微軟強化Azure對超大型機器學習模型訓練的支援度,現在用戶可以使用深度學習函式庫DeepSpeed和1024個A100 GPU,來執行兆級參數模型的訓練。
近年基於Transformer的大規模深度學習技術,有了長足的進展,在5年之間,從最初只有數百萬參數的Transformer模型,到現在Megatron-Turing已具有5,300億個參數,這之間模型參數量成長了數個量級,而企業對於訓練和調校這些大型模型的需求也逐漸成長。
過去用戶要訓練這類大規模模型,需要配置和維護一個複雜的分散式訓練基礎設施,微軟提到,這些工作通常有一些手動步驟且容易出錯,因此在可用性和效能表現上並不佳。
而現在微軟用戶可以使用Azure上的DeepSpeed,來應付大規模人工智慧訓練。用戶可以使用推薦的Azure機器學習配置,或是利用Bash腳本以虛擬機器擴展集為基礎的環境執行。DeepSpeed是微軟在2020年釋出的開源深度學習訓練最佳化函式庫,該函示庫使用記憶體最佳化技術ZeRO,改善大型模型訓練的規模、速度、成本和可用性。
微軟採用全端最佳化的方式,將所有訓練必要的硬體、作業系統、虛擬機器映像檔,還有包含PyTorch、DeepSpeed、ONNX Runtime,與各種Python套件的Docker映像檔,以及Azure機器學習API,經過最佳化、整合和測試,使其具有良好的效能和可擴展性,並且讓用戶不需要處理其複雜性。

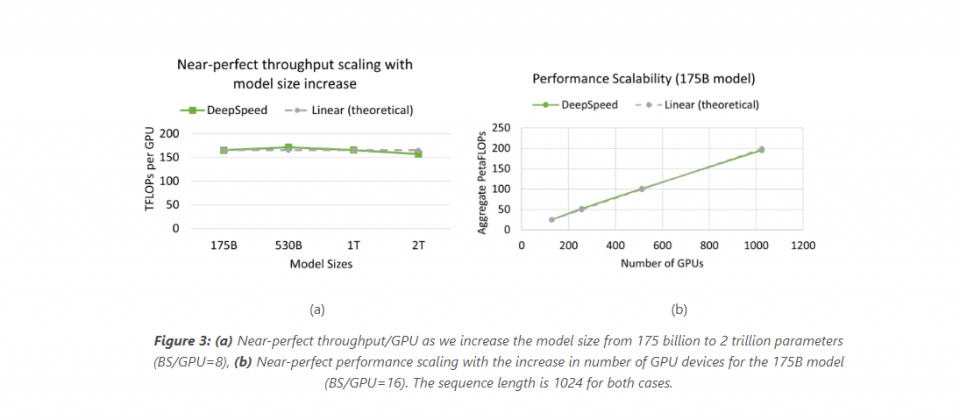
在經最佳化的Azure DeepSpeed堆疊上,用戶可以訓練1兆甚至是2兆參數的超大型模型,而且無論是模型的大小和GPU數量的增加,都提供了幾乎線性的可擴展性,微軟提到,Azure和DeepSpeed打破GPU記憶體的限制,使得用戶可以更簡單地訓練兆級參數模型。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-06

2026-03-09


2026-03-06