
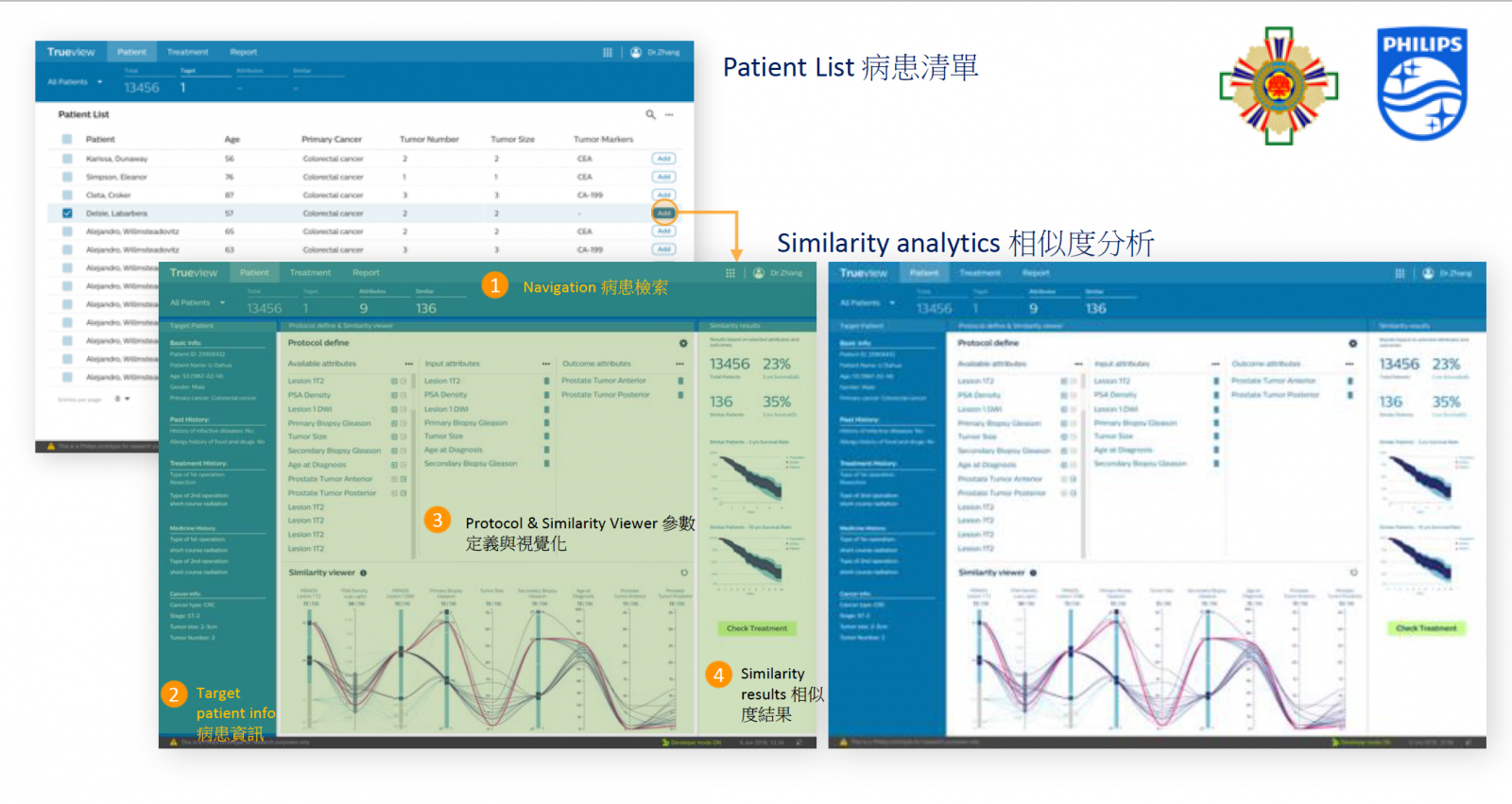
臺北榮總聯手飛利浦,利用數十年癌症登記資料庫的大腸癌資訊,來訓練一套AI系統,可根據新患者狀態來與歷史資料進行相似度分析,找出合適的治療決策,促進醫病溝通。
臺北榮總
重點新聞(1225~0101)
臺北榮總 大腸癌 飛利浦
面對大腸癌心慌慌?北榮用AI打造專屬客製化療法
臺北榮總聯手飛利浦,以累積數十年的癌症登記資料庫大腸癌資料,來訓練一套AI系統,透過與歷史資料的相似度分析,來提供病人預後預測以及治療歷程建議,有助於醫病溝通、共同制定最佳治療決策。目前系統原始模型的相似度分析準確率為82%,雙方期望將準確率提高至90%。
根據衛福部2020年癌症登記報告,大腸癌發生率為全臺第一,每35分鐘就有一人罹患。而大腸癌不同期數有不同的治療方法,比如第一、二期以手術為主,第三期則需加以化療,第四期則包括手術,加以化療、標靶和免疫治療等方法輔助。為根據每位病患的病徵找出最佳治療方法,臺北榮總利用患者基本資料、病史、腫瘤大小與期別、手術方式與癌細胞組織化驗結果等資料,建立多套演算模型,可針對罹癌病患病程中的不同時間點來計算,並提供分析結果給醫生和患者,做為治療決策參考。
目前,這套系統已能預測大腸直腸癌第一至三期開刀術後的副作用程度,以及後續化療的必要性,甚至還能評估不同治療方法的存活率。(詳全文)
AI偏見 行銷領域 孫民
AI偏見人人喊打?孫民:在特定行銷領域反而有其好處
剛結束的2020年,AI偏見人人喊打的聲浪依舊高昂。繼前年ImageNet大幅修改有爭議的標籤後,MIT撤回8千萬張Tiny Image資料庫中涉及種族歧視的影像,來降低偏見,Amazon、IBM和微軟皆因擔心通用樣本代表性不足、造成種族歧視和技術濫用,選擇退出人臉辨識領域,而把歐巴馬變成白人的臉部重建模型StyleGAN演算法PULSE,再次點出AI偏見議題,也引爆Facebook首席科學家Yann LeCun和前Google AI倫理專家Timnit Gebru的激烈辯論,各自認為偏見來自資料或AI模型本身。
上述多是偏見在AI通用性上的爭議,不過,Appier首席科學家的孫民最近在媒體投書指出,AI偏見在行銷領域並非全然的壞事。他說明,AI偏見來自訓練模型的資料,而非模型本身。因為,AI是以各種機制取得的資料訓練而成,這些資料包括輸入資料、特徵以及標籤,來引導AI決策規則。也因此,模型會對某些資料產生較好的結果,卻對其他類型的資料產出不良結果。
