微軟在自家無程式碼ETL服務Azure Data Factory上,正式推出Mapping Data Flows功能,供使用者大規模且快速地轉換資料,微軟提到,Mapping Data Flows是一項變革性的資料整合以及轉換服務。
Azure Data Factory是一個無伺服器服務,使用者不需要管理基礎設施,就能夠在雲端進行ETL工作,處理任何規模的資料。而Mapping Data Flows則是專為應對龐大資料處理的複雜性和規模而生的功能,使用者可以直接在瀏覽器中,存取視覺化的環境,建構彈性資料工作管線,並由Azure Data Factory來處理Spark運作的複雜作業。
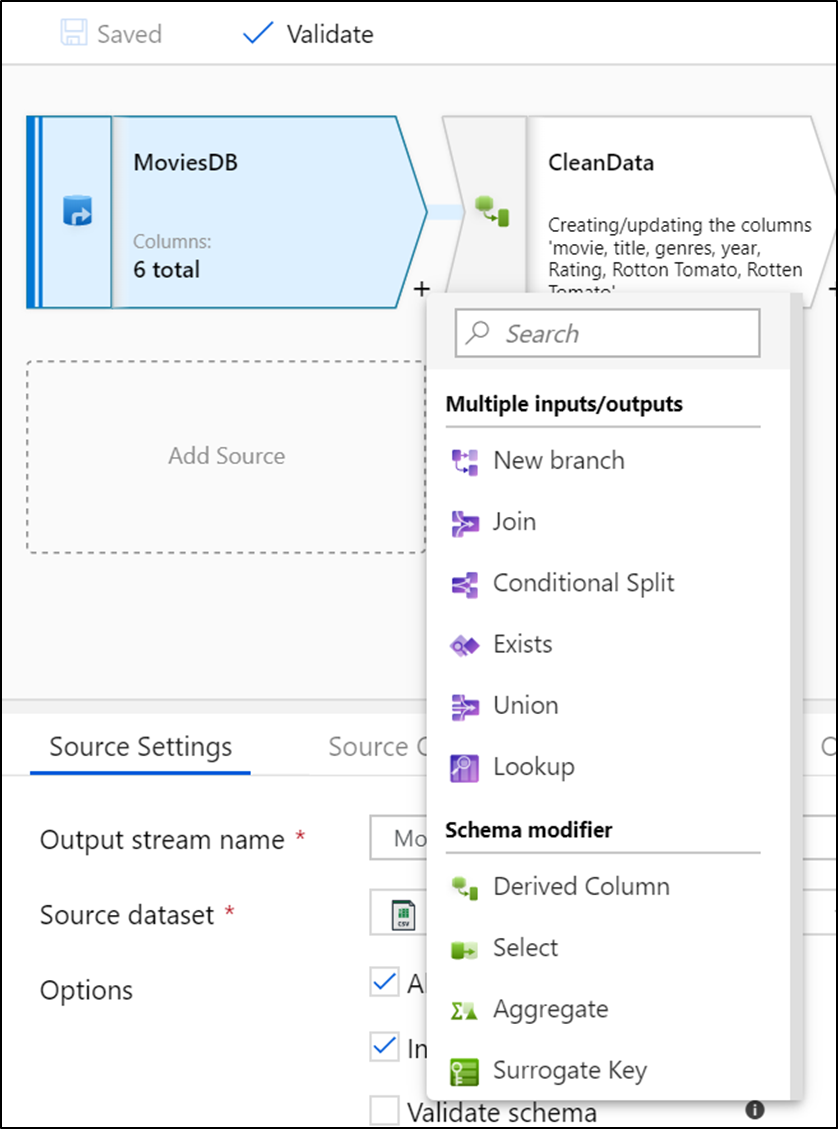
Mapping Data Flows提供內建功能來處理不可預測的資料架構後,並維持變更輸入資料的彈性,簡化使用者資料處理的工作,讓使用者可以專注於建構業務資料邏輯,不需要花費時間管理伺服器叢集或是撰寫程式碼,快速地進行載入事實表格(Fact Table)、維持緩慢的維度變換(Slowly Changing Dimension,SCD)、聚合半結構化的資料,以及使用模糊匹配來配對資料,為建模做準備。
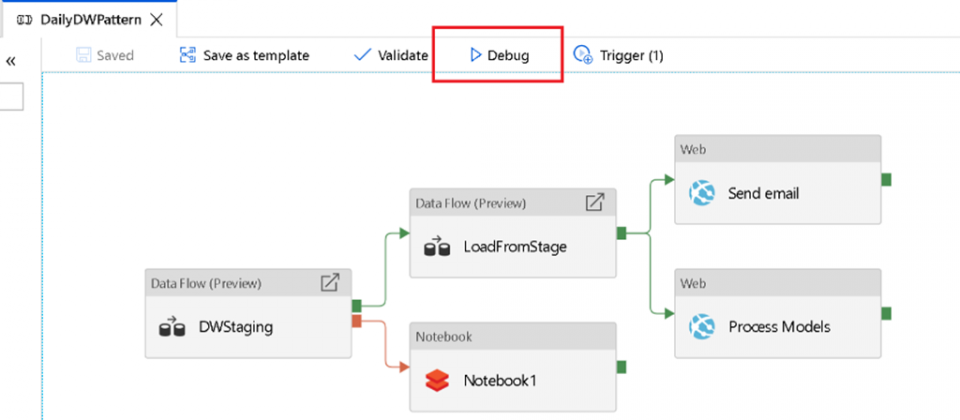
其提供直覺的視覺化介面,可以將使用者的資料邏輯轉換成為易讀的圖(Graph),並建置轉換程式函式庫,分析原始資料產出業務可用的結果(下圖)。當然,使用者也可以不使用Mapping Data Flows的無程式碼介面,自己撰寫程式碼呼叫內建的轉換功能,執行連接(Join)、聚合、樞紐分析(Pivot)以及排序等常見操作。
工作管線建置器可讓使用者透過滑鼠拖拉操作,來建置工作管線,或是以互動的形式為端到端ETL程序除錯,使用者可以為工作管線建置排程,並從Azure Data Factory監控入口網站監控資料流執行,透過Azure Data Factory提供多種可用性監控以及警示功能,來管理資料的可用SLA,還能利用內建的CI/CD,在託管的DataOps環境中儲存與管理資料流,透過建立警示和瀏覽執行計畫,就能驗證使用者的邏輯是否如計畫一樣處理資料流。
熱門新聞

2026-03-06




2026-03-06

2026-03-09

2026-03-09

2026-03-09