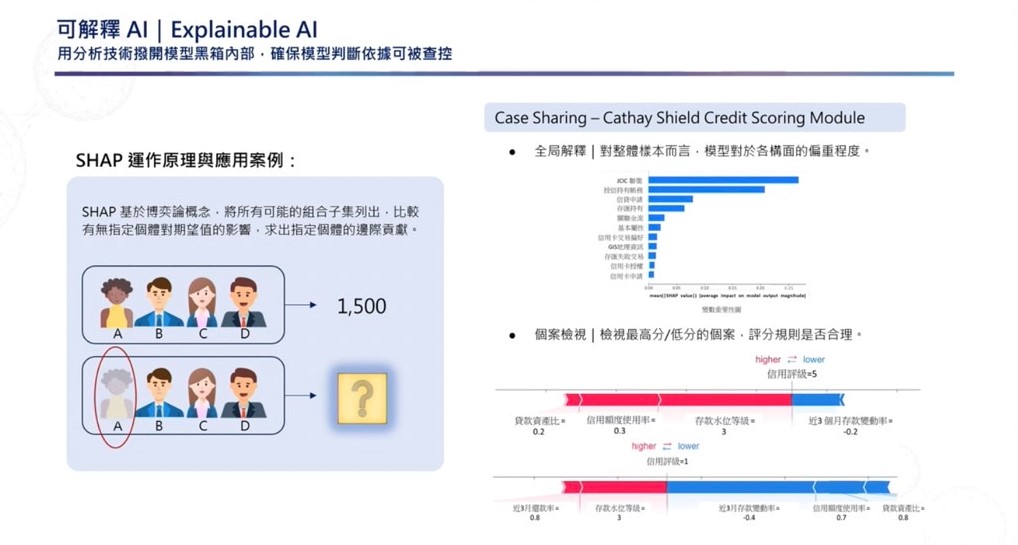
建立公平反歧視驗證檢核機制
另一方面,公平與反歧視也是國泰金控AI治理的一大原則。「有些時候真的不是模型越準越好,」劉浩翔解釋,若金融業使用的AI模型以帶有歧視或偏見的特徵對客戶進行評分,可能加劇社會的不公平性。因此,國泰金控建立一套公平反歧視驗證檢核機制,來確保模型未使用含有歧視意味的特徵。這個方法可分為2步驟,一是在訓練模型前,先盤點資料、確保模型不使用具歧視的特徵,以進行事前約束。再來,模型訓練完後,再以統計檢驗群體間預測的分布是否有異,來進一步移除帶有歧視性的特徵。這是國泰金控用來保障模型公平、反歧視的2階段做法。
劉浩翔表示,雖然捨棄歧視特徵會影響模型表現,但在特徵數量足夠的情況下,還是有可能以其他特徵組合補償降低的表現分數。國泰金控團隊實驗發現,在移除某歧視特徵後,隨著特徵數量越多,模型表現受到的影響會逐漸變小。
但是,若移除向量空間較為獨立的歧視特徵,模型受到的影響仍會存在。「這個情況相對稀少,」劉浩翔表示,大多數的情況下,移除歧視性特徵後,仍可以被大量的特徵數量彌補。他認為,運用公平跟反歧視的ai是金融業不得不承受的趨勢,也因此,「不使用帶有歧視性或偏見的特徵,絕對是我們必須做出的取捨。」劉浩翔說道。
採聯邦學習實踐數據安全與隱私保護
在數據安全與隱私保護上,國泰金控還有另一個作法。他們採用聯邦學習(Federated Learning)來實踐,由於聯邦學習主打去中心化架構,有別於傳統集中式機器學習方法,企業不需要將資料共同集中至某處才能訓練模型,而是在各端點(企業)持有一套模型,用各自的資料訓練模型、再將訓練好的模型權重集結起來優化,之後再下放到各端點,進行下一輪模型訓練,反覆這個過程直到模型收斂為止,就能訓練好模型。
這麼做,不只能防範資料外洩,也能確保模型表現。因此,劉浩翔表示,這項技術有許多適合金融業運用的特性。
例如,國泰金控研究發現,隨著子公司越多,模型的成效越高,且即便發起端擁有的特徵數較少,模型仍有一定表現。此外,若子公司分散的特徵越多,對模型也並未有顯著影響。
加入人類回饋增強學習,確保AI符合倫理原則、貼近事實
為了確保AI具備倫理道德,國泰金控以人類回饋增強學習方法,來讓AI學會公司的價值觀。劉浩翔解釋,國泰在LLM模型後加上以人類偏好所訓練的獎勵模型,藉此讓模型理解人類喜歡和不喜歡的回應。例如,當模型的回應不是人類喜歡的答案,就會將獎勵模型回送到LLM裡進行強化學習,慢慢教會模型,給予符合人類道德和價值觀的回應。
最後,國泰也表示,經過研究顯示,模型中投入越多的參數量,模型表現越好,且在僅針對特定領域進行回應的LLM中,即便只運用小的參數量進行訓練,效果也接近採用大參數量的模型。此外,進行Fine tune及加入RLHF都可以讓LLM模型效果更好,且加入RLHF機制的模型得到的分數高於進行Fine tune的模型表現。
熱門新聞

2026-03-13

2025-06-02

2026-03-14

2026-03-13

2026-03-13

2026-03-13

2025-04-15
2026-03-16