")
史丹佛大學AI研究中心主任李飛飛分享電腦視覺3大進展,包括能讀懂物件關係的物件偵測技術、辨識顆粒度更細緻的物件偵測與隱私技術,以及融合物件偵測、感知和互動能力的個人化機器人技術。(圖片來源/國科會)
電腦視覺發展超過50年,不只能辨識各種物件,也可以分辨物件之間的關係,還能看到人所看不到的細節,美國史丹佛大學AI研究中心更要用來打造幫忙做家事的機器人。
該中心主任也是ImageNet發起人李飛飛日前來臺,揭露了國際電腦視覺前瞻研究的新進展。她從電腦視覺的過去、現在和未來,點出三大技術議題,以及各階段後續衍生的最新研究進展。
例如在物件偵測領域,物件偵測AI解讀物件關係的能力,已從靜態圖像擴展到動態影片,能辨識影片中各種活動外,還能分辨參與人物與物件之間的關係。而且,物件偵測也發展出更進階、辨識顆粒度更細緻的應用以及隱私保護技術,比如人體動作偵測模型PriHAR,不只能準確辨識人類行為,還直接在鏡頭端模糊化人體影像,在源頭就保護個人隱私。
甚至,電腦視覺也開始融合至多種偵測、感知和互動能力的個人化機器人技術,來增強人類能力。這正是李飛飛團隊最新的研究課題,他們不僅建置機器人模擬環境平臺OmniGibson和基準測試BEHAVIOR,還成立一個包含實體機器人的實驗室,來讓實體機器人實際運用模擬環境中所學的知識,同時將現實中學習到的知識回饋至模擬環境,強化機器人學習能力。從這3大技術進展,可以清楚看到電腦視覺未來發展的重要方向。
電腦視覺進展1:物件偵測
李飛飛指出,電腦視覺研究的開端,是從打造能看人類所見的AI(Building AI to see what humans see)開始。為實現這個目標,專家先是研究人類視覺機制,比如大腦辨識物件的反應時間,他們還發現,大腦不同區域還負責不同物件的辨識。於是,專家仿造人類視覺的工作模式,從物件偵測(Object detection)著手,開啟電腦視覺領域的初始研究。
1970年代至1990年代的電腦視覺專家,以人工撰寫規則的方式,比如用幾何圖形切割,來教電腦辨識不同物件。這就是所謂的專家系統,但辨識效果並不好,準確率低。到了2000年左右,機器學習(Machine learning)概念出現,這是一種結合電腦程式的統計學方法,能透過機器自動產生模型,有別於專家系統靠人工撰寫一條條規則來辨識物件。此外,機器學習的辨識能力,比專家系統還要好。
在機器學習興起的時代,也催生出許多經典演算法,比如隨機森林、向量機、基礎網路,甚至是類神經網路。但真正改變遊戲規則的,是網際網路的出現。因為,網際網路讓資料取得更容易,而增加資料量,也成為提高模型表現的一大關鍵。
在那樣的時空背景下,李飛飛改變研究策略,從聚焦演算法來提高辨識準確率,回歸到「學習」本身。她想透過大量資料,來讓模型從中學習、找出規律,並要讓模型具備通才般的泛化能力。有鑑於同時期的資料集規模都不大,頂多3萬多張圖像而已,李飛飛乾脆與學生建立一個超大規模的電腦視覺影像資料集。
也因為網際網路興起,他們得以透過線上群眾外包,打造出ImageNet資料集,內含1,500萬張影像、超過2萬2千個分類,就像是電腦視覺界最大、最齊全的字典。ImageNet資料集也於2009年釋出。
