
百度開源LinearFold演算法,可大幅加快RNA病毒二級結構的預測時間,在實際應用上,從原本所需的55分鐘縮短為27秒。
重點新聞(0131~0206)
百度 RNA 武漢肺炎
百度開源RNA預測演算法,要助研發武漢肺炎疫苗
百度日前開源一套RNA結構預測演算法LinearFold,可大幅縮短RNA病毒二級結構的預測時間,讓第一線研究員可在短時間內了解病毒空間結構,加速疫苗研發。百度AI研究員指出,LinearFold已實際應用,可將原本55分鐘的預測時間,縮短為27秒。
RNA二級結構對病毒結構建模十分重要,可幫助研究員了解相關運作機制。不過,現有的動態規畫(Dynamic programming)演算法有個不足,也就是隨著RNA序列增加,所需的運算時間會以三次方增加,難以進行全基因體的應用。
對此,百度團隊釋出去年發表的RNA摺疊演算法LinearFold,來讓運算時間維持線性,且不必加諸任何限制,比如輸出結構的鹼基距離等。與其他演算法相比,LinearFold能由左至右掃描序列,而非上至下。團隊也以各種RNA序列資料集來測試LinearFold,發現準確度和所需時間皆比現有的演算法好,特別的是,LinearFold對長序列RNA的預測準確度特別高,比如16S或23S核糖體RNA。這對引起武漢肺炎、擁有3萬鹼基長序列的新型冠狀病毒來說,就有加速研究和研發疫苗的潛力。(詳全文)
Machine Unlearning 機器學習 SISA
就是要Machine Unlearning!多倫多大學發表SISA框架讓模型能忘記特定資訊
為滿足越來越嚴苛的資料隱私要求,多倫多大學聯合威斯康辛大學麥迪遜分校發表SISA訓練框架,能在移除資料點時,減少更新次數,來讓模型忘記(Unlearn)特定資訊。
團隊指出,要讓模型忘記特定知識,訓練點就必須做出零貢獻(Contribution),但由於這些資料點通常是互相交錯的,很難獨立刪除。而團隊提出的SISA訓練方法,能盡量不影響原有的工作流程,來進行訓練。在SISA訓練過程中,首先會將訓練資料分為數個分片(Shard),讓每個訓練點只涉及少數分片。接著,模型就在這些分片中,獨立訓練,減少資料點對模型的交互影響。最後,如果要模型忘記特定知識,就只有受到影響的模型會重新訓練,而非整體,因此也降低了重新訓練的時間。
後來,團隊利用兩套資料集來驗證SISA,發現在Purchase資料集上,光是分片訓練,就比從零開始重新訓練快上3.13倍。(詳全文)
.JPG)
Google 聊天機器人 Meena
號稱最先進!Google發表開放領域聊天機器人Meena
Google日前發表一款開放領域聊天機器人Meena,是一個擁有26億個參數的神經對話模型,能與人類進行各種主題的對話。Meena擁有一個編碼器模組和13個解碼器模塊,編碼器負責處理對話上下文,幫助Meena理解對話內容,而解碼器則使用編碼器處理過的資訊,產生實際回應。
團隊從公領域社交媒體對話中,過濾出341GB的文本來訓練模型。模型訓練的目標,是要最小化困惑(Perplexity)程度。訓練完後,團隊測試發現,Meena困惑度為10.2,人類評估指標SSA分數轉換為72%,比其他開放領域聊天機器人如Mitsuku、Cleverbot等,高出近20%。完整版本的Meena,甚至能將SSA分數提升為79%,與人類的86%分數相差不遠。(詳全文)
Google 資料集搜尋 表格
Google資料集搜尋引擎Dataset Search正式版出爐
