微軟用提高訓練資料品質的方式,來加強模型準確率,因此打造了13億參數的phi-1,只需用8顆A100 GPU、4天就完成訓練。經人類評估,模型表現雖不如GPT-4,但比GPT-3.5要好。
微軟
重點新聞(0616~0622)
微軟 phi-1 生成式AI
微軟打造13億參數小型LLM,人類評估表現勝過千億參數的GPT-3.5
微軟最近揭露一款13參數的語言模型phi-1,以Transformer架構為基礎,採用「教科書等級」的高品質資料集訓練而成,包括來自網路的資料(60億Token)和以GPT-3.5合成的資料(10億Token),用8個A100 GPU在短短4天內完成訓練。他們預告,phi-1接下來會在NLP社群HuggingFace中上架。
最近,越來越多小型LLM,如LLaMA和阿聯酋打造的Falcon。微軟團隊思考,比起增加模型的參數量,透過提高模型的訓練資料集品質,也許更能強化模型的準確率和效率。於是,他們利用高品質資料來訓練phi-1,在人為評測中,phi-1的分數達到50.6%,比起1,750億參數的GPT-3.5(47%)還要好。這不是微軟第一次開發小型LLM,此前,他們打造一款130億參數的Orca,使用了GPT-4合成的數據訓練而成,表現比ChatGPT好。不過,也有學者認為,利用LLM產出的資料來訓練新模型,反而會降低新模型產出的質量,比如來自劍橋大學、牛津大學學者在5月發表的《遞迴歸的詛咒》論文(The Curse of Recursion: Training on Generated Data Makes Model Forgets)。(詳全文)

