史丹佛大學
重點新聞(0703~0709 )
卷積神經網路 史丹佛大學 電腦視覺
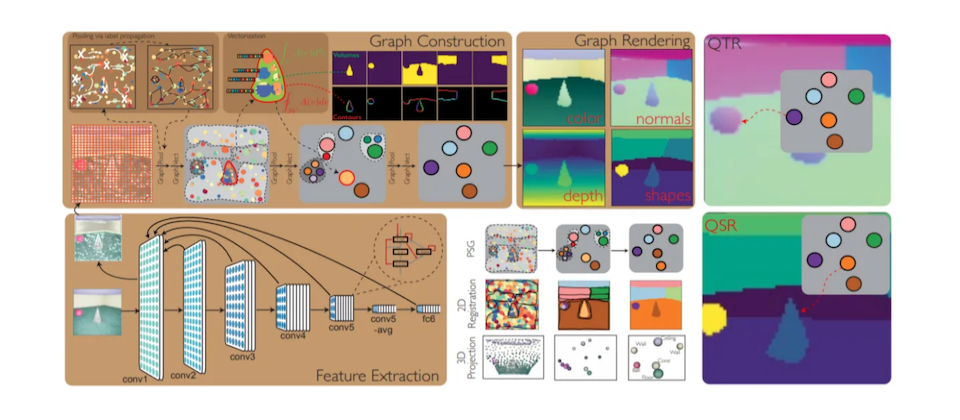
史丹佛聯手MIT發表PSGNet,打破CNN無法預測實體世界的瓶頸
卷積神經網路(CNN)是電腦視覺中常用的模型架構,擅長辨識物件,但它卻有個問題,也就是無法理解真實世界的物理原則,比如無法預測物體的動力學,因此限制了CNN在其他電腦視覺的應用。
為解決問題,史丹佛大學聯手MIT,設計一套自監督類神經網路架構PSGNet,可從輸入圖像來學習估計物理場景圖。進一步來說,只要輸入任意長度RGB影片,PSGNet就會重建出相同長度的RGB資訊,包括每幀的深度和法線圖預測,還有每幀的物體影像分割,以及對下一幀的空間點預測。這個方法,可以顯示PSGNet對場景結構的理解,團隊也表示,PSGNet在影像分割任務的測試中,表現優於其他非監督方法。未來,團隊打算將PSGNet擴展到CNN難以應用的電腦視覺任務中。(詳全文)

A100 GPU VM Google雲端
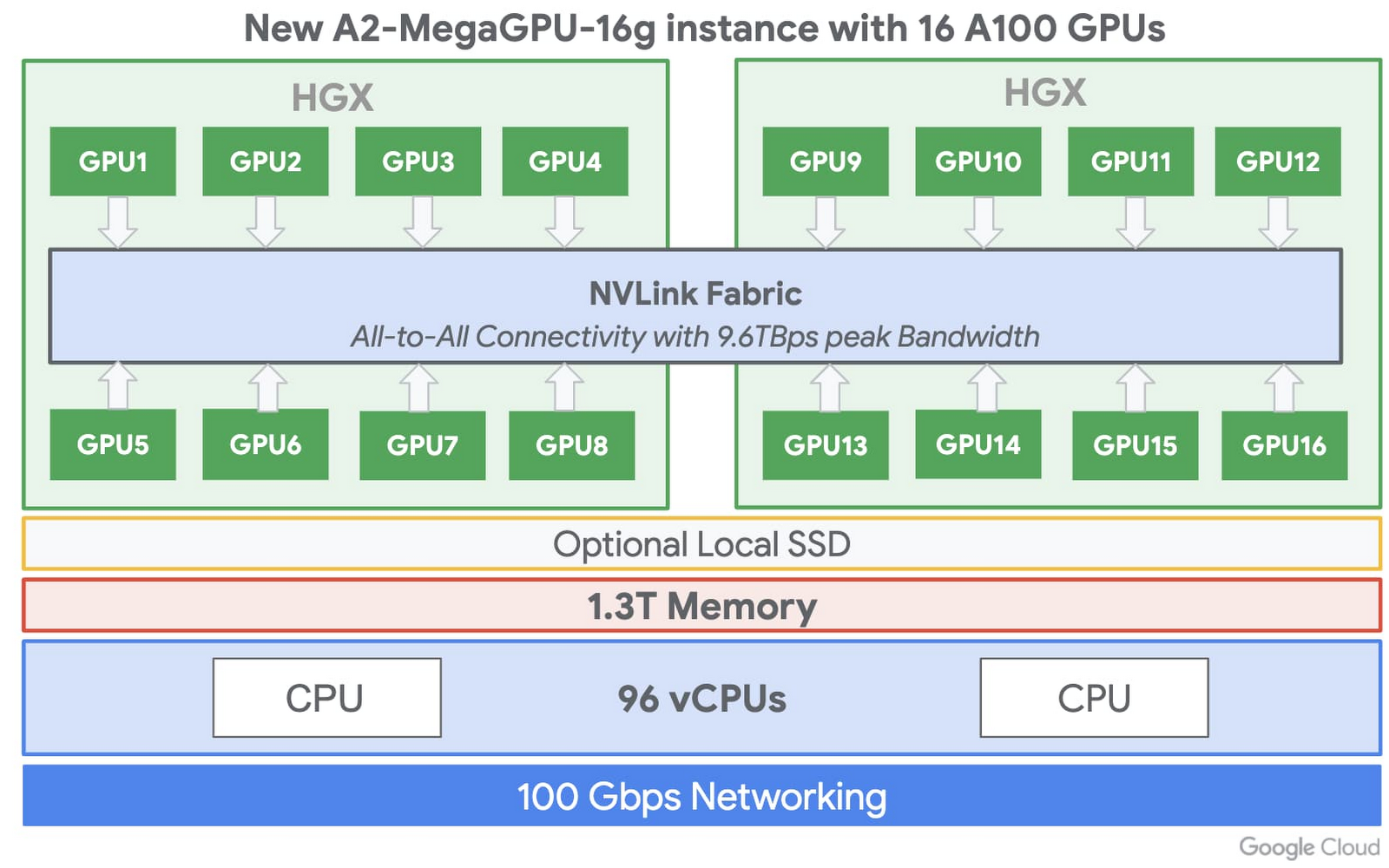
Google雲端開始提供Nvidia最新A100 GPU
Nvidia最新一代A100 Tensor Core GPU五月中才亮相,近日Google雲端就開始支援了。不過,目前只開放給特殊用戶從Google Compute Engine的A2虛擬機器來使用,今年稍晚才會正式開放所有用戶。
進一步來說,A100 GPU在AI模型訓練和推論上,效能比上一代GPU還要高20倍,這次一臺A2虛擬機器,最多還可使用16個A100 GPU,總共640GB的GPU記憶體和1.3TB的系統記憶體,來解決作業負載高的運算任務需求。而對於作業負載較小的用戶,Google Compute Engine也會提供較輕量的A2虛擬機器,來滿足特定應用程式的需求。Google指出,未來還會擴大 A100 GPU對自家Kubernetes Engine、Cloud AI Platform 和其他 Google Cloud服務的支援。(詳全文)
Mozilla 語音資料集 Common Voice
Mozilla發布最新版開源語音資料集,還要打造網頁版喚醒功能
Mozilla近日釋出最新的開源語音資料集Common Voice,與上一版相比,新增了36種語言,目前共有54種,總時數更高達7,226小時。不只包含語音,Common Voice還涵蓋了可用來訓練語音引擎的元資料(Metadata),比如說話者的年齡、性別和口音等,而這些資料,還會整合至Mozilla的開源語音辨識引擎DeepSpeech,以及Mozilla機器學習小組的模型中,要來推動文字轉語音(TTS)和語音轉文字(STT)研究進展。
