
本文為【星展銀行授權轉載文章】
譯註:文中所稱之「我們」、「星展銀行」或「星展」皆係指新加坡星展銀行,所提及之金融服務亦為新加坡國內之服務
作者:Ashish Bhan,Data Engineering | Cloud Engineering | Enterprise Architecture| Container Ecosystems | Big Data, Analytics and AI/ML Infrastructure | Automation | SRE | DevOps / 翻譯:李沛衡
原文出處:Architecting Big data at Scale
背景
大數據分析是在處理龐大且複雜的資料集時所使用的進階分析技術,這些資料集包括結構化、半結構化及非結構化資料,其資料量大小從TB到PB不等。大數據的重要性不在於資料量,而是在於資料的使用方式。您可以透過分析從各管道取得的資料,找到潛在價值,並達成以下目的:
• 降低成本
• 節省時間
• 開發與優化產品
• 更明智的決策
為了深入理解非結構化資料,並使我們的技術與時俱進,我們從2016年開始使用Cloudera Hadoop來擴展現有資料倉儲架構。四年多來,包括Apache Hadoop(CDH)平台在內的Cloudera Distribution已成為我們資料架構和策略不可或缺的一部分。我們用它支援大部分的業務作業,從消金、企金、投資銀行到法令遵循,開發共超過40個應用程式。其中的精采案例,包括:
• 反洗錢和反詐騙
• 企金報告
• 風險監管平台
• 交易平台
• 金融平台
• 成本分配
• 客戶科學
• 客戶盡職調查即服務(Customer due diligrance as a service)
利用彈性架構迎向挑戰並推進
隨著相關應用與學術的發展,我們不得不在2019年重新設計整個企業之資料平台,以克服幾個未來的挑戰,例如:
A. 儲存和計算需求間的落差導致資源浪費
B. 硬體採購與供應延遲導致更替時間緩慢
C. 數個硬體故障將影響服務之可用性
D. 使用單一叢集處理所有工作造成的資源搶奪風險
E. 處理多租戶(multi tenancy)造成的「Noisy Neighbor」問題
F. 資源需求預測失準佈署新的資源及允許進行實驗
.png)
我們從GCP及AWS在大數據領域的發展汲取靈感,設計了這個可以更有效處理多租戶(multitenancy)、降低資源搶奪風險及營運成本的平台,並確保我們的關鍵應用程式得以正常運行。成功建構及運行一個高可擴展性的資料平台,關鍵是通過落實以下幾點,將計算與儲存功能加以分離:
A. 資料儲存平台-具有高彈性和高效能的核心資料儲存平台。
B. 微服務-將獨立服務容器化,來封裝多種複雜的大數據工具配置和管理,讓不同應用程式可以按照各自的需求來使用這些容器化的微服務。
C. 使用GPU農場共享GPU-利用整合持久叢集(persistent cluster)與臨時叢集(transient cluster)上的GPU來加速運算。
.png)
資料儲存平台
軟體定義儲存系統(Software Defined Storage)具有許多優勢,因此我們在2019年利用vSAN重新設計我們的資料儲存平台,這種創新的設計包括:
1. 整合叢集中每個ESXi主機儲存個體
2. 利用快閃儲存方式優化的解決方案
3. 基於VM的資料操作和政策驅動的管理原則
4. 基於分散式RAID架構的彈性設計
.png)
這種新架構減輕了我們過去在硬體上遇到的痛點,幫助我們取得了卓越的成效。
新設計現在能夠做的
•增強多租戶(multitenancy)以提高性能:我們根據use case和對CDH的存取量對叢集進行分割。如此將允許叢集獨立運行,尤其是在管理程式碼和正式環境問題查詢時提高我們IT團隊的效率。
•降低資源搶奪風險:同一叢集中執行過多的應用程式可能導致資源搶奪風險,進而導致效能問題和嚴重停機。我們透過叢集分割最大限度地降低相關風險並提高了校能。
•即時同步:Active-Active的設計將確保正式環境和災難復原環境之間的即時同步。隨著我們資料量的提升,我們必須建立可以確保兩個站點始終同步以滿足目標復原時間的能力。
.png)
•為了確保這個active-active的伺服器始終擁有數據塊(Data Block)的副本,我們必須更改其放置策略並在HDFS建立客製化的規則。
下方程式碼對BlockPlacementPolicyWithNodeGroup的原始碼進行擴充,因為星展銀行目前使用此類別來支援佈署在VMware hypervisor的資料節點。此段程式碼與現有的HDFS專案會存在於同一個套件中(org.apache.hadoop.hdfs.server.blockmanagement)。原先會如此定義是因為有一些受保護的類別無法從外部訪問。
