")
在今年舉辦的COCO即時物件偵測競賽中,由中研院資訊所所長廖弘源和中研院資訊所博士後研究員王建堯開發的YOLOR,再次拿下第一名。(圖片來源/COCO)
打造了世界第一快又準的物件偵測模型YOLOv4,讓全世界看見臺灣的AI實力後,中研院沒有停下創新的腳步,反而挑戰更大更難的目標。這一次,他們不只要超越世界第一快的前代模型,還要能一心多用,讓一個模型就能處理不同任務。
整合有意識學習的顯性知識與無意間吸收的隱性知識
什麼是YOLOR?
有別於專攻物件偵測的YOLOv4,YOLOR是一套截然不同的類神經網路,「它像一個記憶外掛,能儲存所有輸入模型的訊息。當模型需要執行多任務時,就能從中撈取所需資訊,而不必像傳統方法那樣,從頭訓練模型。」YOLOR核心開發者、中研院資訊所博士後研究員王建堯這麼比喻:「它有如人類的大腦,結合了有意識學習的顯性知識(Explicit knowledge)和無意間吸收的隱性知識(Implicit knowledge),當被問及相關問題時,可從隱性知識中撈出關鍵資訊來回答。」
舉例來說,傳統上,訓練一套辨識鳥類的模型,訓練資料會包含鳥類以外的各種資訊,但為了辨識鳥類這個任務,模型只會抽取鳥類特徵來學習,最後也只能訓練出辨識鳥的能力。但要AI模型再學會辨識狗,就得靠遷移學習加入其他資料、重新訓練模型才行,或是,開發者得重新收集狗的照片,標註後再拿來訓練模型,模型才學會辨識狗。
但YOLOR不這麼做。它簡化了這個流程,整合了所有輸入資料的特徵,當模型需要辨識鳥,它能用鳥的特徵來學習辨識,當模型需要辨識狗時,模型就會從整合的特徵中,抽取出狗的特徵,來學習辨識狗。這個方法,讓模型只需學習一次,就能應付多種任務。
也就是說,傳統上,一個深度學習模型只能利用特定資料,執行一種任務的限制,YOLOR已經克服了。無獨有偶,這也是人人都想突破的挑戰,多任務型AI是現在頂尖科技公司如Google、微軟、臉書等,都想突破的前瞻課題。
整合關鍵:一套統一、通用的表徵
YOLOR的特色,從它的名字---You Only Learn One Representation---就可窺知。「它靠一個統一表徵(Unified representation),來收集輸入模型的所有特徵,這些特徵都儲存在表徵裡,日後模型要執行其他任務時,就會從中提取特徵來學習,」YOLOR另一位核心開發者、中研院資訊所所長廖弘源進一步解釋。
意思是,這個表徵(Representation)是各種特徵(Feature)的總和。舉例來說,我們會用身高、體重、戴眼鏡、年齡、髮色和腔調等來形容特定的某人,這些身高、體重、年齡等細節就是特徵,這些特徵組合起來,就是一個表徵,用來代表某個人。
這個統一表徵是YOLOR的核心。廖弘源和王建堯在YOLOR論文中寫道,YOLOR是一套統一的類神經網路,透過整合顯性知識和隱性知識,來學習一套通用的表徵,而後用來執行各種電腦視覺任務。
他們也在論文中,定義了顯性知識和隱性知識。顯性知識是模型執行任務所需,且與輸入有關的特徵,隱性知識則是模型執行任務時,不依賴輸入資料、僅與任務有關的特徵。比如辨識動物時,模型只需輪廓,不需顏色,此時顯性知識和隱性知識便能從統一表徵中,提取出輪廓,作為辨識任務。
為驗證這兩種知識的特徵,他們也將YOLOR的隱性知識應用於核空間校正(Kernel space alignment)、預測精煉(Prediction refinement)和多任務學習三種方法,來展示這兩種知識特徵帶來的效益。
接著,他們用向量、類神經網路和矩陣分解三種方法,來對隱性知識建模,並用微軟COCO電腦視覺資料集,來測試這些模型。他們發現,不論是類神經網路還是矩陣分解,都能有效提升電腦視覺模型的表現,其中,矩陣分解的效果最好。而顯性知識建模的方式,則可使用NLP常見的Transformer模型、可處理時間空間成對注意力的Non-local Networks模型等。
在整體執行流程上,YOLOR會將一開始輸入至模型的所有特徵儲存起來,形成一個統一、通用的表徵。當模型學會第一個任務(比如辨識鳥類)後,要再學習辨識狗時,就能從統一表徵中提取狗的特徵,直接用來訓練套模型。
