
臉書宣布開源深度學習框架PyTorch推出最新的1.3版本,添加了許多新的實驗性功能,開發者可以無縫地將模型部署到行動裝置上,同時也增加了模型量化(Quantization)功能,以提升模型預測效能,並且還新增像是命名張量(Name Tensor)功能改進前端,開發者可以編寫邏輯更清楚的程式碼,不需要依靠內聯註解說明。
PyTorch 1.3擴展對行動裝置的支援,提供了把Python部署到iOS和Android裝置的端到端工作流。臉書提到,應用程式要求越來越低的延遲,因此在邊緣裝置上執行機器學習的重要性也隨之提高,現在加入的這個部署工作流程還是一個早期實驗版本,對模型的大小進行了最佳化,系統會根據用戶應用程式需要的運算子,來決定模型最佳化的程度,以及選擇編譯的相依項目。
在效能改善上,也擴大行動裝置CPU和GPU的支援程度,同時也提供了高階API,擴充行動原生API,涵蓋開發行動裝置機器學習應用程式,所需要的一般預處理和整合任務,開發者能夠更容易地在行動裝置上發展電腦視覺以及NLP應用。
臉書提到,開發機器學習應用程式,應該要有效的利用伺服器或是裝置上的計算資源,特別是在資源受限的行動裝置上,因此PyTorch 1.3現在開始支援8位元模型量化。量化是用來降低計算和儲存精準度的技術,目前PyTorch支援的模型量化,包括動態量化以及量化感知訓練。
在深度學習中使用的傳統張量存在重大的設計缺陷,康乃爾大學助理教授Sasha Rush提到,傳統張量會暴露隱私維度,還會基於絕對位置進行廣播,或是將類型資訊儲存在文件中,因此經Sasha Rush的建議,PyTorch 1.3加入了實驗性命名張量功能,以克服這些隱私問題。
PyTorch 1.3也加入了隱私觀察工具CrypTen,臉書提到,雲端或是機器學習即服務平臺面臨了一系列安全和隱私的威脅,特別是平臺的用戶,可能不希望或是無法共享加密資料,而這使得機器學習工具的功能受限,為了解決這個問題,機器學習社群又發展了各種技術來解決問題,而為了理解這些技術,臉書發布了CrypTen研究平臺,以推動機器學習領域的隱私保護研究。
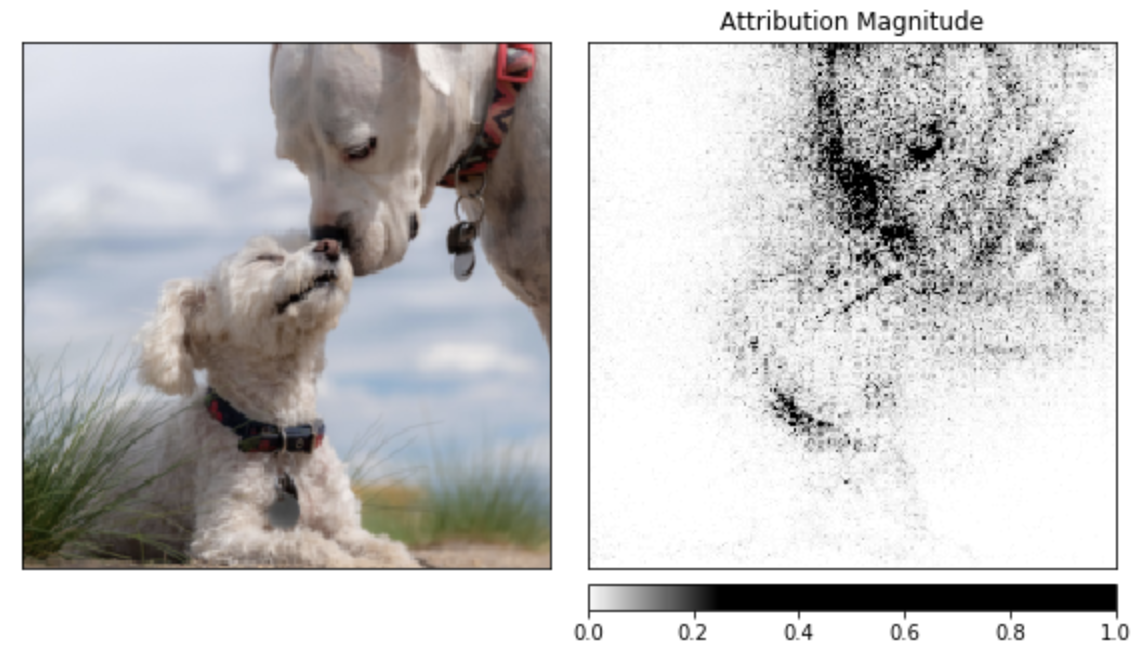
新加入的工具還包括了稱為Captum的模型解釋工具(下圖),PyTorch開發團隊提到,隨著模型越來越複雜,模型的可解釋性需求也變得重要,Captum可以幫助PyTorch的開發人員了解模型的特定輸出,該工具提供了先進的方法,幫助開發者了解特定神經元和層(Layer)的重要性,以及對模型預測產生的影響。
臉書人工智慧研究院也為PyTorch發布了物件偵測函式庫Detectron2,開發者可以使用Detectron2,以幫助電腦視覺的研究。在雲端方面,臉書與Google和Salesforce合作,為雲端TPU(Tensor Processing Units)提供支援,提升訓練大型深度神經網路的速度。除了雲端平臺AWS、Azure和GCP,阿里巴巴也加入PyTorch的支援。
PyTorch的社群相當活躍,其大量的貢獻者為PyTorch提供充足的動能發展新功能,在去年貢獻者成長超過50%,來自臉書、微軟、Uber和其他組織的貢獻者數量,目前已經接近1,200位,在論文預印本開放資料庫arXiv上,PyTorch引用在2019年上半年成長194%。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-03

2026-03-02