")
除了K匿名法和GAN資料生成法,工研院巨資中心還有一套方法來進行多組織的資料去識別化任務,也就是先利用GAN在近端產生資料,再以統計橫向整合來彙整資料,最後匯出。(資料來源:王邦傑)
在AI大浪的席捲下,如何兼顧大數據分析和資料隱私?工研院巨資中心專家分享3種作法,包括常見的K匿名法、GAN生成資料法,以及從GAN衍生出的多機構專用統計整合法。甚至,「用GAN生成的無涉及個資假資料,與完全用原始資料的準確度相比,誤差值僅在5%以內,」工研院巨資中心資料隱私與平臺技術部經理王邦傑強調。這些方法,也是工研院用於財政資訊中心、健保署健保大數據的資料去識別化作法。
不只如此,他們也將在金融、電商和醫療資料去識別化的經驗,延伸至聯合學習(Federated Learning),去年展開PoC驗證,提出多種方法來解決聯合學習資料品質參差不齊的問題。今年,他們聯手臺灣人工智慧實驗室(AI Labs),要把聯合學習推廣到各產業。
著重資料可分析性,資料去識別化應聚焦間接識別符
「許多資安廠商、資訊業者認為,資料去識別化只要將資料加密或Hash轉換就好,」但工研院巨資中心資料隱私與平臺技術部經理王邦傑指出,大數據時代著重的是「資料背後代表的意義,也就是資料的可分析性。」因此,資料去識別化不該只是加密資料,而是要在保護個資的條件下,也保有資料可分析性。
但是,這種資料去識別化該怎麼做呢?
這得先了解個人資料的組成。根據個資法定義,個人資料可分為直接識別符和間接識別符,直接識別符就是姓名、身分證字號等資料,而年齡、種族和郵遞區號等就是間接識別符。
「間接識別符無法判斷特定個體,但攻擊者可從間接識別符的組合,來推導出特定個體,」因此,去識別化就是針對可識別資料、間接識別符下手,讓資料中足夠多的個體,對應到同一組間接識別符,將個體特徵「模糊化,」隱身於群體中。
在這些條件下,他表示,有3種常見的去識別化核心技術,包括傳統統計揭露控制(Statistical Disclousure Control,簡稱SDC)、K匿名系列演算法,以及差分隱私演算法(Differential Privacy)。
王邦傑解釋,SDC是個傳統老方法,已存在20多年,K匿名演算法則相對年輕,問世約10年,「不過,現在會需要更強健的K匿名演算法。」至於差分隱私,則是近幾年興起的熱門資料去識別化方法,目的是在資料集中加入雜訊,來混淆視聽。
工研院也有幾套資料去識別化作法,在保有資料可分析性的情況下,也兼顧資料隱私。他們的方法除了上述的K匿名演算法外,還自行發展出2套去識別化方法,一個是GAN資料生成法,另一個是GAN生成法衍生的多機構去識別化資料融合分析法。
工研院推薦這3種資料去識別化方法
1. K匿名法:傳統常見作法,利用資料藏匿和資料泛化,將確切值隱藏在一個區間達到匿名效果。直覺、容易使用的作法,但工研院建議K值大於20,較不易遭攻破。衛福部和財政資料中心曾用此法來開放政府資料。
2. 完全用GAN生成假資料:業界資料保護主流作法,用GAN生成器模型產生接近真實資料的合成假資料,來達到匿名效果但又有分析力。工研院經驗,GAN生成資料的分析準確度,與原始資料間相比,兩者的誤差值可在5%以內。
3. 用GAN去識別化再融合分析:工研院整合GAN和傳統統計作法,可用於多機構間的資料去識別化和資料整合分析。先在各機構端以GAN生成資料,再靠統計匹配作法,橫向整合資料後得到,可分析的整體性資料。工研院建議,2家機構整合的效果最佳。
資料來源:工研院,iThome整理,2021年5月
