AWS在去年re:Invent 2018大會上介紹的資料湖管理工具AWS Lake Formation,現在推出正式版,用戶可以使用AWS Lake Formation對資料進行擷取、清理、分類、轉換以及保護的工作,方便後續分析或是機器學習使用。
AWS提到,只要企業開始使用數位格式的資料,那就可能需要建立一個資料倉儲,從CRM或是ERP等營運系統收集資料,並給其他決策支援系統使用,這些資料包括未組織的原始資料、日誌、圖片、影片或是掃描的文件等,而這也是資料湖的概念,將所有資料以各種規模與形式,儲存在中央儲存庫中。
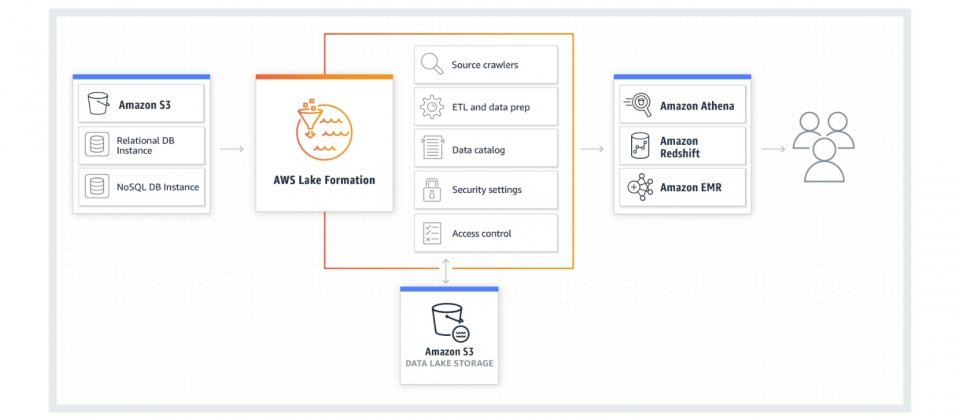
而AWS新推出的資料湖服務Lake Formation,能簡化資料湖的管理工作,用戶可以使用中央控制臺,處理建置和配置資料湖繁雜的工作,包括載入不同來源的資料、監控資料流、設定資料分區、加密和管理金鑰,以及格式轉換與監控營運等工作。
只要在Lake Formation中指定資料來源,系統就會自動從資料庫和物件儲存擷取資料,並將這些資料儲存到Amazon S3資料湖中,以適當的大小與方式整理,增加存取效能,並以機器學習演算法清理和分類資料,為敏感資料提供存取保護。
用戶還可以使用Glue ML Transforms刪除資料湖中重複的資料,提高後續分析資料的效率,避免因為重複的資料,造成分析工作的混淆。AWS提到,這項工作並非單純透過鍵值比對,就能找出重複的資料,很多情況需要進行模糊比對,像是當用戶需要在不同表格查詢類似的項目時,就需要使用模糊連接(Fuzzy Join),在不共用唯一鍵值的兩個資料庫表格查詢相似資料。
在保護資料存取方面,用戶可以在Lake Formation中,定義精細的存取政策,保護Glue Data Catalog中的元資料,以及儲存在Amazon S3的資料,AWS提到,在資料湖中管理存取權限是一件複雜的任務,因為資料的各種特性,包括結構化與否、敏感性或是可存取的資料範圍不一,而Lake Formation賦予用戶以IAM使用者、角色、群組和AD來管理資料存取,也能夠拒絕表格特定的欄位被存取。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09


2026-03-09