然而,對行銷領域來說,透過偏見數據來訓練AI模型,「會比完全中立來得更好。」他解釋,對行銷人員來說,如要服務特定客群,以該客群的資料來訓練模型反而更有利,甚至能降低初期部署的成本。比如,一家針對18至25歲年輕女性銷售時尚產品的公司,在使用AI推薦引擎時,能利用原本的偏見數據(編按:偏重蒐集年輕女性,而非蒐集所有人的初始資料集),來提供目標客群購買建議。而顧客做出更多決策時,模型也能從中學習、做出更精準的推薦。他認為,當模型與訓練資料具有相同偏見時,這些偏見就能在模型部署初期發揮良好的成效。因為要蒐集到公平無偏見的資料曠日費時,他反而認為:「利用這樣的數據偏見,可以降低 AI 部署的初期成本,因為蒐集無偏見數據的成本相對較高。」
但他也呼籲,AI偏見仍有可能帶來嚴重的後果。比如,以特定年齡群的數據來訓練模型,初期效果可能不錯,但一陣子後,銷量可能不見起色。這時,可透過改變資料搜集方式和A/B測試,來觀察模型表現,並了解模型評估特定特徵或特徵組合的原理。(詳全文)
圖機器學習 Graph AutoGL
AutoML還不夠,北京清華開源AutoGL來自動執行圖學機器學習任務
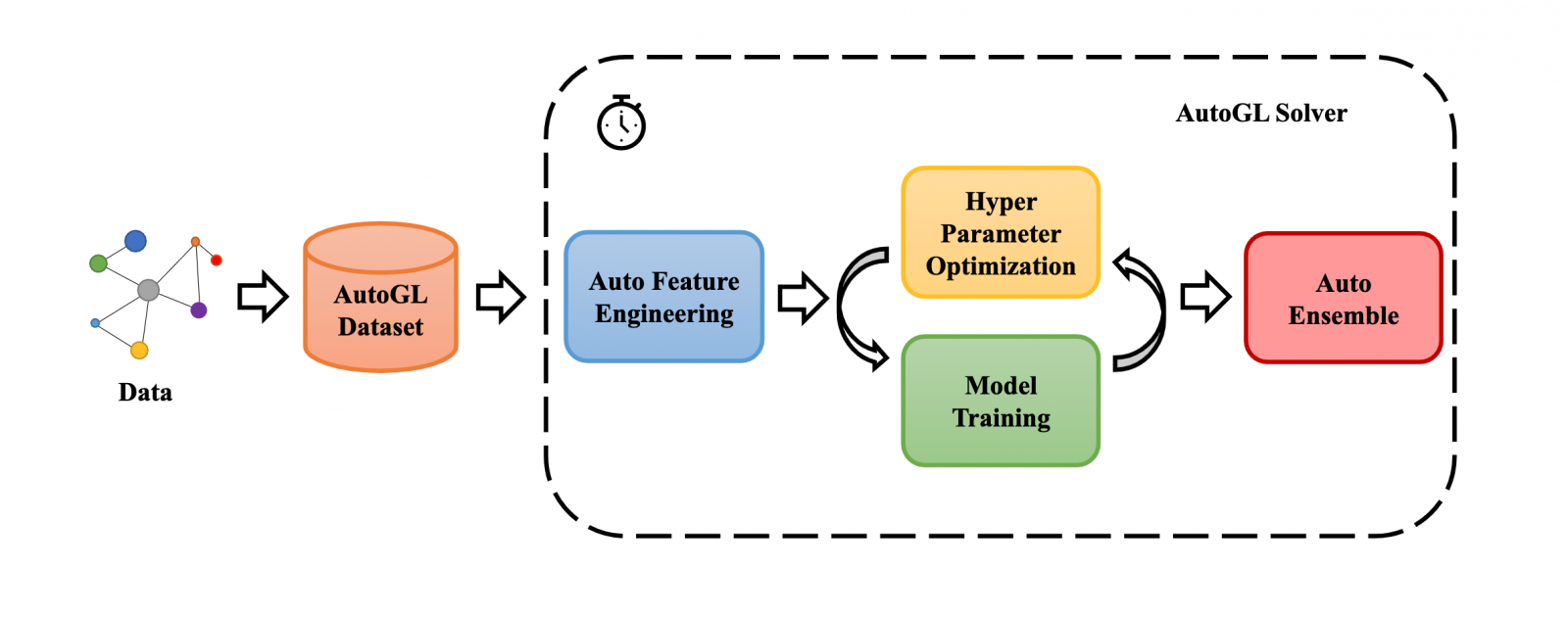
北京清華大學日前在GitHub上開源一套用於圖學(Graph)運算的AutoML工具:AutoGL,能自動執行圖學資料相關的機器學習任務,特別是圖學學習(Graph Learning)中最常見的節點分類(Node Classification)和圖學分類(Graph Classification)任務。
圖學是用來描述事物間關係的結構,由節點和邊組成。而圖學機器學習可解決許多複雜的研究領域,像是蛋白質建模、新藥開發、社群媒體分析、假新聞、金融風控等。但圖學機器學習非常複雜,難以大規模擴展應用,且圖學資料的結構、內容和任務也可能相差甚遠,很難自動進行機器學習模型運算。
不過,北京清華嘗試用AutoML的思維來設計AutoGL工具,以解決這個問題。只要上傳訓練用的資料集,可以使用包含大規模圖特徵學習工具包CogDL和圖神經網路庫PyTorch Geometric(PyG)中的資料集模組。這些資料會進入AutoGL Solver,此時會透過4個模組來自動訓練,包括是特徵工程(Feature Engineering)、圖學習模型訓練(Graph Learning Model)、超參數優化(HPO)以及模型自動整合(Auto Ensemble)。目前支援Python 3.6.0版本和PyTorch 1.5.1或以上。(詳全文)
