OpenAI採用了一種稱為過程監督(Process Supervision)的訓練方法,與單純獎勵最終答案正確性的結果監督(Outcome Supervision)不同,過程監督獎勵每個正確步驟的推理,使得模型能夠遵循人類認可的關聯思考(Chain-of-Thought),產生更可靠的結果。
雖然近期大型語言模型的推理能力大幅度提高,但OpenAI提到,即便是最先進的模型,仍會產生邏輯錯誤,這種錯誤稱為幻覺(Hallucination),而解決幻覺則是建置通用人工智慧的關鍵。
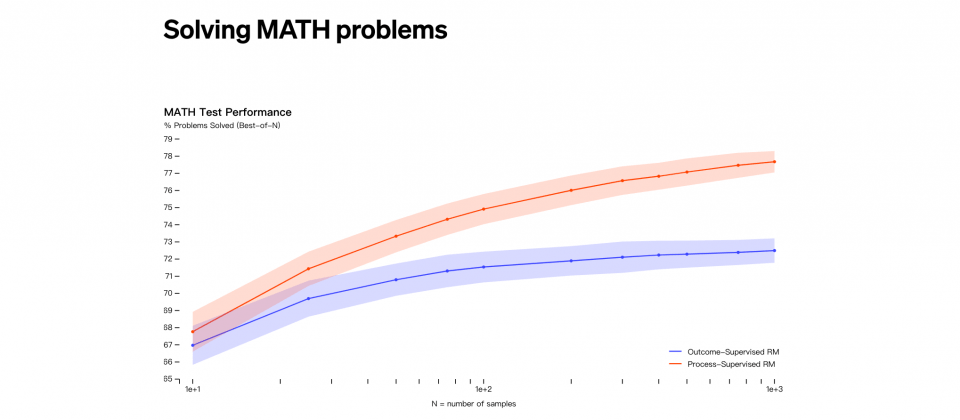
結果監督和過程監督都能夠獎勵模型偵測幻覺,結果監督是由最終結果提供回饋,而過程監督則是會在關聯思考的每一個步驟都提供回饋,根據OpenAI在MATH測試集上的試驗,過程監督能夠明顯取得較好的結果。
過程監督的優點是獎勵模型關聯思考的一致性,過程中每個步驟都會受到精確的監督,而且過程監督因為被鼓勵遵循人類准許的過程,因此還能產生可解釋的推理。相比之下,結果監督可能會獎勵不一致的過程,而且也更難以審查。
研究人員利用MATH測試集評估過程監督和結果監督,過程監督的效能表現較結果監督佳,而且當問題變得複雜,效能差距也會增加,整體來說,過程監督獎勵模型更加可靠。
在人工智慧的領域中,讓人工智慧系統的行為,與人類價值觀一致的方法,被稱為對齊方法(Alignment Method),但通常更安全,且與人類價值觀更一致的方法,代表著可能導致效能下降,而這種副作用稱為對齊成本(Alignment Tax),研究人員提到,對齊成本會對模型部署產生壓力,因此會直接影響對齊方法的採用。
幸運的是,根據實驗結果,在數學領域,過程監督的對齊成本為負,而這可能促使過程監督被積極採用。雖然目前研究人員還不確定這項研究可以多大程度擴展至數學領域之外,但是研究過程監督對於其他領域的工作相當重要,當這些研究結果具有普遍性,則過程監督便成為更高效且一致的方法。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-25