這就是從資料面,來提高演算法表現的做法。李飛飛也自2010年開始,每年舉辦ImageNet影像辨識挑戰賽,來觀察用ImageNet資料集訓練出的模型,表現會如何。結果在2012年,深度學習模型AlexNet橫空出世,不論是辨識準確率還是錯誤率,都大幅優於傳統演算法,拿下該年冠軍。自此開啟深度學習元年,後來幾屆比賽的冠軍,都採用和AlexNet一樣的卷積網路(CNN),準確率越來越高,甚至超越人類表現。最終,比賽在2017年畫下句點,卷積網路也成為物件偵測的代表性架構。
不只要會辨識物件,還要懂彼此的關係
自此,基於深度學習的物件偵測在各領域大放異彩,同時,物件偵測的研究也往前了一步。
因為,李飛飛意識到,光會辨識物件還不夠,還得要懂物件之間的關係才行。於是,李飛飛實驗室展開一項專案,利用場景圖表徵(Scene graph representation),來對人類視覺中的物件關係編碼。意思是,給定一張圖,團隊要對圖中的物件特徵編碼(如大小),也要對物件的屬性編碼(如顏色、材質),還要對圖中人物的動作編碼,比如手持物品、某人站在某物後方等。這個做法,擴大了圖像標註的內容,要讓模型具備更廣泛的知識。
後來,李飛飛團隊將這些數據連同另一個大型資料集,整合為一個視覺基因資料集(Visual Genome Dataset),裡面包含10萬多張圖片、380萬個物件、230萬個關係和280萬個屬性,甚至還有540萬個描述和170萬組QA。
特別的是,這個具備豐富知識的資料集,還能用於零樣本學習(Zero-shot learning)。也就是說,用這個資料集訓練的模型,能具備舉一反三的能力(也就是泛化),就算是訓練資料集中從未見過的影像,也能根據學習道德知識來處理。
舉例來說,人騎馬與人戴帽子這兩個場景很常見,但馬戴帽子卻很少見,要讓模型學會辨識馬戴帽子,按傳統方法,就得收集大量這類照片來訓練模型。但這就是個挑戰,因為現實世界中,並未有足夠的照片來訓練模型。「但透過場景圖編碼來訓練模型,模型就能更好地辨識從未見過的場景或關係,」李飛飛說,因為模型能從學習到的物件關係,來推導新任務的解答。這也是零樣本學習的特色。
甚至,經視覺基因組資料集訓練的模型,還能執行多種任務,像是圖說(Image captioning),以及看圖說故事的圖片轉文字任務。這是李飛飛團隊在2015、2016年的物件偵測研究進展。
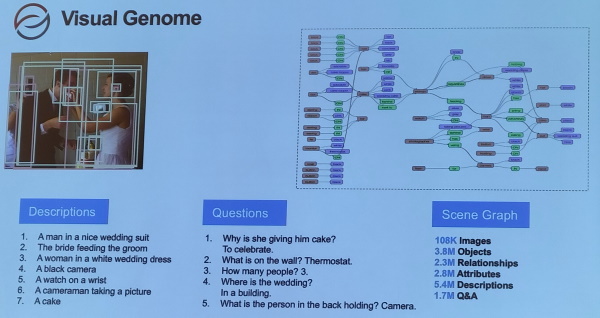
李飛飛團隊打造視覺基因組資料集,不僅有物件屬性,還包含物件關係說明,使物件偵測模型具備解讀物件關聯的能力,提高模型泛化能力。攝影/郭又華
從靜態物件關係偵測,擴展至動態世界
在視覺基因組資料集的基礎上,李飛飛與其團隊更進一步,把理解物件關係的概念,從靜態的圖像擴展應用到動態的影片上。
於是,團隊建立一套名為MOMA(Multi-Object Multi-Actor)的多物件多參與者資料集和基準測試(Benchmark),將活動分析拆分為子活動和動作,並附上參與者角色、物件以及彼此之間的關係說明。這個資料集能用來訓練模型,讓模型分析各種活動、理解人類參與者與物件的關係。