工研院資料去識別化第1招:K匿名法
K匿名演算法是工研院常用資料去識別化法之一,「它雖然不是最強的保護方法,但卻是最直覺、最容易操作的去識別化方法。」王邦傑點出這個方法的優點。這個作法的核心在於資料藏匿(Supression)和資料泛化(Generalization),也就是將資料進行更廣義、更抽象的描述。
但只是將部分資料遮掩,比如電信帳單中遮掩幾碼的電話號碼,或是遮掩姓名中間字的作法,「就不是可分析的資料了。」他認為, 用K匿名法將資料去識別化時,得將年齡、地址等確切資料隱藏在一個區間,比如將33歲改為31至35歲、將確切門牌號碼改為住在忠孝東路,或是將身高隱藏在181至185公分的區間。如此一來,「在資料顆粒度變粗的情況下,會有更多人符合這些條件組合, 要從中去找出特定人, 也就更難。」這就達到了隱匿效果。
所以,K匿名法中的K就是指,用不同間接識別符的組合來搜尋時,至少有K個個體符合,比如搜尋上述「31至35歲、住在忠孝東路、身高181至185公分」條件的人,至少有5個,那K就是5,也就是最小能保護的基準值。
同時,王邦傑也建議, K 值要大於20才不容易被攻破。幾年前,工研院也用這個方法,來輔導衛福部和財政資訊中心的資料去識別化專案,協助政府開放資料。
工研院資料去識別化第2招:完全用GAN生成的合成資料
工研院資料去識別化的第2招,是利用對抗生成網路(GAN)來產生合成資料,並用這些生成資料完全取代真實資料,來避免個資洩漏的問題。
這個做法的原理是,將原始資料輸入GAN生成器(Generator),來產生具有原始資料特性的合成資料,接著用GAN鑑別器(Discriminator)來評斷這些合成資料的擬真度,藉此提高合成資料的真實性。這個過程會反覆進行,直到生成器產生的資料成功騙過鑑別器為止。
王邦傑指出,GAN生成法是時下業界資料保護的主流作法,一些專家甚至會加入差分隱私,來提高去識別化強度。工研院也自2017年開始,用GAN生成器模型來產生接近真實資料的合成資料,進行資料去識別化。不過他也提醒,採用該方法「要考量的是,如何讓GAN生成的資料,夠接近原始真實資料。」
除了不會洩漏個資的好處,這個方法也能彌補傳統方法的缺點,王邦傑解釋,傳統在真實資料中加入雜訊(假資料)來混淆視聽,會造成運算成本增加,也會降低日後資料分析的準確度。「完全採用合成資料,就不會有這些問題。」
就資料可分析性來說,工研院採用GAN生成資料的準確度,與完全用原始資料的準確度相比,誤差值在5%。甚至,「狀況好時可達1%、2%。」王邦傑強調。
工研院資料去識別化第3招:用GAN去識別化再融合分析
在GAN的基礎上,工研院還延伸出另一套方法,可以作為多機構的資料去識別化和分析需求之用。這個方法整合GAN和傳統統計整合作法,可分為3個步驟,包括在機構端以GAN生成資料,再以統計學橫向整合(Join)這些資料,最後,匯出這些資料就可以得到具有分析力的去識別化資料集。
舉例來說,假設銀行A、電商B分別擁有資料集X、Y和X、Z,其中X是兩家企業的共通資料,也就是共通客群,而Y和Z是與X相關的資料。為了在兼顧個資隱私的條件下整合兩家資料,雙方得先將手上的資料集X、Y和X、Z去識別化,也就是以GAN生成近似原始資料的合成資料。
接著,工研院透過橫向整合(Database join)、資料配對(Record linkage)、統計匹配等方法,來整合這些生成資料(也就是隨機配對),完成後再匯出整合的資料集X、Y、Z,來進行分析。