大多數功能都保持不變,除了以下BlockPlacementPolicyDefault類別中的函數原型被加以修改以處理數據塊配置。
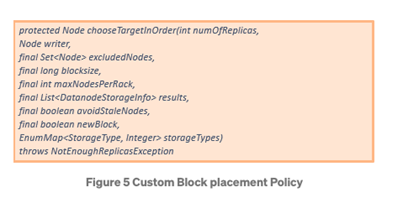
•此函數在延伸類別中被重新implement以改寫在同一個rack中放置多個副本的預設數據塊配置行為。
•準確的容量調整:為了能更準確地預測專案的IT資源使用情況,我們設計了一個儀表板。透過準確的預測,我們確保配置足夠的資源以準時完成專案,並減少延誤和不必要的支出。

•計算和儲存的分離:新平台能讓運算單元和儲存單元獨立增長,因此我們得以只針對其中一個部分進行擴展。如此一來我們便能準確且有效地分配必要資源。
•支應未來的大數據模版:重新建構一個敏捷且可擴展的運算框架層,讓我們能以最小的成本適應未來的大數據技術。
•建立強有力的治理模式以減低成本:隨著平台重新設計,我們納入了一個強大的治理框架,以減少投資成本並防止計算和記憶體資源的浪費。我們將此框架轉移到Hadoop平台,優化了我們的計算和資料導入框架,避免因為糟糕的架構設計、批次處理作業和各類查詢引起的系統意外。我們也進一步使用Cloudera API來監控和追蹤需要調整或出現異常的作業。
•處理小型檔案:應用程式傾向於撰寫成小型檔案,因此這需要平台不斷增加NN記憶體。我們隔離了集群以降低由於高CPU處理而導致性能不佳的風險。此外,我們啟用了回報機制以確保應用程式將分區中的檔案合併,以滿足128 MB的建議大小。
透過新設計,我們實現了以下目標:
a) 成本最佳化
透過整合計算和儲存,我們可以避免因設計、批次處理作業和查詢不佳而導致的技術債。2019年,我們透過最佳化計算框架減少了約20%的成本。我們還降低了約75%的佈署成本。這些改良的效益在銀行整體業務中已能具體感受到,其中對於產出風險報告和財務報告感受尤甚。新架構已幫助我們節省了數百萬(新幣)的授權成本。
b) 提高生產力和上線時間
隨著佈署的速度加快,我們的IT團隊在佈署相關的工作效率提高了約25%,將我們的佈署時間從三個月減少到四小時。如今他們能更有效率地為各單位提供服務,以更快的速度提供所需要的環境。
特別是對於開發人員來說,新的設計架構給了他們莫大的助力。此架構為他們提供了基於詮釋資料(metadata)的框架,使他們在開發新功能和處理新專案時所需的時間幾乎減少了一半。IT團隊從過去需要幾個月的開發時間,到現在可在不到三週的時間內,將應用程式或服務上線以滿足新的業務需求。迄今為止,星展銀行已在此平台上啟用了超過四十個應用程式。
c) 降低風險
自該架構推出以來,沒有任何利用率損失(availability loss),這代表我們已經100%降低了資源搶奪風險,同一叢集內的元件不再搶奪計算資源。叢集根據使用模式和CDH元件使用情況進行分割。我們還將Impala和Spark各自的工作量分離開來,並切換改用SSD上的vSAN,從而全面改善I/O。
d) 愉快且順暢的客戶體驗計劃
我們將讀取傳輸量提高了十倍,寫入速度提高了兩倍,批次回應時間加快了約72%。IT團隊在處理新的應用佈署方面更有信心。該專案還增強了我們的預測分析能力,藉此改善我們組織內客戶的用戶體驗。有了自動化系統的加入,客戶滿意度提高了約14%。
微服務
為了支援不斷增長的技術需求,我們建構的資料微服務來加強Cloudera的隨選資料服務。資訊安全框架與CDH緊密結合,使我們能夠遵守銀行業嚴格的法遵規定。
我們的核心平台在Cloudera上運行,並遵循共享數據體驗(SDX)的原則,並將臨時叢集作為微服務的消耗品。
微服務的構建響應我們的雲端策略,其中一些常見的資料服務可以被虛擬化並以隨選方式提供,並提高資源利用率。這麼做能讓混合雲策略在不更改程式碼的情況下更加順暢。
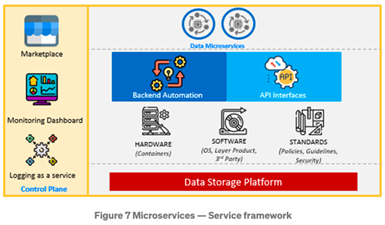
A. 微服務的底層是VMware整合容器和軟體層。
B. 服務框架包括:
a. 控制層 — 負責用戶與微服務的互動,使他們能夠自助操作。這個介面是一個自行開發的Angular前端,它與動態內容管理服務連接,讓服務能夠不用寫程式就上線。
b. 後端自動化 — 負責執行資源的佈署和管理。我們使用Ansible和基於Python的編排器,它與Bitbucket整合,並根據來自前端的選項為每個應用程式創建一個動態的docker compose。

c. API介面 — 負責以程式碼存取和管理資源。這些API作為動態協和框架(Orchestration framework)的一部分,並允許用戶以API而非UI的方式來執行操作及更改腳本。如此可以靈活地以批次方式啟動和執行腳本。
