
Google Brain發表了最新圖像生成人工智慧研究,提出一種稱為Imagen的人工智慧系統,可透過解析使用者的文字輸入,創建出寫實的圖像,與當前其他先進的圖像生成演算法,諸如VQ-GAN、LDM和DALL-E 2比較,人類皆傾向覺得Imagen所產生的圖像更真實,也更符合輸入的文字敘述。
Imagen為文字生成圖像擴散模型(Diffusion Model),能夠深度理解文字的意義,並且輸出如照片寫實的圖像。Imagen建立在大型Transformer語言模型之上,因此擁有強大的文字理解能力,並且仰賴擴散模型生成高傳真圖像。
研究人員提到,他們發現像是T5這類,經過純文字語料庫預訓練過的通用大型語言模型,在圖像合成的文字編碼上非常有效。藉由增加Imagen中語言模型的大小,就可以提高樣本真實度,以及圖像與文字描述的一致性,比起增加擴散模型大小還有效。

Imagen雖然沒有在COCO(Microsoft Common Objects in Context)資料集中訓練過,但可獲得目前最低的7.27 FID分數(越低越好),而且人類評估者也發現,在圖像和文字一致性上,Imagen樣本與COCO資料集相當。
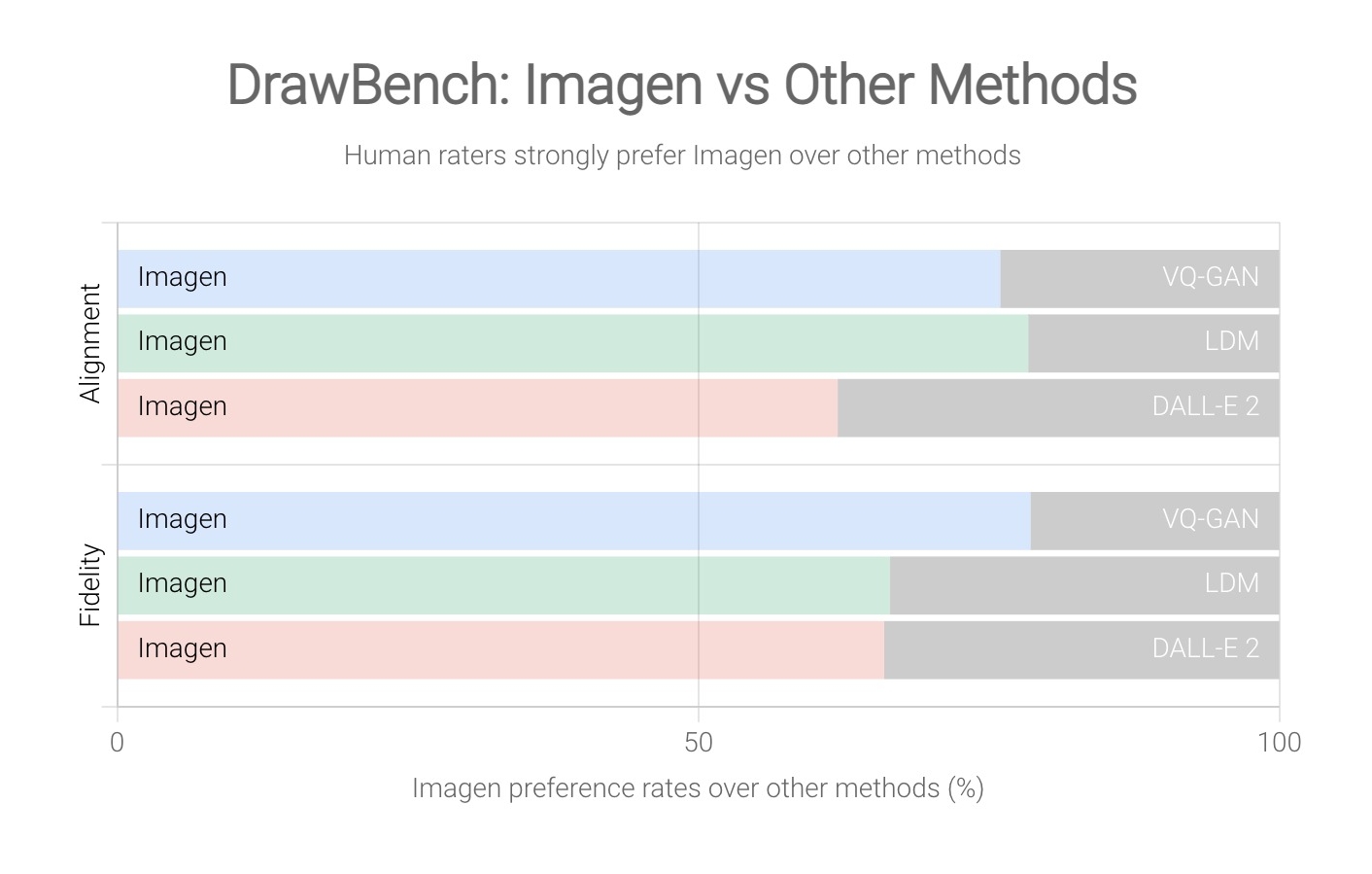
Google還利用DrawBench基準測試,來進一步評估Imagen文字生成圖像的能力,DrawBench是一個在文字生成圖像領域,更全面也更具挑戰性的基準測試。藉由將Imagen與VQ-GAN、LDM和DALL-E 2演算法一起,進行空間關係、長篇文字和罕用字等系統性測試,並由人工評估演算法的圖像與文字一致性,還有圖像的真實性。
由下圖可見,無論是在圖像與文字的一致性(Alignment),還是圖像真實性(Fidelity),人類普遍認為Imagen表現的比VQ-GAN、LDM與DALL-E 2更好。
Google暫不對外開放Imagen,並把未來工作放在解決開放的挑戰與限制上,研究人員提到,雖然他們已經過濾了訓練資料集,並且採用不當內容LAION-400M資料集,來避免模型產生有害的內容,但是因為Imagen仰賴使用未經過濾的網路資料,所訓練出來的文字編碼器,因此Imagen仍可能存在一些有害刻板印象。
另外,當前人們對於圖像生成文字,以及圖像標記模型做了大量的審查工作,以避免產生社會偏見,但是文字到圖像模型的社會偏見評估工作相對較少,Google研究人員經過內部評估,已發現Imagen存在一些社會和文化偏見,像是整體來說,圖像人物的膚色偏淺,對職業的描繪,也更傾向西方性別刻板印象。
因此即便Imagen的能力強大,但目前Google仍不打算開源Imagen的程式碼,也不提供公開展示,原因在於文字生成圖像模型的下游應用非常多樣,且可能以複雜的形式影響社會,考慮到潛在的風險,Google暫不對外開放Imagen,直到開發人員建立起負責任的外部框架,來平衡無限制開放所帶來的風險。
熱門新聞

2026-03-06


2026-03-11




2026-03-06

2026-03-09