王邦傑解釋:「這種隨機分配並不會影響整體資料可分析性,因為在統計學上,資料走向是一樣的。」工研院也用這個方法進行不少模擬, 不過, 他認為,這個方法最適合用於兩家機構的資料整合, 若機構數量更多, 就會影響資料的可分析性,也就是後續運用於AI的準確度。

攝影/王若樸
工研院巨資中心資料隱私與平臺技術部經理王邦傑指出,在大數據時代下,企業的資料去識別化應保有資料可分析性,而非只進行資料加密或Hash轉換就好。
去識別化後的資料分析準確度多高?工研院用5種ML模型來評估
資料去識別化的目的在於分析,但去識別化程度會影響分析準確度。為衡量這些做法的資料可分析性高低,工研院也自建一套評估工具,會使用5種ML演算法,包括XGBoost、SVM、隨機森林、Linear SVC和Logistic regression,來測試資料去識別化後的AI分析準確度。為了評估,同一批分析資料,還會訓練出三種AI模型來比較。
測試前,得先確認生成資料欄位屬性,比如是類別型或數值型,才開始使用ML演算法,針對想要分析的資料欄位,利用原始資料和合成資料來訓練模型,交叉比對準確度。
例如,可將訓練資料和測試資料按比例分為80%和20%, 首先完全使用原始資料來訓練、測試模型, 這就是模型一。模型二是用80%合成資料訓練模型,再以20%原始資料來測試模型。假設模型一的準確度與模型二相近,就表示「生成資料能以假亂真,」王邦傑說。
接下來,還可以完全使用合成資料來訓練、測試建立第三種模型(模型三),它的目的是檢驗是否有過度擬合(Overfitting)問題。這個檢驗標準,是與模型一相比,要是模型三準確度高於模型一,就代表過度擬合。
有了模型一、二、三和各5種ML演算法的訓練與測試分數後,工研院自建的評估系統也會依類別列出5種演算法,各自在這三種模型中的表現,讓使用者從中判斷去識別化的資料可分析性。
工研院已經將資料去識別化做法和評估工具,開發成一套解決方案,內有多種去識別化核心演算法、風險和資料可用性評估模組,以及資料處理模組等,這套解決方案可平行化部署在大數據框架Hardoop、Spark上,也能單機部署在個人電腦上。王邦傑指出,不少政府、金融甚至是智慧製造業者,也用這套方法來處理資料去識別化。
投入隱私資料保護的新作法聯合學習
工研院巨資中心自2019年下半年也投入的聯合學習技術的研究,這是另一個不需揭露隱私個資又能提供資料分析性的新作法,更在2020年展開醫療聯合學習PoC,包括與工研院生醫所進行的痰音疾病預測。
聯合學習常見的模式之一是Server與Client模式,也就是透過發起人設置一套初始模型,讓各個Local端(即Client端)下載,用自家的資料來訓練,再將參數上傳到中央伺服器的母模型(即Server端的Global模型)來優化,如此反覆直到模型收斂。
不過,王邦傑發現,聯合學習本是要解決安全問題,「現在也衍生一些安全問題。」比如,醫院擔心Local端的訓練模型會偷走資料,或是Local端的模型遭破解而洩露資料、匯入錯誤資料,又或是Global模型會遭破解等等。
聯合學習還有資料中毒和Non-IID兩大挑戰
這就演變成聯合學習的兩大挑戰。首先是資料中毒(Data poison)問題,也就是Local端用錯誤資料來訓練模型,會破壞了整體聯合學習的Global模型表現。王邦傑坦言,這是個無法完全解決的問題,「但有技巧可以避免。」比如降低特定Local端模型在Global模型的權重,就比較不會造成資料中毒問題。