這種配置大量的簡化了IT工作,例如服務目錄編纂、資安和管理。
在重新設計的架構中,我們在Hadoop叢集中的工作幾乎100%都是自動化。這讓IT團隊騰出了大量的時間和精力,能將精神用在服務組織內外的客戶,並幫助銀行善用資料工程的準則,以應對快速的變化。
我們花了將近兩年的時間將所有應用程式轉移到新的雲原生架構。隨著科技發展,我們已準備好繼續擴充及加快我們的計算框架,讓應用程式和業務部門都能受益,並為企業創造價值。遷移到軟體定義儲存系統和使用固定計算單元(immutable compute)是建構大規模大數據平台的一個重要里程碑。
對於大數據而言,運算工作是一個不斷成長的挑戰,需要不斷尋求創新技術新來減少運算足跡和加速批次處理。
GPU計算
大多數傳統資料湖泊都是建構在傳統的多核心CPU技術上。即使顯著地加強了儲存、記憶體和網絡子系統,幾乎每個企業用戶和系統都被效能所限制,無法使用企業資料湖泊或資料倉儲中的資料進行瞬間爆量的資料分析。
GPU技術是由Nvidia等公司多年的研發開創,過去十年在產業中快速成長。在GPU中所含的數千個核心讓它本身就能夠平行處理資料。
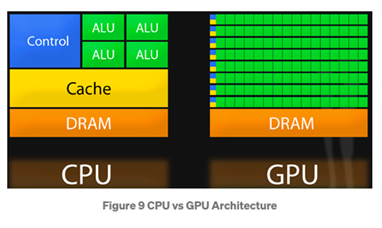
GPU通常被放入伺服器中用以增強主要的CPU。它們還提供了更快的I/O,增加CPU和GPU之間往返傳輸的資料量。
GPU加速器能夠在執行繁重運算任務時帶來巨大的優勢,但GPU的價格昂貴且要能為應用程式採用亦有一定的學習曲線。因此星展銀行使用vSphere Bitfusion虛擬化硬體加速器(如GPU)來支援AI、ML的工作。vSphere Bitfusion將實體資源從伺服器的特定環境中分離。
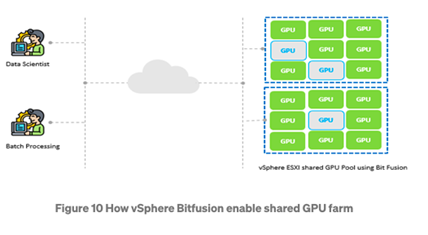
此平台可在虛擬化基礎架構中共享GPU,作為網路可存取的資源池,而非讓個別伺服器中的資源獨立。Bitfusion可跨AI框架、雲端、網路以及在虛擬機、容器和Jupyter notebook等環境運行。隨著新硬體加速器的導入,Bitfusion隨時可以將其虛擬化。
星展銀行選擇vSphere Bitfusion的原因有:
a. 可任意動態配置GPU — Bitfusion可拆解GPU運算單元並可向連結遠端儲存單元一般動態地將GPU連接到資料中心的任何位置。
b. 提高部分GPU效率 — Bitfusion能利用任意部分的GPU。在測試及開發階段支援更多用戶。
c. 標準化加速器存取 — 在基礎架構中充分利用GPU,並隨著標準的制定,整合不斷發展的技術。
d. 應用程式執行時間虛擬化 — Bitfusion在程式執行時根據CUDA調用GPU資源,最大限度地提高網路中任何GPU伺服器的利用。
e. 與任何應用程式一起使用 — Bitfusion是一個通透層(transparent layer),它可與任何工作、框架、容器或Jupyter運作。
星展銀行使用Apache Spark作為Cloudera框架的一部分,Cloudera框架是一個開源的通用叢集運算框架,為大規模資料處理提供整合分析引擎。
Spark利用pyspark函式庫來加速Python程式碼,快速運算Pytorch、Tensorflow等套件。但這也意味著批次程式必須將Scala改寫成Python。
我們利用Apache 3.0並結合了基於CUDA-X AI的開源函式庫RAPIDS。Apache Spark的RAPIDS Accelerator具備了RAPIDS cuDF函式庫的強大功能和Spark分散式運算的優點。它使開發人員不需要修改Spark程式碼,就可以在GPU上運行並加速。
RAPIDS cuDF函式庫的啟用可透過設定spark configuration classpath和以下設定來達成
spark.conf.set(‘spark.rapids.sql.enabled’,’true’)
在開源社群和雲端供應商的大力推動之下,資料架構和大數據領域不斷快速發展。星展銀行致力於在科技與現代化資料架構下取得平衡,並確保我們的應用程式皆能具有良好的成本效益。
免責聲明和重要通知
本文章(英文)係由DBS LTD提供並經星展銀行(台灣)(下稱「本行」)翻譯為中文,僅供參考,本行及DBS LTD不對使用本文章所引起之任何損失或損害負任何責任。如您有任何疑問或欲參考本文章而為行事之依據,本行建議您諮詢您的專業顧問之意見,以保障您的權益。非經本行之事前書面同意,任何人不得對本文章為複製、轉載、引用、抄襲、修改、散佈或為任何其他方式之使用
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02