
ezLabel平臺可以讓用戶選擇欲標記物件的類別後,用方框框出目標物第一次、最後一次出現在畫面中的位置,再點擊執行,系統就會在影片中自動標出目標物件。
圖/魁達智慧提供
今年COMPUTEX活動上,魁達智慧(creDa)展出了今年1月正式上線的動態影像標記平臺「ezLabel」,只要上傳影片至平臺,並針對目標物件第一次、最後一次出現的畫面進行標註,就能透過演算法自動標記出影片中的目標物件,可以比傳統標記方式快15倍。而在4月9號改版後,除了介面中可支援的物件標記新增到1026種,也加入了標記行為的功能,可針對同一區段的多種行為重複標記。
一般在標記動態影像時,會需要在一幀一幀的靜態畫面中標出目標物件,若以一秒24幀來算,每十幀標記一次,在一秒內就需要標記2-3次,時常耗費大量時間來標記影像。為了縮短標註時間,魁達推出ezLabel動態影像標記平臺,使用者只需上傳影片至平臺,先行用方框框出目標物第一次、最後一次出現在畫面中的位置,再點擊執行,系統就會透過深度學習提取畫面特徵值並與影片比對,再自動標出目標物件。
雖然平臺沒有限制影片上傳長度,但魁達智慧執行長沈柏均也提醒,影像在平臺上播放與標記時,會占用個人電腦的暫存記憶體,記憶體要夠大才能處理更長時間的影像,因此會建議影片長度以五分鐘為限。
沈柏均也表示,現行的演算法仍無法適用於所有物件的標記。經開發團隊測試後,確定可被自動化標記的物件共有1026項,包括常見的汽機車、行人,或是水中生物等,均已內建於平臺介面中,但如果用戶在介面中找不到欲標註的物件,可以利用自定義的功能新增項目來測試,仍然可能適用於自動化標註。
「全自動的演算法沒有到完美,可是可以比過去快15倍。」沈柏均表示,能否被自動標註也取決於影像的複雜度,例如在大量機車停等紅燈的場景中,目標機車就不容易被辨識,因此,在系統自動化標註完成後,需要人工複查,重新將錯誤標記的部份更正,但即便如此,整個標記流程還是能比傳統方式快15倍。
.png)
ezLabel平臺提供用戶自行創建任務的功能,並可以選擇欲標記物項的種類(Category)、型式(Type)、特徵(Attribute)。
.png)
若介面中找不到欲標註的物件,可以利用自定義的功能新增項目來測試。
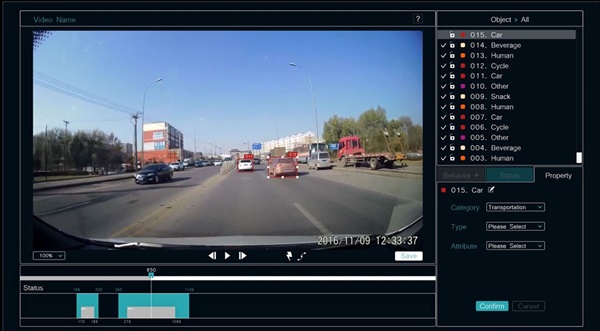
接下來就可以在影片的畫面中標記出目標物,再透過演算法自動標註。
今年4月9號改版後ezLabel新增了標記行為的功能,沈柏均表示,許多開源軟體提供標記行為的方式,是用單張靜態畫面去標註,但行為應該是連續性的動作。因此,ezLabel讓使用者在區段中標記行為,例如「走路」這個行為,可以用十幀畫面中、被標註的人的動作變化來定義。此外,在區段中也可重複標記不同的行為,例如一個人一邊走路一邊撐傘,就能在區段中同時標記「走路」與「撐傘」的行為。
ezLabel註冊帳號後就可以使用,學生用戶比例較高,在標記完成後,ezLabel也提供兩種常見的下載格式,分別是PASCAL VOC、JSON,能直接用於AI模型的訓練。未來,魁達也希望能將標記完的資料直接串接雲端,能讓用戶能更便利運用資料來訓練模型,省去資料被下載、再上傳雲端的程序。
熱門新聞

2026-03-06


2026-03-11

2026-03-12



2026-03-10