Google Cloud 反洗錢 生成式AI
Google結合生成式AI推新反洗錢工具
Google Cloud最近推出一款反洗錢工具AML AI,整合生成式AI功能,可用來辨識可疑行為,並生成符合監管規範的報告。Google Cloud指出,傳統反洗錢偵測系統仰賴手動定義的規則,導致可疑行為識別率低,甚至「在第一階段的審查時,會發現這些系統產生的警報,超過95%是錯誤的,而且將近98%最終不會出現在可疑活動報告(SAR)中,」Google Cloud在官方新聞稿中寫道。
這款AML AI工具整合Google Cloud的ML工具,如資料分析工具BigQuery和ML開發平臺Vertex AI,可大規模處理複雜的AI運算,也能提供解釋,可望加速金融機構的調查工作。Google Cloud點出,該工具經匯豐銀行測試,偵測到真正洗錢活動的準確率提高2至4倍,還減少60%的錯誤警報量。此外,AML AI工具還提供可審查和可解釋的說明,方便金融機構進行內部風險管理。(詳全文)
量子超級電腦 Copilot 量子位元
微軟揭露量子超級電腦藍圖,還把Copilot帶進Azure量子服務
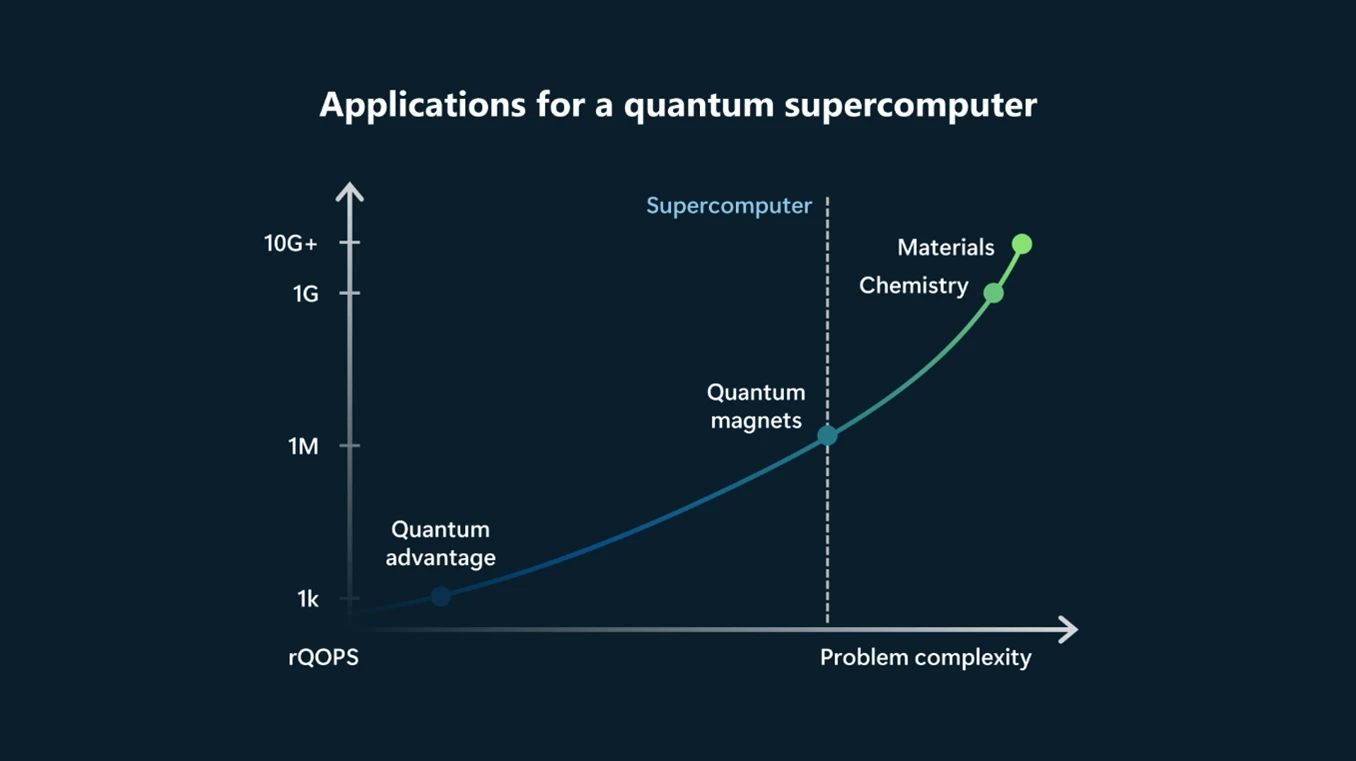
微軟日前在一場線上活動中揭露量子超級電腦發展時程表,包括開發出基於馬約拉納(Majoranas)的量子位元,這種量子位元更穩定、更容易擴展,是量子電腦的重要組成。他們現在已能開發、控制這種量子位元,接下來要實現的里程碑有開發硬體保護的量子位元(用來防錯、縮小量子電腦體積和加速運算)、多量子位元系統(用來執行多種演算法)、韌性量子位元系統(用來執行更高品質的運算),以及打造量子超級電腦,用來解決經典超級電腦無法解決的問題,且錯誤率要小於兆分之一。
此外,微軟還在Azure Quantum服務中新添Copilot助理功能,要讓使用者以自然語言提問,來獲得複雜化學和材料科學相關問題的解答。使用者也能透過Copilot下指令,來完成複雜任務,像是完成基礎計算和模擬,或查詢並視覺化複雜數據,又或是用來撰寫量子運算程式碼。(詳全文)
Meta Voicebox 語音生成
Meta揭新語音生成模型Voicebox,但不開源
Meta以5萬小時的語音錄音,訓練出語音生成模型Voicebox,在英語·在內的6種語言語音生成、去噪和內容編輯等各式語音任務表現非常好,能生成高品質語音,還是第一個未針對特定任務訓練,就能泛化處理各式語音生成任務的模型。由於模型過於強大,存在遭濫用風險,因此Meta不公開Voicebox模型和程式碼,僅公開音訊樣本和論文供學術參考。
該模型的原理類似文字生成模型,只不過Voicebox生成的是語音訊號。Meta指出,Voicebox使用Flow Matching新方法,可直接從原始音訊和轉錄文字中學習,不必進行針對性的訓練。有別於自迴歸模型,Voicebox可修改樣本的任意部分,而不只有音訊片段的結尾,因此更擅長編輯音訊和建立長且連續的音訊內容,可用來替換被噪音破壞的語音片段。同時,Meta還打造一款分類器,能分辨Voicebox生成的語音和真實語音。(詳全文)
歐洲議會 AI草案 風險
歐洲議會通過AI草案,規範AI風險等級和應用範圍
歐洲議會在最近通過了AI草案(AI Act),來保障在歐洲開發、使用的AI完全符合歐盟權利與價值觀,包括人類監督、安全、隱私、透明化、非歧視,以及社會與環境福址,成為西方世界第一個全面性的AI法規。
這項草案是根據AI風險等級,來規定AI供應商和部署者的各種義務,同時禁止某些可能對人類安全造成高風險的AI系統,包括不得於公共空間設立即時的遠端生物辨識系統;不得以敏感特徵來建立生物分類系統,如性別、種族、民族、公民身分、宗教或政治取向;不得根據側寫、位置或過去的犯罪紀錄來打造警務預測系統;不得無針對性地利用網路及監視影像中的臉部,來建立人臉辨識資料庫等。此外,AI Act也建立高風險AI應用列表,包括在重大基礎設施、教育/職業訓練、招募/員工管理系統、必要的私人與公共服務、執法、移民/庇護/邊境管制管理,以及司法與民主程序等應用,都必須遵守嚴格義務。(詳全文)

