Amazon以新範式改善Alexa人工智慧,模型只需最少的人工輸入,就能將知識在不同語言中轉移,官方提到,這樣的模型有效提高新功能的開發速度,並且能夠同時在多種語言上改進Alexa。當前人工智慧的主要進步都來自監督式學習,也就是使用帶注解的資料訓練模型,但Amazon提到,隨著商業人工智慧規模不斷擴大,仰賴注解的方法變得不可行。
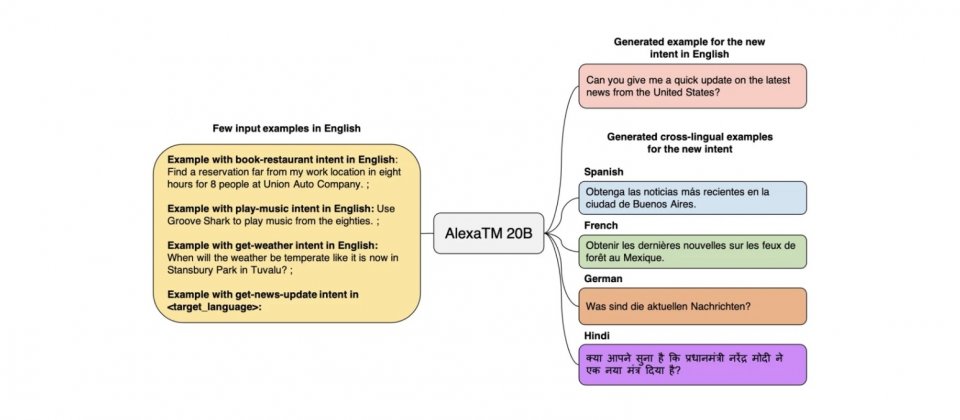
為了解決這個問題,Amazon發展出了新方法,引入基於Transformer的大規模多語言模型AlexaTM(Alexa Teacher Models),只需要給幾個任務提示,AlexaTM就能夠將已知的知識,從一個語言轉移到另一個新語言,而這過程不需要額外的人工監督。
僅有200億參數的AlexaTM 20B,在多種語言任務上優於擁有數千億參數的大型模型。AlexaTM 20B不僅可以跨語言遷移所學知識,還可以從小樣本中學習新任務,官方提到,他們的研究是受到OpenAI GPT-3模型的啟發,但是相較於其他唯解碼器架構的大型語言模型,AlexaTM 20B採用序列到序列(seq2seq)的編碼器-解碼器架構。
AlexaTM 20B在翻譯和文本摘要的效果優於GPT-3,同時也支援更多的語言,包括阿拉伯語、英語、法語、泰米爾語和泰盧固語等。而且因為AlexaTM 20B的參數數量較少,且Amazon對訓練引擎的改進,因此AlexaTM 20B在訓練期間的碳足跡,只有GPT-3的五分之一。
不只如此,在給定單個文章摘要的情況下,AlexaTM 20B可以比擁有5,400億參數的PaLM 540B模型,生成更高品質的英語、德語和西班牙語摘要。
而在Flores-101資料集上,AlexaTM 20B的小樣本機器翻譯,幾乎大勝所有語言模型,特別是在馬拉地語、泰米爾語和泰盧固語等低資源語言間翻譯的效果更好。官方提到,這表示他們大規模seq2seq方式的預訓練,可以提高低資源語言的機器翻譯品質,與需要平行翻譯資料進行訓練的多對多機器翻譯系統相比,從不同語言進行翻譯對AlexaTM 20B可說是毫無難度。
AlexaTM 20B是目前最大的多語言seq2seq模型,能夠進行小樣本學習,Amazon現在對外釋出,限用於非商業用途,以促進開發和評估多語言大型語言模型。
而Amazon經過分析,發現AlexaTM 20B與其他大型語言模型一樣,產生的內容可能包含來自訓練資料中的有毒語言、社會偏見和刻板印象,因此官方提醒用戶,需對該模型的使用進行完整的公平和偏見分析,以充分瞭解可能產生的危害。
熱門新聞

2026-03-06


2026-03-11

2026-03-12



2026-03-10