PaddleHelix 生醫演算法 百度
百度開源生醫領域專用的AI運算平臺PaddleHelix
百度日前在深度學習開發者大會上,宣布釋出生物運算平臺PaddleHelix,鎖定生物醫藥、疫苗設計和精準醫療三大領域,開源一系列演算法和模型,包括RNA二級結構預測、大規模分子預訓練、藥物-靶點親和力預測以及ADMET成藥性預測等。
其中,在精準醫療領域,PaddleHelix針對臨床資料、蛋白組資料、基因組資料、單細胞資料等不同類型資料,提供特徵學習模型、藥物反應模型、疾病預後模型等,要助醫療人員更準確地分群和描繪個體,找出最適合的治療決策。(詳全文)

MuZero DeepMind 環境規畫
DeepMind新作MuZero,不懂遊戲規則也能快速規畫行動
Alphabet旗下AI子公司DeepMind近日發表新一代AI系統MuZero,能在完全不知規則的情況下,熟悉圍棋、西洋棋、將棋,以及57款Atari遊戲,效能大幅超越現有最佳的DQN、R2D2與Agent57系統,可望用來解決現實生活中,規則太複雜或完全不知規則的各式難題。
MuZero的特點是,只在乎影響決策環境的最重要因子,比如,棋子現在位置的價值、最佳行動的策略,以及上一個行動的成效等。深度神經網路就從中學習,來理解採取特定行動時產生的結果,並依此展開規畫。經DeepMind測試,MuZero除了在效能上擊敗前幾代AI系統,要是賦予MuZero更多的演算時間,還能大幅提高表現。研究者認為,當MuZero具備學習環境模型的能力,可用來解決機器人、工業系統或其它未知規則的混亂現實環境中,所存在的新挑戰。(詳全文)
TensorFlow 2.4 分散式訓練 GPU
TensorFlow 2.4出爐,主打更多分散訓練策略和NumPy支援
深度學習函式庫TensorFlow釋出最新版本2.4,支援新的分散式訓練策略,Keras也更新了混合精度功能,加速模型訓練工作。此外,TensorFlow 2.4還提供Python開發者數值運算函式庫NumPy支援。
進一步來說,TensorFlow中分散式訓練模組tf.distribute更新兩個重要策略,讓開發者可以不同方法進行分散式運算。首先是多工作節點鏡像策略MultiWorkerMirroredStrategy API進入穩定階段,而參數伺服器策略ParameterServerStrategy API和自定義訓練迴圈,則開始提供實驗性支援。