電腦視覺 Transformer I-JEPA
Meta揭效能超越生成式方法的電腦視覺模型I-JEPA
Meta用一種新AI架構,打造一款6.32億參數的Transformer電腦視覺模型I-JEPA,能關注真正的圖像重點,以更少的GPU訓練時間來得到更好的效能,而且在多項電腦視覺任務的表現,還比主流電腦視覺模型好許多。I-JEPA模型所學習的資料表示(Representation),也不需大量微調,就能用於多種應用程式。在機器學習中,表示是指輸入資料被轉化成機器可理解和處理的形式,也就是所捕捉到原始資料的特徵和模式。
I-JEPA高效能的秘訣,在於能以更像人類理解抽象表示的方式,來預測缺失的資訊。一般生成式模型的預測發生在像素空間,而I-JEPA則使用抽象的預測目標,消除了像素空間中不必要的細節,進而使模型學習更多語義特徵。I-JEPA的另一個重要設計是多區塊遮蔽策略,也就是在處理圖像複雜輸入時,不只關注一小部分,而是放眼更大的範圍,來理解、學習更多的語義資訊,透過豐富的上下文資訊來預測。(詳全文)

OpenAI GPT 降價
OpenAI更新2大GPT模型,還調降價格
OpenAI日前發布新版GPT-4-0613和GPT-3.5-Turbo-0613兩大模型,在Chat Completions API中新添了新的函式呼叫能力。也就是說,新的函式呼叫功能可向GPT-4-0613、GPT-3.5-Turbo-0613描述函式,能更可靠地從模型中取得結構化資料,開發者可建立一個呼叫外部工具來回答問題的聊天機器人,或將自然語言轉換成API呼叫或資料庫查詢。
此外,OpenAI也提供具更多Token的GPT-4-32K-0613和GPT-3.5-Turbo-16K版本,讓它們能處理更大量的文字。至於舊版GPT-3.5-Turbo、GPT-4和GPT-4-32K,則將在6月27日自動升級為新模型。同時,OpenAI也調降部分模型費用,其中最熱門的嵌入模型Text-Embedding-ada-002新價格為每1,000個Toekn為0.0001美元,降幅達75%。(詳全文)
Salesforce CRM AI雲服務
Salesforce推出CRM AI雲服務
雲端CRM業者Salesforce日前推出AI雲(AI Cloud)服務,主打企業行銷和業務專用的生成式AI模型與資料管理分析工具。這款AI雲是以自家CRM專用的大型語言模型Einstein為核心,整合自家資料雲、資料視覺化分析平臺Tableau、API平臺MuleSoft和工作流程平臺Flow,來提供生成式AI服務,如撰寫客戶郵件、產生個人化行銷郵件、直銷訊息或廣告,在電商網站上產生個人化推薦、協助顧客完成購物流程,也能替開發人員寫程式、抓bug等。
這套AI雲還有個特別之處,也就是Einstein GPT信任層,可將資料及模型切開,防止語言模型保留敏感的企業資料。同時,AI雲還支援第三方LLM,如AWS、Anthropic、Cohere和OpenAI的ChatGPT,都可在Salesforce基礎架構上使用。(詳全文)
圖片來源/微軟、歐洲議會、Meta
AI近期新聞
1. DeepMind新AlphaDev模型可加速資料中心運算效率
2. Bing Chat桌機版可以說話了,還支援圖片生成、一次回答最多30次
3. 新版Google Lens可檢測皮膚症狀、將整合Bard
資料來源:iThome整理,2023年6月
熱門新聞

2026-02-26

2026-02-27

")
2026-02-27

2026-02-27

2026-02-27
2026-02-27