Google去年發表的資料集搜尋引擎Dataset Search,現在終於推出正式版。目前Dataset Search已索引了全球網路上近2,500萬個資料集。根據Google的統計,現在Dataset Search所索引的資料集中,內容最多的類別為地球科學、生物學及農業;而最受出版商歡迎的資料集格式為表格,在2,500萬個資料集中,就有超過600萬個是表格;此外,絕大多數的政府都利用schema.org開放標準來描述這些資料集,而美國則是全球政府資料開放平臺中,貢獻最多資料集的政府,有超過200萬個資料集被Google索引。(詳全文)
IEEE 全球暖化 新氣候經濟
IEEE發表報告,呼籲工程師思考AI如何幫助解決全球暖化等難題
IEEE日前發表一份報告《衡量全球暖化與演算法進展的重要性》,呼籲各地工程師思考,如何藉新興科技解決全球暖化、兒童和社會層面等問題。該報告提出三個建議,包括:擁抱新氣候經濟並找出對地球友好的AI作法、保護兒童的未來與資料、尋求兼顧社會福祉的新成功指標。
報告也舉例說明,如國際組織Climate Change AI集結了學術界和業界的志願者,利用電腦視覺來降低電力系統的碳排放、改善交通車輛的能源使用,或是用來遠距監測農場的碳排放等。IEEE希望藉此,激發工程師的想法,來一起改善氣候問題。(詳全文)
Google AI工作流程框架 WebAssembly
Google推出網頁版跨平臺AI工作流程框架MediaPipe
Google近日將機器學習工作流程框架MediaPipe移植到了網頁平臺。MediaPipe可用圖(Graph)形式來建置和執行機器學習工作流程,原本只支援手機OS和邊緣裝置Google Coral。現在,Google利用WebAssembly技術和XNNPack機器學習預測函式庫,將MediaPipe帶上網頁瀏覽器,並能即時執行MediaPipe圖。Google也製作一個簡單的API,讓JavaScript和C++之間能進行通訊。不過,網頁版MediaPipe仍有限制,比如只能用模版圖(Template Graph)進行編輯。(詳全文)
英國 創新科技競賽 AI數據
首度在臺舉辦!英國創新科技競賽開跑,涵蓋AI、高齡科技和智慧交通
英國在臺辦事處日前舉辦首屆英國創新科技競賽,鎖定AI和數據、高齡社會科技、智慧交通等三大領域,要尋找臺灣成長型的新創。英國在臺辦事處指出,英國是歐洲最大的數據中心市場,占歐盟24%,也是許多AI企業的本營,希望藉這次競賽,選出表現亮眼的AI、雲端運算或數據分析新創。
這次競賽參賽資格為擁有2年以上商貿實績,在科技領域提供創新解決方案的新創。報名時間自2月5日起,至4月13日止。目前已有1,700家來自澳洲、印度、日本、紐西蘭和韓國的新創參加競賽,而優選的6家新創將獲資助,赴英國參加今年度的倫敦科技周。(詳全文)
IBM 影像自動標註 Cloud Annotations
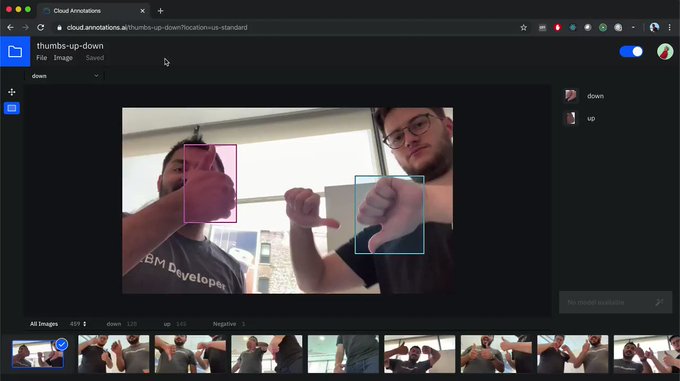
IBM釋出標註影像物件的自動化工具
IBM日前免費釋出自動化標註工具Cloud Annotations。這個工具,是用來加速AI專案中的影像標註過程,IBM指出,Cloud Annotations利用AI來替影像中的物件自動化標註,底層採用了IBM雲端物件儲存(Cloud Object Storage),可無限儲存用戶標註的影像,用戶也可從遠端任意存取,也能和多個協同開發者即時共享。Cloud Annotations目前為beta版,但已開放IBM Cloud用戶使用。(詳全文)
圖片來源/多倫多大學、Google、IBM
AI趨勢近期新聞
1. OpenAI採用PyTorch作為主要深度學習框架
2. GitHub以深度學習推薦簡單問題,幫助新手做出第一次貢獻
3. LinkedIn以機器學習偵測不適當的個人檔案內容
資料來源:iThome整理,2020年2月
熱門新聞

2026-03-06


2026-03-11

2026-03-12



2026-03-10