再來,因為聯合學習旨在保護資料隱私,Server端無法仔細檢視每個Local端用來訓練模型的資料, 因此當少數Local端模型表現異常時,Server端無法確定是不是資料中毒問題。這時,Server端就要考慮「Non-IID(Non-Identical Independent Data)問題,也就是該Local端的資料本來就異於常人。」這個現象,也是聯合學習常見的挑戰之一。
「Non-IID是指非完美分布的資料, 」王邦傑解釋, 在聯合學習中,若Client端的資料分布(Distribution)差距非常大, 也就是每個Local端模型表現差異極大時,會導致Global模型表現不佳,或是難以收斂。
面對這個問題,學術上也有幾種方法來應對,比如從各Client端挑選有共識的資料( 像是屬性類似的子資料集),先來訓練Global模型、縮小差距,待模型表現穩定後,再加入屬性差異較大的資料。
這種優先挑選屬性類似資料的作法,可透過資料增強(Data augumentation)來實現。資料增強是一種增加資料量的方法,將現有資料複製、稍加調整(如翻轉、剪裁、顏色修正等方法),來產生更多資料、擴充訓練資料集。
藉由這個方法,Local端可多產生一些性質類似的訓練資料,來強化該資料的占比,進而訓練出差距較小的模型。
有了這些技術經驗,工研院今年進一步聯手臺灣人工智慧實驗室(Taiwan AI Labs),投入跨政府部會成立的臺灣聯合學習產業大聯盟,擔任核心成員。
王邦傑透露,工研院將在聯盟中,協助制定特定產業的聯合學習標準(比如標註規則),並建立聯合學習生態系;同時,他們也會繼續探討聯合學習的技術問題,比如Non-IID,並尋找更好的解法。他們希望將在聯合學習在醫界的成功經驗,推廣到其他產業。
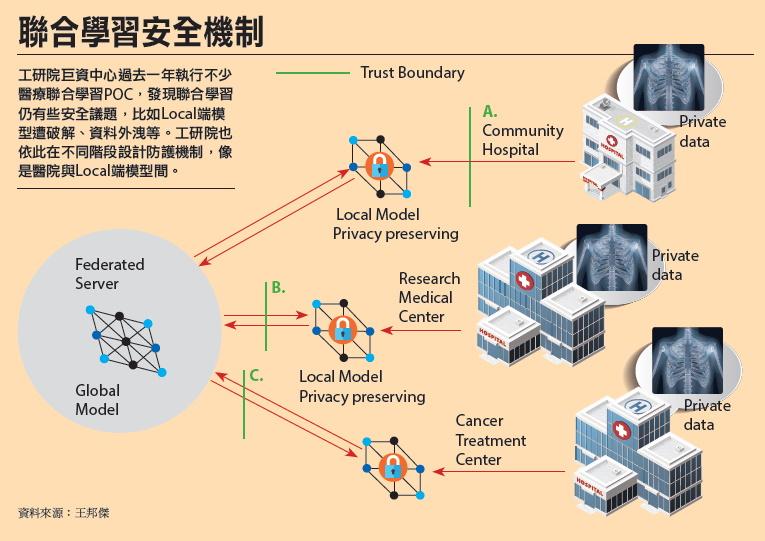
資料來源:王邦傑
工研院巨資中心過去一年執行不少醫療聯合學習POC,發現聯合學習仍有些安全議題,比如Local端模型遭破解、資料外洩等。工研院也依此在不同階段設計防護機制,像是醫院與Local端模型間。
國際資料治理組織近2年格外重視資料隱私
在國際電信聯盟電信標準化部門ITU-T旗下,有個為期兩年(2017年至2019)的資料治理專案組織FG-DPM,專門制定IoT和智慧城市相關的資料治理與AI框架,「是國際上腳步最快的資料治理組織,」親身參與該組織的工研院巨資中心資料隱私與平臺技術部經理王邦傑說。
FG-DPM 制定的架構涵蓋5 大層面,其中之一就是資料處理和管理面的隱私技術,以及對應的法規問題,凸顯了組織對資料隱私的重視。就其他4個層面來說,還包括資料的使用情境、需求和應用服務,以及資料處理管理(DPM) 框架、架構和核心元件,再來是資料共享、互通性和區塊鏈管理等,最後則是資料經濟化和貨幣化。原本杜拜萬國博覽會是第一個要實驗資料貨幣化的場域,但因爲去年疫情嚴峻、參訪人數受限制,導致成效不理想。
「FG-DPM領先其他國際組織,快速定義出完整的資料治理建議和應用框架,」王邦傑指出,該組織產生的15份報告,也交由ITU標準組織旗下的小組參考,包括醫療AI(FG-AI4H)、IoT智慧城市(SG20)、多媒體(SG16),以及機器學習於5G未來網路(FG-ML5G)等。他直言,FG-DPM制定資料隱私和AI框架的舉動,勢必帶動其他國際組織跟進,在資料治理上更有著墨。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23