微軟更新了之前釋出的開源深度學習訓練最佳化函式庫DeepSpeed,該函式庫現在能夠使用新方法,訓練擁有數兆參數的機器學習模型,官方提到,DeepSpeed使用了被稱為3D平行技術的新方法,可以自動適應工作負載的需求,在平衡擴展效率的情況下,支援超大型模型。
在今年2月的時候,微軟釋出了DeepSpeed函式庫,並且介紹了該函式庫使用記憶體最佳化技術ZeRO,大幅改進大型模型訓練的規模、速度、成本和可用性,微軟使用DeepSpeed來訓練圖靈自然語言生成模型(Turing-NLG),當時發布的Turing-NLG,具有170億個參數和最高的準確性,為當時最大的語言模型。微軟在5月的時候,又發布了ZeRO-2技術,這項改進把模型訓練的參數規模,拉高到2,000億個,而且還能以極快的速度訓練語言模型BERT。
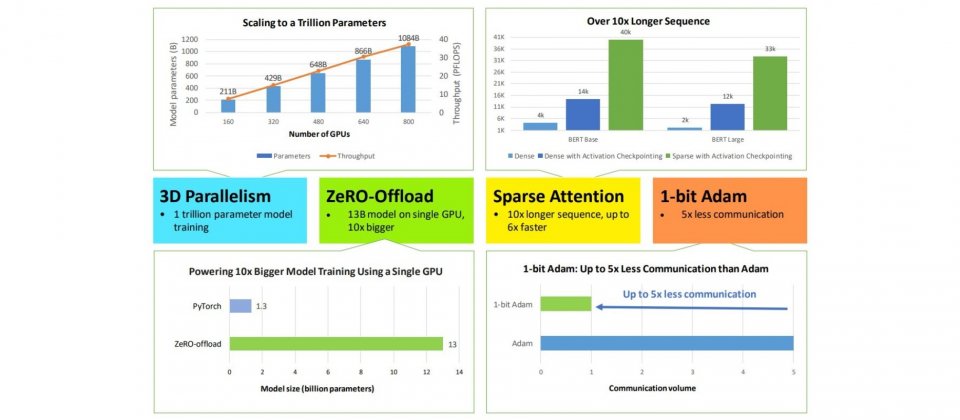
而現在,微軟又往前推進DeepSpeed的發展,添加了4項新技術,使得運算、記憶體以及通訊整體效率變得更好。這次的更新,包括微軟利用3D平行化技術,讓DeepSpeed能夠支援數十億到數兆參數的模型訓練,3D的意思也就是結合3種平行化方法,包括ZeRO資料平行化、工作管線平行化以及張量分割模型平行化。
微軟提到,透過3D平行化,DeepSpeed能夠適應各種工作負載的需求,支援超過一兆參數的超大型模型,並且達到幾乎完美的記憶體擴展,以及吞吐量擴展效率,另外,透過提高通訊效率,可以讓用戶在網路頻寬有限的叢集,以2到7倍的速度訓練數十億參數的模型。
在最新DeepSpeed版本,還能夠更好地支援單個GPU,只要一個GPU就能訓練上百億參數的模型。微軟擴充了ZeRO-2技術,使其同時能夠利用CPU和GPU記憶體來訓練大型模型,以擁有單個V100 GPU的電腦為例,DeepSpeed用戶能夠執行高達130億個參數的模型,而且不會把記憶體耗盡,這個可執行的模型參數量,是當前其他方法的10倍。
微軟提到,這些功能性擴展,將使得數十億參數模型的訓練更加普及,讓許多深度學習研究人員,能夠以更低的成本,訓練更大的模型。
熱門新聞

2026-03-06





2026-03-06

2026-03-09