
臉書結合多種資料訊號、可擴展的系統基礎架構,以及機器學習技術,建構了一個資料分類系統,以偵測語義類型,臉書提到,這對於以多種格式儲存資料的組織特別重要,先以分類系統分類資料,後續才能讓組織得以執行像是存取控制政策等,自動化隱私與安全相關的政策。
傳統的資料外洩防護(Data Loss Prevention,DLP)系統,是利用資料指紋進行辨識,透過監控端點以偵測與指紋相符的資料,但臉書表示,這種方法對於擁有大量且不斷變化資料資產的組織來說,不只難以擴展,而且也無法有效率的探索資料的所在。而臉書的新系統,強調採用可縮放的基礎架構,以多種訊號以及機器學習技術,透過持續訓練模型來解決這個問題,且可擴展應用到持久性與非持久性用戶資料,處理各種資料類型和格式。
臉書提到,資料通常以兩種形式進入組織,因此需要使用兩種不同的策略,來偵測和分類這些資料。對於離線儲存的持久性資料,系統必須了解資料資產的範圍,該系統會在不使客戶端和其他資源過載的情況下,收集每個資料儲存的元資料,並且建立成目錄,使得資料檢索更有效率。該系統會根據目錄中需要掃描的資產,個別啟動工作程式對資料資產進行實際的掃描。
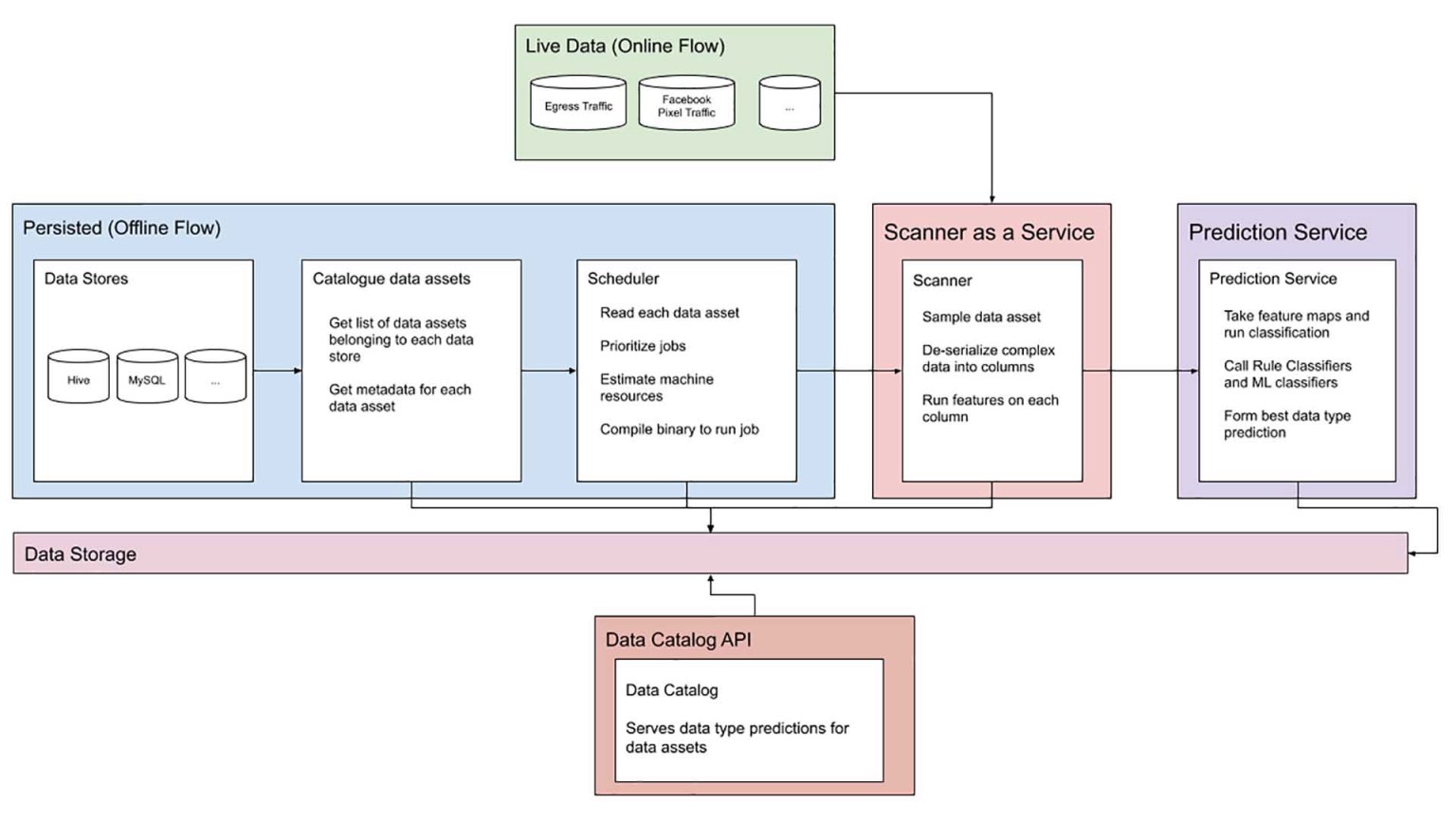
每個工作程式都是已編譯的二進位檔案,並對可用的新資料進行採樣,這些資料會被分成幾列,並以列為單位截取特徵,預測服務會根據這些特徵,啟用基於規則的機器學習分類,預測每列資料的標籤,所有下游程序都能夠從資料集讀取這些預測結果,也可以從即時資料目錄API讀取預測結果。
而線上的非持久性資料,也需要受到保護,因此系統提供了一個線上API,可對非持久性流量產生即時的分類預測,該即時預測系統可對流出的流量、流入機器學習模型的流量,以及任何的即時資料進行分類。另外,臉書也設計了特別的機器學習系統,來處理非結構化資料分類。
臉書提到,企業通常需要制定一套明確的隱私政策,以保護人們的個人資料隱私,因此企業需要了解哪些元資料與特定訊息相關聯,以加快政策執行並且減少錯誤發生。臉書的新系統為自家數十個來源的資料資產,進行資料類型分類,以確保隱私與安全政策的執行,而且比傳統資料外洩防護服務更靈活,能夠簡單增加對其他資料類型的偵測支援,並在有限的記憶體使用下,進行低延遲分類。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-09


2026-03-06

