
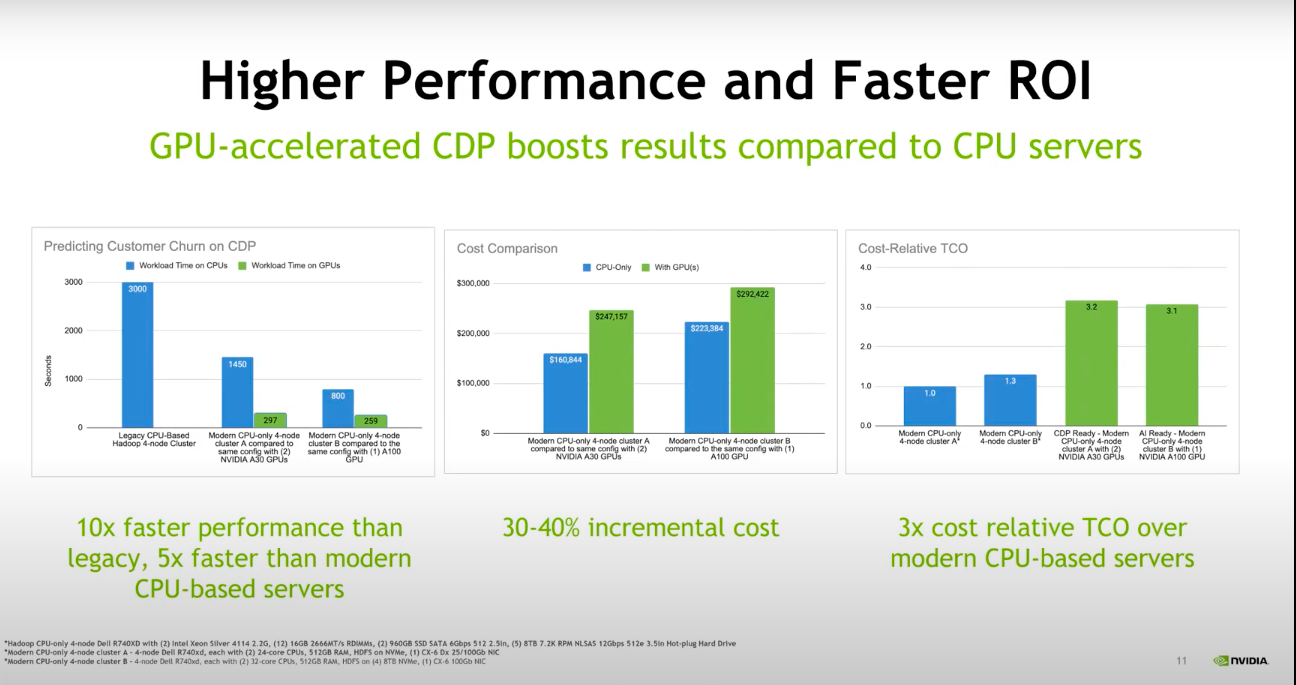
Nvidia指出,若分別以現代4節點的CPU叢集,以及相同配置的CPU搭上Nvidia A30 GPU,來支援Cloudera數據平臺的運算,後者的執行速度可達前者的5倍,雖然搭配GPU的成本會比單純使用CPU增加30~40%。
圖/Nvidia
企業級Hadoop大數據軟體商Cloudera近期在自家的數據平臺中(Cloudera Data Platform,CDP),整合了可在GPU上加速Spark的開源函式庫RAPIDS。透過這個新功能,原先在CDP平臺上,大多以CPU來執行的Spark工作負載,比如資料分析的擷取、轉換和載入(ETL)作業,就可以搭配GPU來執行,Cloudera宣稱,可以提升5倍全端(full stack)執行速度的成效。
RAPIDS是Nvidia開源釋出的CUDA加速函式庫,可以用來在GPU上執行端對端資料科學和分析工作流程。去年開始也能支援Apache Spark社群釋出的Spark 3.0,以Nvidia CUDA和開源框架UCX為基礎,來加速Spark SQL、DataFrame及Spark shuffle等功能,讓Spark工作能利用GPU平行處理和高頻寬記憶體傳輸的能力,來執行運算,且不需要改寫程式碼。
Nvidia也在自家開發者部落格上介紹,在開發ML的工作流程中,資料科學家大約有80%的時間花在資料預處理上,包括要先瞭解資料集,反覆進行資料清整、擷取特徵等,這個過程通稱為ETL,由於Spark是資料預處理和特徵工程的常用工具,也常被用於這個環節。不過,因Spark過去的版本不支援GPU運算,所以資料科學家和工程師大多在CPU上執行ETL,再將資料傳送至GPU進行模型訓練。但隨著資料量增加後,這個流程也面臨一些挑戰。
Nvidia資料科學產品部資深總監Scott McClellan指出,這對企業帶來的挑戰,一是在資料量不斷成長、迭代訓練的過程中,會花費大量的時間;二是要建立大規模CPU基礎架構,需花費大量金錢;三是在執行大規模資料處理的過程中,需要不斷重構程式碼、交接執行運算,會增加從資料工程到模型訓練每一次循環的時間成本。為此,Nvidia開源了RAPIDS,試圖透過GPU來加速資料處理的執行效率。
