的思維來建置公雲上的資料湖,希望能快速支援各類資料的消費,也易於整合不同的資料來重複利用。 圖片來源/摩根大通")
摩根大通以資料產品化策略(Data as a product)的思維來建置公雲上的資料湖,希望能快速支援各類資料的消費,也易於整合不同的資料來重複利用。 圖片來源/摩根大通
「大規模運用AI的關鍵是,資料科學家取得資料的能力。」摩根大通全球資訊長Lori Beer強調,這是為何摩根大通發展大規模AI應用能力,從強化資料力著手的原因。
摩根大通在自家產品或平臺中,已經正式上線了數百個AI應用,他們評估累計帶來10億美元的價值,例如詐欺風險AI模型在2017年上線至今,阻止了1億美元的損失。但是,摩根大通希望能進一步擴大AI應用的深度和廣度,可以建置到數千的AI應用,甚至想要讓AI模型上線時間再縮短7成。
為了實現這個目標,摩根大通採取了資料上雲策略,Lori Beer表示:「在資料平臺上提供工具,將資料轉移到公雲,能讓資料科學家更容易即時取得各種資料。」這正是摩根大通為何近兩年積極推動資料湖上雲新戰略,將基礎架構現代化的做法,也帶到AI戰略平臺的資料戰略上。
摩根大通正在打造一個可以支援1,000名資料科學家的AI戰略平臺,來滿足未來大規模應用AI的需求,主要提供兩大管理子系統,一個是資料生命周期管理平臺,另一個是AI模型生命周期管理平臺。Lori Beer今年的目標則是,要做到,可以實現即時提供關鍵的企業分析性資料。
摩根大通集團EECT部門資訊長James Reid在2021年7月一場活動中,就揭露了他們如何以資料產品化思維來建置公雲上的資料湖,快速支援各類資料的消費,也易於整合不同的資料來重複利用。James Reid認為,資料湖看似可以讓企業集中整合各式各樣的資料,可是若沒有一套好的資料管理和運用策略,海量的資料反而會變成了海量的資料蚊子館,而不是資料金礦。
如何真正發揮資料湖的價值,James Reid透露,摩根大通的秘訣就是「把資料視為一種產品」(Data as a Product),來設計雲端的資料湖。這個資料湖上雲的戰略,正是他們近年混合雲戰略的其中一環。
為了上雲後,可以盡可能善用公雲的資源,摩根大通企業資料架構團隊,將自己視為城市規劃師,「上雲就像是打造一座城市一樣,得想辦法設計出最有效率的城市。」James Reid進一步比喻,若只從省錢角度來思考,而没有從整體目標來思考,雖然可以很快將資料搬上雲,卻很容易打造出沒有效率的城市,就像道路設計錯誤,將車流導引到錯誤的地點一樣。
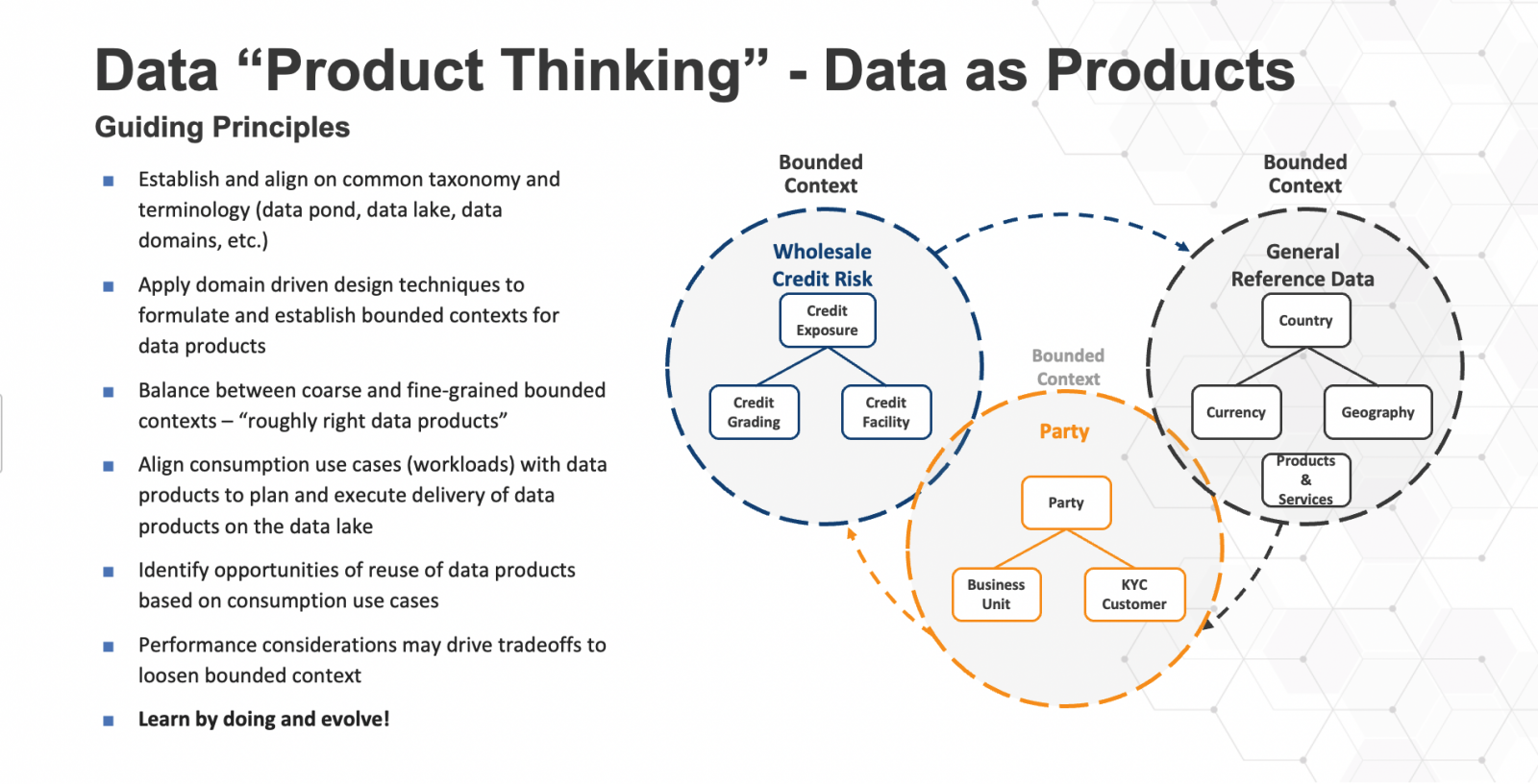
摩根大通以「資料產品」思維來設計資料湖的做法,就像設計微服務一樣,先定義通用語彙,再用DDD設計資料湖的邊界和顆粒度,也從資料消費案例來考慮產品派送,最後靠做中學來改善。圖片來源/摩根大通
資料上雲3大原則
摩根大通將資料上雲的目的,希望打造一座公雲資料湖,來實現資料民主化,讓任何分析需求,盡可能地容易取得和運用這些大數據,但摩根大通不是將任何資料都上雲,而是採取了3個資料上雲的原則:能夠降低成本,釋出更多商業價值,以及有助於資料重複利用。符合這三項原則的資料才會優先上雲。