不只如此,Mozilla同時也鎖定更細緻的分類和應用需求,發布了個別的資料集分類。這個分類包含了1萬多人共18種語言的語音片段,比如從數字0到9、「是」和「不是」、嘿、Firefox等。Mozilla表示,這個分類可用做基準測試,來評估以Common Voice資料打造的模型表現。此外,他們也會用來測試自家網頁喚醒詞的功能。(詳全文)
TensorFlow 差分隱私 漏洞評分
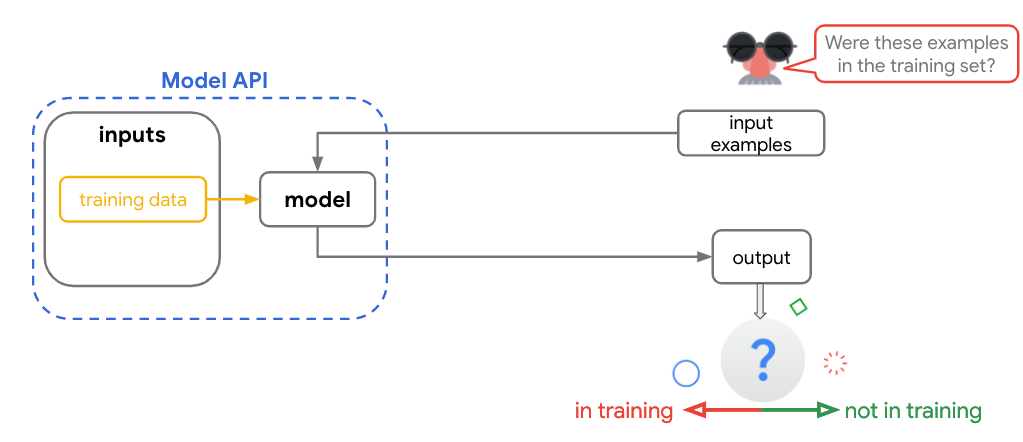
TensorFlow新隱私測試模組能幫你評分模型安全性
Google釋出了新的實驗性TensorFlow隱私測試模組,讓開發者可評估模型的隱私屬性。該模組會產生一個漏洞評分,來顯示模型是否會因訓練資料集而洩漏資訊。
去年,TensorFlow推出差分隱私(Differential Privacy)方法,透過在資料集中加入雜訊,來隱藏個資,但當時TensorFlow所使用的雜訊,可能嚴重影響模型的準確性。因此,Google決定以不同角度來處理隱私問題,打造了一個模組,以成員推理攻擊方法為衡量標準,來評估模型是否洩露資訊,並將模組開源出來。(詳全文)
Google 動物辨識 Context R-CNN
新添時序因素!Google新演算法改善攝影機辨識能力
Google開發一套新的物體偵測演算法Context R-CNN,能將時間因素納入考量,利用攝影機一個月拍攝到的影像,來提升電腦視覺模型效能,特別適合用來監控山路或生態的靜態攝影機。
進一步來說,Google改良兩階段物體偵測基礎架構Faster R-CNN,打造出Context R-CNN,利用同一臺攝影機中長達一個月的影像作為上下文(Context),來提高物體分類的正確性。這種方法能改進對新攝影機部署的通用性,不需要額外的人工資料標記。經測試,與Faster R-CNN baseline相比,Context R-CNN能從相同的圖像中,辨識出更多動物。(詳全文)

Cloud 臉書 TaBERT 自然語言
同時兼顧自然語言和資料庫查詢,臉書新模型TaBERT未來還可協助事實查核
臉書開發一套自然語言預訓練模型TaBERT,能從表格查詢結果中,以自然語言來回答如「哪個國家的GDP最高」等問題。研究人員提到,TaBERT是第一個跨結構化與非結構化資料的預訓練方法,克服了查詢對應到資料庫表格結構的挑戰。