在新版中,Keras混合精度已成穩定API。大多數TensorFlow模型都使用float32資料類型,但是部分像是float16低精度類型,使用較少的記憶體,因此在同一個模型中,同時使用32和16位元浮點數,可提升訓練速度,而使用混合精度API,可讓模型獲得3倍效能,在TPU上效能提升60%。(詳全文)
Nvidia AWS市集 NGC AI軟體
Nvidia聯手AWS,21種熱門NGC AI軟體可從AWS市集下載了
Nvidia聯手AWS,把21種NGC雲端軟體資源放到AWS市集上,讓用戶直接下載、免費在AWS雲端平臺執行NGC軟體和服務。Nvidia在2017年釋出NGC軟體資源,已有25萬不重複用戶,NGC目錄中的AI容器、預訓練模型、應用程式框架、Helm圖表和其他機器學習資源,已突破100萬次下載。
現在,AWS是第一個提供NGC軟體資源的雲端服務供應商,AWS使用者可更簡單部署Nvidia GPU工作負載。在AWS市集中的NGC軟體,包括21個熱門的GPU加速AI軟體,像是Nvidia AI、DeepStream SDK、Clara Imaging、Merlin和RAPIDS等框架與工具,可用於醫療保健、推薦系統、電腦視覺和資料科學各領域。(詳全文)
貝氏加速器 IBM AI偏差
IBM推出貝氏最佳化加速器,讓產品設計模擬速度更快
IBM發布貝氏最佳化加速器(Bayesian Optimization Accelerator),以AC922伺服器為基礎,提供先進的通用參數最佳化方法,能找出複雜真實世界問題的最佳解,縮短產品和設計團隊的設計時間。
貝氏最佳化加速器是由IBM研究院開發的先進通用參數最佳化工具,用戶只需要定義設計變數、目標和限制,最佳化引擎就能計算出最佳解。貝氏最佳化加速器是一個完整的設備,包含了硬體、軟體和安裝服務,用戶只輸入少量的起始資料,貝氏最佳化加速器就能開始平行擴展運算,大幅降低運算時間。此外,貝氏最佳化加速器能以89%的精確度,找到可追蹤且可解釋的最佳解決方案,且因為不需先驗資料(Prior Data),也就消除了產生偏差的可能性。 (詳全文)
圖片來源/北京清華大學、百度、臺北榮總
AI趨勢近期新聞
1. Nvidia推出端到端機器人增強學習模擬環境Isaac Gym
2. 富士通研究人員發現AI藝術生成系統,普遍存在種族與性別偏見
3. IBM 攜手新光人壽,打造AI簽名辨識系統
資料來源:iThome整理,2021年1月
熱門新聞

2026-02-26


2026-02-27
")
2026-02-27

2026-02-27

2026-02-27

2026-02-27
2026-02-27