摩根大通原本就有一套集中式的資料倉儲,也建立了各種不同用途的資料集,但每個資料集就像是一個個池塘,每個資料池塘各有不同用途,彼此各自孤立,池塘內的水要互通非常麻煩,尤其要將其中一個資料池塘產生的新資料,轉到其他池塘得費一番功夫。「這是我們過去資料倉儲的痛點。」James Reid坦言。
因此,摩根大通設計新的資料湖架構時,希望不要再用傳統單體式的資料池塘模式,不是將資料都集中到一個龐大的Hadoop叢集再交給單一團隊來管理,另外也希望打造一個鬆耦架構,方便彈性組合和再利用。最後一個設計目標是,希望讓資料依據特定目的來進行組合,快速篩選出特定目的需要的一批資料。在管理上,也希望建立一個分散式流程,讓多個負責AI或資料分析的工程團隊,都可以很方便地取得這些資料,再提供給生態圈的其他人。
從摩根大通去年公開的資料湖新架構中,可以看到,這個雲端資料湖包括了三區塊,資料來源、資料產品和資料消費者端機制。各種資料來源透過API來存取和提供,而每一個公雲帳號則代表了一項資料產品,擁有專屬的資料網域,就像一支雲端服務一樣,並由一個團隊來負責這個資料產品。「自己管、自己打造、自己維護。」這正是摩根大通Data as a Product思維的維運原則。
資料產品的兩種管理角色
在摩根大通的資料湖新戰略中,還設計了兩種資料產品的管理角色,一種是資料產品的擁有者,另一類是技術擁有者。資料產品擁有者負責這個資料產品的業務管理,以及技術如何對齊業務的需求,包括資料產品風險,分類,品質管理等。而技術擁有者則是負責維運資料產品的團隊,也要負責這個資料產品與其他系統的整合。技術擁有者持有資料湖的帳號,可以真正操作資料湖上的資料產品內容。技術擁有者則要確保技術上的資料品質,來確保本地端建立資料副本的完整性和權限可用。
摩根大通為了將資料當成產品一樣來維護和運用,也採取了資料網格(Data Mesh)的分散式資料架構,透過GraphQL語法,讓應用程式以API方式來存取資料,並搭配了一套整體性治理機制,來提供相關的監測、維護機制。整個資料湖採取了混合雲架構,在本地端機房和公雲上採取了同樣的架構設計,連資料取得流程,雲上或雲下都是採取同樣的授權流程,來支援雲上或本地端的資料消費。
摩根大通在2020年花了2、3個月重新思考出了這個新的資料湖架構,把自己當成一座城市規畫師的方式來思考,重新檢討各種資料的工作量。
要如何將資料視為一種產品?第一步是要先建立一套通用的資料分類和術語,例如資料池塘、資料湖、資料網域。其次,再套用領域驅動設計的做法,來設計不同資料池塘的邊界和脈絡。第三是,拿捏資料邊界,來決定資料池塘的顆粒度,「大概夠用就好,不用太準或太細。」James Reid提醒。這個資料產品化的做法,就像是打造微服務一樣。接著,還要將資料產品對齊各種不同的資料消費實例,來了解不同用途的工作量,作為規畫和執行資料產品派送的參考。並且要辦識出在不同資料使用案例中,每一項資料產品重複利用的機會,再從效能角度來思考,資料邊界的鬆綁拿捏,這就完成了資料產品的設計,可以開始進行資料湖的建置。這個以資料產品思維的資料湖,也像微服務開發一樣,不是一次就能好的過程,得「不斷做中學來改善。」他強調。

熱門新聞

2026-03-06


2026-03-11




2026-03-06
2026-03-10