Cloudera將RAPIDS整合到自家數據平臺中
去年,Nvidia與Cloudera展開合作,Cloudera更在今年夏天,將RAPIDS整合到自家的CDP產品中,正式在CDP中推出以GPU加速Spark的功能。Cloudera機器學習部門副總裁Sushil Thomas表示,將RAPIDS整合到CDP後,使用者執行Spark工作時,完全不需要修改程式碼,Spark核心引擎會在偵測到GPU運算資源後,自動根據工作負載的任務類型,比如是屬於列式儲存(Row-oriented)或直式儲存(Column-oriented)的資料模型,在GPU或CPU上排程執行特定工作。也就是說,Spark核心引擎會自動完成在CPU與GPU之間的運算轉換。
Cloudera數據平臺結合RAPIDS套件後的架構示意圖。
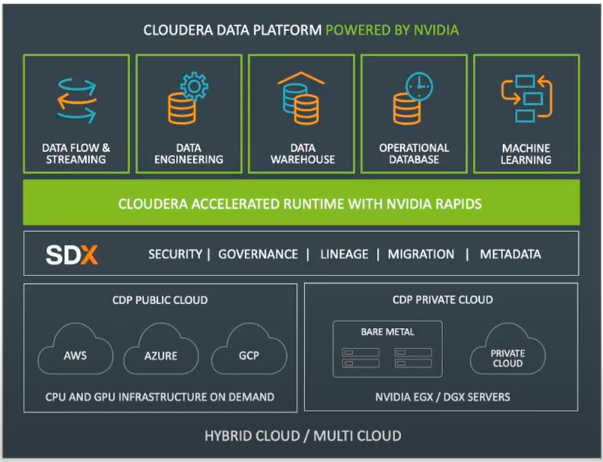
Sushil Thomas更指出,採用GPU來執行Spark之後,可以在同樣時間內,增加資料處理迭代循環的次數,來提升模型訓練的準確度,更能將全端執行速度提升5倍。
Nvidia也提出一份數據,來比較在CDP上以CPU或GPU來執行數據分析的成效。若分別以現代4節點的CPU叢集,以及相同配置的CPU搭上Nvidia A30 GPU來進行運算,後者的執行速度可達前者的5倍,不過搭配GPU的成本會比單純使用CPU增加30~40%。
目前,這項功能僅限於CDP的私有雲產品,Sushil Thomas指出,對於公有雲的支援會在近期上線。這項功能主要瞄準採用私有雲的大型客戶,包括金融、醫療這類具有大量資料工程與資料科學任務需求的產業,目前也已經用於美國國稅局(IRS),能在超過300TB的龐大資料庫中,找出有助於識別身份盜用或其它詐欺行為的模式。
Cloudera是提供Apache Hadoop商用版本的主要廠商之一,目前有超過2,000家客戶,主要產品是數據平臺CDP,提供Hadoop、Spark等大數據分析服務。
熱門新聞

2026-03-06



2026-03-06

2026-03-09


2026-03-09

2026-03-09