同時,他們也用MOMA資料集訓練出一套類神經網路HyperGraph Activity Parsing(HGAP),不只能辨識影片中的物件和人物,還能分辨物件與人物的關係,表現比其他基準模型要好。團隊的研究成果論文,也在去年獲AI頂級學術盛會NeurIPS接受。
不過,電腦視覺領域不只有物件偵測,還有許多領域是李飛飛認為重要的里程碑,如語義分割、圖像生成等。
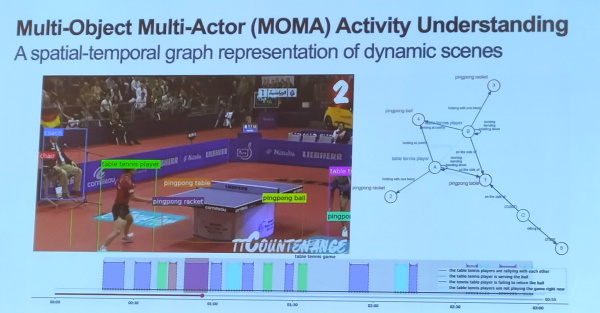
李飛飛團隊進一步將物件關係解讀能力,從靜態的圖像擴大至動態的影片,並建置多物件多參與者MOMA資料集。攝影/郭又華
電腦視覺進展2:顆粒度更細緻的物件偵測
隨著技術發展,電腦視覺從物件偵測邁入另一個階段,也就是用顆粒度更細緻的物件偵測模型,能找出人眼難以辨識的事物。這也是李飛飛所描述的,打造AI來看人類看不見的事物(Building AI to see what humans don't see)階段。
比如,人類擅長辨識不同物件,但將上千種型號的汽車擺在一起,人類就不擅長分辨了。李飛飛團隊曾做過一項有趣的研究,利用車輛型號辨識技術,將辨識到的家戶車輛型號,與投票模式、教育程度和收入等類別做關聯(Correlate)研究。
顆粒度更細緻的物件偵測,能改善人類先天視覺上的不足,比如變化盲視(Change blindness)或視覺偏見。這些缺陷,讓人有時候看不見很多東西,進而引發嚴重問題,像是將手術器材遺留在病人體內,造成病人生命危險。
李飛飛團隊就與史丹佛醫學院合作,利用物件偵測模型,來辨識手術室中,顆粒度更細緻的小物件,比如醫用海綿,用這個方式來追蹤手術器材去向。另一個例子是,借助電腦視覺揪出人類沒注意到的偏見,比如Google研究院多年前就利用臉部辨識和語音辨識演算法,來計算好萊塢電影中,男女演員的演出時間差異。他們發現,男演員得到的演出時間,遠多於女性演員,這是一種產業偏見。
保護隱私的物件偵測技術也很重要
不光是發展顆粒度更細緻的物件偵測技術,李飛飛點出,能保護隱私的物件偵測技術也很重要,這是電腦視覺研究的另一進展。
傳統保護隱私的電腦視覺做法很多,有臉部模糊、降維、人體遮罩、同態加密等。但李飛飛認為,最有代表性的做法,是一項由她實驗室底下一位年輕學者Juan Carlos Niebles所發起的研究:PriHAR。
PrivHAR的全名是PrivHAR: Recognizing Human Actions From Privacy-preserving Lens,直譯是從保護隱私的鏡頭來辨識人類動作。一如其名,研究團隊不只設計出保護隱私的人體動作辨識演算法,還開發一款特殊鏡頭,能將捕捉到的影像,在鏡頭端就先模糊化人體特徵,讓人認不出來,達到保護效果。
這就有別於傳統動作保護方法。因為,傳統隱私保護做法,是將正常鏡頭拍攝的清晰畫面,透過演算法模糊化,來遮蔽人體特徵,進而達到去識別化目的。但在過程中,就容易遭受有心人士的對抗攻擊。而PrivHAR的做法,直接在源頭解決這個疑慮。
電腦視覺進展3:增強人類能力
李飛飛眼中的電腦視覺下一步是什麼?