當然,使用者也可在同樣的模型上,加上幾層輕量的類神經網路,來加強訓練。之後,模型就能執行第二個任務,甚至能同時執行辨識鳥類和狗這兩個任務,不需要重新收集資料再訓練。
不只整合知識,更能套用到任何CNN模型上
在YOLOR中,隱性知識和顯性知識就像是外掛模型,等於用兩種模型,透過不同的深度學習方法,各自訓練這兩種不同知識,再整合到通用的表徵系統中,從通用表徵抽取當前任務所需要的資訊。
王建堯更點出,整個YOLOR能如外掛般,套用到各種電腦視覺模型上,來加速學習歷程和準確度,不必再針對不同任務使用不同模型。甚至可以有很多套主模型,針對不同任務來訓練,但都搭配同一個外掛模型,打造出一個可以支援多任務的通用模型。
在實作上,他就用YOLOR來改善YOLOv4,發現YOLOR不只能將YOLOv4的平均準確度從43.5%提升到50%,在同等準確度下,還能將Scaled-YOLOv4的推論速度提高超過300%,並讓原本只擅長物件偵測的YOLOv4,具備執行各種電腦視覺任務的能力,舉凡影像辨識、實例分割、物件偵測、物件追蹤等都難不倒它。
有了YOLOR,YOLOv4如虎添翼,不必重新收集資料,就能學會這些任務。「這是一種簡單、高效的方式,讓既有模型快速學習新任務,」王建堯指出,YOLOR只需要極少的訓練成本(少於1萬個參數和運算量),就能實現目標,而且完全不增加推論成本。
COCO即時物件偵測排行榜包辦前四、Waymo挑戰賽全球第二
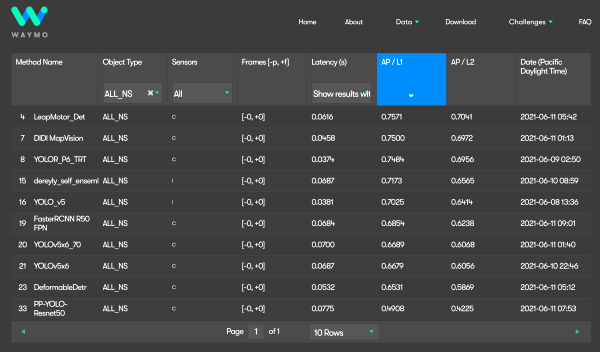
這套YOLOR,也在今年的微軟COCO即時物件偵測排行榜中,一口氣拿下前4名。不只如此,它也在自駕車龍頭Waymo舉辦的開放資料集挑戰賽中大顯身手,滴滴出行聯手天津大學利用這套演算法,在這場平面即時物件偵測挑戰賽中拿下全球第二。
物件偵測是自駕車最重要的AI技術之一,愈快分辨出道路上更多種物件,自駕車就能更及時採取適當的因應方式,需要減速、急煞、小迴轉或加速通過等,都得在百分之一秒,甚至是更短時間內辨識完成。
這場挑戰賽的目的,是要評比模型從影像中偵測2D物體的準確度和即時性,如行人偵測、車輛偵測、單車騎士偵測、號誌偵測等。滴滴出行團隊聚合了多個一階偵測器(One-stage detector),並用多樣的輸入策略來訓練模型,讓模型能更準確偵測每個類別,特別是小型物件。這些一階偵測器,就是YOLOR模型的不同優化版本。
他們看好YOLOR的速度和精準度,採用了一系列YOLOR模型,像是以速度最快的YOLOR-P6作為基準模型,來降低延遲,另也採用參數更多、更精準的YOLOR-W6加入辨識。
在模型推論加速框架TensorRT的加持下,滴滴出行的模型mAP(平均精確度均值)可達75%,拿下世界第二,YOLOR-P6則緊追在後。
「YOLOR(Scaled-YOLOv4-based)是這次競賽中最快、最準確的模型,而且比YOLOv5和Detr還要準確,」YOLOv3的維護者、YOLOv4論文共同作者Alexey Bochkovskiy在這次競賽的GitHub網站上寫道。
今年自駕車龍頭Waymo舉辦的2D即時物件偵測大賽中,滴滴車行以YOLOR打造的模型MapVision拿下全球第二。
AIoT和多模態是未來應用場景
YOLOR跟YOLOv4去年一樣,一登場就在國際競賽奪下實戰成果,迅速擄獲各國研發團隊的目光。但王建堯對YOLOR有更大的期待。
「YOLOR是為了未來AIoT所打造的AI模型。」他解釋,以往AI運算多在電腦上執行,因此有足夠的算力,執行不同模型來解決不同任務。但IoT設備上的運算資源非常有限,難以支援多個模型,來執行不同任務。
於是,為了讓IoT設備有效執行模型運算,就得讓單一模型具備執行不同任務的能力。比如,單一模型要能對一段輸入影片,進行物件偵測、追蹤、語義分割,甚至是行為預測等任務。
這正是廖弘源和王建堯設計YOLOR的理念,要讓YOLOR找出用於不同任務的統一表徵,來服務多種任務。如今,它也證明了能實現多任務,接下來,YOLOR還要進一步擴大到「多模態運算」的能力。
王建堯解釋,多模態的意思是,不同的IoT感測器,可收集不同型態的資料,比如影像、影片、聲音、震度、溫濕度等資訊,這些涵蓋不同型態的資訊集,就是一種多模態(Multi-modal)資料。而過去,一個模型只能處理單一模態的資料,例如只能處理文字資料,或是只能處理影像資料,但現在,YOLOR可對一種資料(例如影像),進行多任務訓練和推論。但同樣的架構可再擴大,他們的未來目標,就是要透過一套通用的表徵,讓一個模型也能處理多模態資料,實現多模態運算和預測。