有別於先前預訓練語言模型,都只使用自由格式的自然語言文字訓練模型,臉書這次使用了2,600萬張表格和關聯的英文句子,來訓練TaBERT,讓模型學習句子和資料庫的上下文示例,可同時進行對自然語言和資料庫的推理。臉書指出,未來,TaBERT還可用於事實查核和驗證應用程式中,因為第三方事實查核單位,通常也是仰賴靜態知識庫資料,而TaBERT能夠比對相關資料庫,並給出參考資料。(詳全文)

可信任AI LFAI IBM
IBM貢獻可信任AI工具給Linux旗下AI基金會
Amazon在電腦視覺和圖形辨識重要年度會議CVPR中,發表了一篇能合成服裝到模特兒身上的AI論文。這套系統名為Outfit-VITON,相當於虛擬試穿系統,可將參考照片中人物的穿著,合成到另一張照片的模特兒身上,研究人員指出,Outfit-VITON採對抗網路,由生成網路和判別網路的競爭產生最佳結果。
Outfit-VITON由三部分組成,形狀生成模型、外觀生成模型以及外觀修正模型,形狀生成模型會圈出要試穿的衣服形狀,並計算試穿模特兒的身材和動作。接著再輸出至外觀生成模型,來結合這個輸出的結果,成為模特兒穿著指定服飾的照片;再來才由第三個模型微調,保留商標和特殊圖案。團隊表示,這個系統比以前的系統產生更自然的結果。(詳全文)

AI研究雲 運算資源 資料集
美科技巨頭聯合頂尖大學,要推動國家級AI研究雲的建置
在AI領域著墨甚深的22家美國頂尖大學,近日加入科技巨頭如Google、AWS、微軟、IBM和Nvidia等行列,來替建置國家級AI研究雲的法案背書,也就是《美國國家AI研究資源工作小組法案》。這個國家級AI研究雲的概念,最早由史丹佛大學人本AI中心的主任李飛飛在去年提出,她表示,國家級AI雲能提供研究員可負擔的運算成本,也能提供研究所需的大量資料集。為此,美國在6月也陸續啟動了討論會議,來探討如何建立、部署和治理這個國家AI研究雲。(詳全文)
圖片來源/Google、史丹佛大學、臉書、LFAI、TensorFlow
AI趨勢近期新聞
1. 臉書AI研究院聯手英美頂尖大學打造NetHack,專門來測試RL代理的穩健性
2. Google更新行動機器學習開發套件ML Kit,不再依賴Firebase雲端開發平臺
3. Honeywell最強量子電腦正式上線,將開放客戶使用
資料來源:iThome整理,2020年7月
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02