答案是增強(Augument)人類能力。這是她點出的電腦視覺發展第3階段,打造AI來看人類想看見的事物(Building AI to see what humans want to see)。
比如透過人機協作,可減少醫療錯誤造成的傷害。在COVID-19疫情爆發前,李飛飛團隊就展開一項手部衛生偵測專案,在院內消毒站的高處,放置深度感測器,搭配動作偵測演算法,來辨識醫護人員是否消毒雙手。經過人工監督與電腦視覺偵測對比,團隊發現,AI不僅省時省力,還不會因疲勞而錯抓或漏抓沒做好的醫護人員,這項應用在疫情爆發時,正好發揮強大作用。其他增強例子,還有用電腦視覺來監測ICU患者活動,或是長者起居,來分別協助醫護掌握患者康復狀況以及長者生活安全。
但對李飛飛來說,以AI增強人類能力最有影響的應用是個人化機器人,這也是她近年投入的研究課題。在高齡化、勞力越趨稀少的情況下,融合電腦視覺、感知和互動能力的個人化機器人,就能緩解問題,協助人類生活。
於是,她與團隊先調查民眾對機器人的需求。「這很重要,」李飛飛解釋,因為知道目標,才能以人為中心,從需求出發,來打造個人化機器人。團隊根據美國政府和歐洲政府數據,建立了2,000多個家務活動,並在Amazon平臺上,詢問了1,400多人的意見。
他們得到的答案,多半是家務活動。有了這些資訊,李飛飛團隊選定1,000多個家務活動,並開始建置大型集料集和機器人學習基準,來讓機器人學習做家事、與人互動。為此,團隊先是掃描了15個真實世界環境,並建立1,200多類、共5,000多個3D物件模型,如開著的門或抽屜。這些物件涵蓋不同的物理、感知與互動特性,要讓機器人學習的模擬環境,盡可能貼近真實世界。
史丹佛大學團隊以Nvidia的3D設計模擬協作平臺Omniverse為基礎,打造出OmniGibson平臺,來加速機器人學習。這個平臺內含真實世界的物理特性,如熱效應、光照、反射、透明度感知、流體質量和變形等,也包含物體與環境的互動關係,還有各類複雜的活動。
一如既往,李飛飛團隊也設置一套大型的機器人模擬基準測試BEHAVIOR,以多元的環境來評估機器人能力。
儘管李飛飛團隊花了3年多執行這個大型專案,但現今的演算法,仍無法讓機器人通過測試。這表示,機器人研究還有很大的進步空間。於是,史丹佛大學團隊繼續建立一個專門實驗室,擺放一個實體機器人,來將在模擬環境中學習的機器人,也進入現實世界中活動;同時,他們也要將現實世界活動的機器人數據,回饋至模擬環境中,來強化機器人的學習能力。
盤點電腦視覺發展3大階段,李飛飛看好增強式AI發展,因為,AI不是取代人類,而是能在以人為本的原則下,融合多領域知識與技能,來增強人類生活和福祉。

李飛飛團隊正研究個人化機器人,建置了機器人學習環境平臺OmniGibson之外,也打造機器人模擬基準測試BEHAVIOR。攝影/郭又華
電腦視覺為何成為AI顯學
美國史丹佛大學AI研究中心主任李飛飛以演化角度,點出電腦視覺成為AI發展顯學的原因。她指出,在地球歷史上,5.4億年至5.3億年間,其中短短1千萬年發生寒武紀大爆發,出現各種構造複雜的生命體。澳洲動物學家Andrew Parker甚至認為,這是由視覺進化驅動的物種大爆發,動物能感知到光和外在世界,因此展開激烈的演化競賽。
此後動物繼續演化,發展出重要的神經系統以及最終的智能(Intelligence)。5.4億年後,人類出現,智能已達非常高的水準,是人類從事各種活動的基石。比如,「我們用視覺智能在世界中移動,我們用它來改變事物,我們用它來交流、娛樂,」李飛飛指出,正因為視覺對感知世界如此重要,「身為一個電腦科學家,當我們觀察人類智能,再想想自己能賦予機器什麼能力,就備受啟發。於是,電腦視覺就有了有趣的開始,」她說。
也就是,在圖靈提出著名的圖靈測試後10多年,1966年,麻省理工學院一位教授展開一場夏日計畫,要用一個暑假來實現電腦視覺任務。現在看來雖然天真,但數十年來,AI已有不少重大突破,視覺更是不可或缺,在許多前沿技術處處可見,比如自駕車辨識道路狀況,以及近來爆紅的生成式AI,如文字轉圖像模型DALL-E 2和Stable Diffusion。
「物種發展視覺花了5.4億年,電腦視覺領域則發展70年,」李飛飛點出,現在的電腦視覺技術正在發展旅途中,還可分為3大階段:打造AI來看人類看見的事物、打造AI來看人類看不見的事物,以及打造AI來看人類想看見的事物。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23