不過,多模態AI並不是新點子,科技巨頭近年大力壓寶Transformer架構,就是在挑戰多模態課題。Google在2017年,發表了這個用來處理時序性資料的類神經網路Transformer,以它為基礎,在隔年打造出知名的NLP預訓練模型BERT,不僅參數破億,無方向性運算的特性,更在各項NLP基準測試奪冠,引發其他科技巨頭爭相投入。
OpenAI也馬上利用Transformer架構,在2019年打造出功能強大的文字生成模型GPT-2,2020年則推出第三代GPT-3,它所產生的文章流暢度,連真人都難以辨別。GPT-3也因此與BERT齊名,被視為NLP的劃時代里程碑。
但Transformer不是只能用於文字資料。2020年夏天,臉書用Transformer架構來打造影像辨識模型,發表套電腦視覺模型DETR,不只簡化影像辨識工作,表現還達到如Faster R-CNN的高階預測水準。
Google也在同年10月,揭露用Transformer架構實作電腦視覺任務的成果,號稱比CNN更有效率,也就是全球社群愛用的ViT模型(Vision Transformer)。此文一出,更引來各大AI領袖和全球機器學習社群的關注。因為,兩大巨頭證實了Transformer的電腦視覺潛力,很可能擠下獨佔鼇頭的CNN,同時也證明Transformer架構處理不同模態資料的能力。
這波浪潮,在今年更是大大掀起。2021年初,OpenAI就以Transformer架構,打造出可同時處理影像和文字這兩種模態資料的模型DALL·E,號稱是影像版的GPT-3。臉書也跟著發表一套模型UniT,用Transformer架構來同步處理2種模態資料和7種任務,如自然語言處理、自然語言理解(NLU)、影像辨識、物件偵測等。特別的是,這套模型都用同套參數來學習不同任務,離通用AI又更近了一步。
Google也在自家年度開發大會I/O上,也揭露了兩款能同時處理文字和影像的Transformer模型,甚至還預告要用來改善Google搜尋的使用者體驗。與此同時,Line也聯手母公司韓國Naver,揭露了一款以Transformer打造的多語言模型HyperCLOVA,不只用於自家企業級AI產品,還要讓它學會處理影像資訊。

圖片來源/Karol Majek的個人YouTube頻道
YOLOR模型開源後,也有不少開發者拿來實測。波蘭一位自駕車專家Karol Majek就用YOLOR D6模型打造路況即時監測系統,並將釋出監測結果影片。模型不僅能監測車輛、行人,連右方角落容易忽視的行人包包都能偵測
目標一致,但設計思維略有不同
雖然Transformer和YOLOR兩大模型都要挑戰共同的多模態問題,但彼此的設計思維截然不同。
Transformer模型的參數動輒數十億,甚至達到數百億個,需要非常龐大的運算資源,才能訓練出預訓練模型,因此成為大型企業才有財力發展的技術,而大多數人,只能使用已經做好的預訓練模型。可是,也不是人人都敢放心用預訓練模型,臺灣曾有家金控,擔心這些大企業的預訓練模型,使用的訓練資料存有版權疑慮,只得斥資自行從頭訓練模型。
但YOLOR的出發點就不同了。它瞄準AIoT場域,從設備硬體資源有限的前提下,來挑戰同樣的多模態需求。倘若能成功,YOLOR就能有別於科技巨頭靠財力堆疊Transfomer模型的作法,走出另外一條更多人可以負擔得起的多模態發展新方向。
「Transformer和YOLOR要解決的問題很類似。」王建堯解釋,Transformer架構有個很重要的技術,也就是嵌入(Embedding),專門用來將特徵映射到空間中。
「這個概念與統一表徵很像,」王建堯繼續說,如果能將嵌入特徵納入到統一表徵中,「其實任何架構都能實踐多模態AI,」他直言。在前往多模態AI的路上,王建堯看到了一道通往終點的曙光。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-04

2026-03-03

2026-03-02